
NTTドコモは4月17日、「ドコモメール」でデータベースシステムに不備があり、ユーザーが「保護」設定したメールの一部が特定の条件下で削除される不具合が発生していたと発表した。メールの復元を試みたが、不可能だったという。
ドコモメールで「保護」したメールが勝手に削除される不具合 12年間で約32万人に影響 「復元は困難」 - ITmedia NEWS
特定の条件とは、メール総数が2万通を超える状態になったことがあり、迷惑メールフォルダとメールの保護機能を使用していたこと。2013年12月17日から25年3月21日まで、12年にわたり不具合が発生していた。
ドコモメールで「保護」したメールが勝手に削除される不具合 12年間で約32万人に影響 「復元は困難」 - ITmedia NEWS
原因はメールの自動削除処理に関するプログラムだった。削除されたメールの復元を試みたものの、原本となるメールデータがサーバから消去されており、復元は不可能だったという。
ドコモメールで「保護」したメールが勝手に削除される不具合 12年間で約32万人に影響 「復元は困難」 - ITmedia NEWS
⇧ 不具合ではないのでは...
普通に考えて、リソースは有限なのだから、いつまでも保存しておくなんて無理ですし、「自動削除処理」を行うこと自体は間違っていないと思うのだが...
仕様書に記載の要件と実際のプログラムの挙動に乖離があったというのなら改善が必要とは思うのが...
そして、
米国の匿名画像掲示板「4chan」がダウンしている。別の掲示板では4chanから流出させたとする情報が大量に暴露され、何者かが4chanをハッキングしたとの見方が強まっている。
米匿名画像掲示板「4chan」がダウン、何者かがハッキングした可能性 内部情報や個人情報なども漏えいか:この頃、セキュリティ界隈で - ITmedia NEWS
4chanはメディアの取材に応じておらず、こうした情報が本物なのかも、ハッキングされた経緯についても現時点では確認できていない。ただ、古いバージョンのPHPが悪用されたとの見方もある。「4chanがハッキングされたのは、脆弱性だらけのものすごく古いバージョンのPHPを実行して、非推奨の関数を使ってMySQLデータベースとやりとりしていたから」というXの書き込みもあった。
米匿名画像掲示板「4chan」がダウン、何者かがハッキングした可能性 内部情報や個人情報なども漏えいか:この頃、セキュリティ界隈で - ITmedia NEWS
⇧ まぁ、ビジネスを優先させて開発を進めたであろう皺寄せが保守・運用に行っていると思われるが、開発の難しさを物語っていますな...
「リファクタリング」が後回しにされ続けていたのだとは思うのだが、既に手の施しようが無い段階になってしまっていなければ良いのだが...
Excel の列の値で日本語名の値をアンダースコア区切りの英語名の値に変換したい
予算の兼ね合いなどもあり、システム化が承認されなかったりなど、何だかんだで、脱Excelファイルを避けて通ることが難しい状況は少なくないように思うのだが、ライブラリとかでExcelファイルがサポートされていることは稀な気がする。
「Ansible」とかもExcelファイルからデータを読み込むような「モジュール」は用意されていませんし...
とは言え、Excelファイルのデータを「RDBMS(Relational DataBase Management System)」とかで管理しようにも、テーブル設計とか必要になって来るので、「RDBMS(Relational DataBase Management System)」導入されるまでは、Excelファイルをプログラミング言語経由で読み込む必要が出てきますと。
要するに、
Excelファイル → YAMLファイル
に変換したいのだが、それ以前に、
日本語名 → アンダースコア区切りの英語名
⇧ を実施する必要がある。
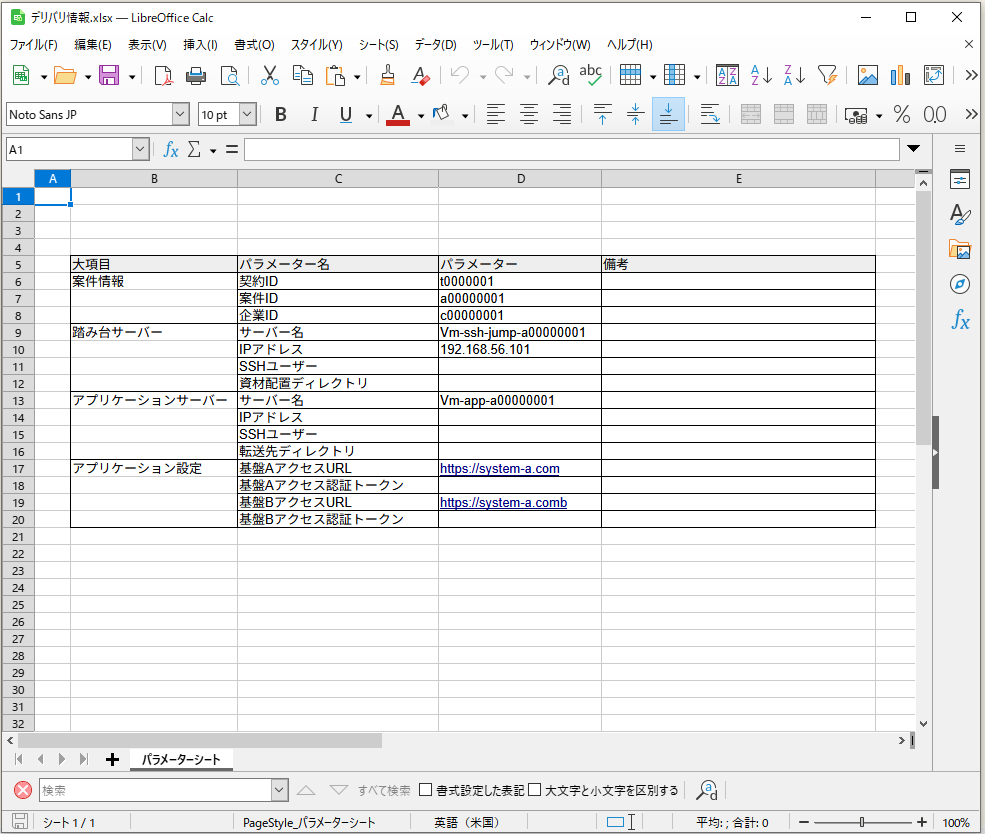
インプットのExcelのイメージとしては、

⇧ 上図の赤枠の部分を先ずはアンダースコア区切りの英語名にしたいということですね。
日本語から英語に翻訳させる必要があることから「機械学習」系のライブラリが必要になってきそうではある。
上手いこと翻訳してくれるかが分からないですが...
ChatGPT氏に質問したところ、以下の回答が返ってきた。
import pandas as pd
from deep_translator import GoogleTranslator
import inflection
def convert_and_export_excel_headers(input_file, output_file):
# 元のExcelファイル読み込み
df = pd.read_excel(input_file, sheet_name='データ') # シート名は必要に応じて変更
# 列名取得
original_columns = df.columns.tolist()
# 日本語 → 英語 に翻訳
translated_columns = [GoogleTranslator(source='auto', target='en').translate(col) for col in original_columns]
# スネークケース変換
snake_case_columns = [inflection.underscore(col).lower() for col in translated_columns]
# 変換マップをDataFrameにする
result_df = pd.DataFrame({
"元の列名": original_columns,
"英訳": translated_columns,
"スネークケース": snake_case_columns
})
# 新しいExcelファイルに書き出す(元のデータと変換結果両方を含む)
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='データ', index=False) # 元のデータ
result_df.to_excel(writer, sheet_name='変換結果', index=False) # 別シートに変換結果
⇧「deep_translator」なるライブラリを利用しているらしい。
ネットの情報を漁っていたところ、

⇧ 上記サイト様が情報をまとめてくださっていました。
ただ、
A flexible free and unlimited python tool to translate between different languages in a simple way using multiple translators.
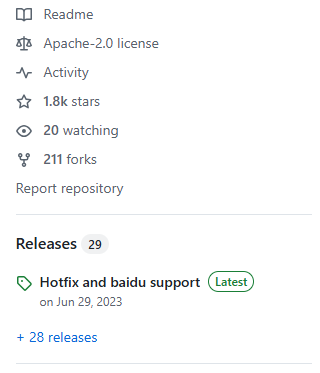
⇧ 最終リリースが「2023年6月29日」というのが気になりますな...
試してみますか。
Python仮想環境を構築。
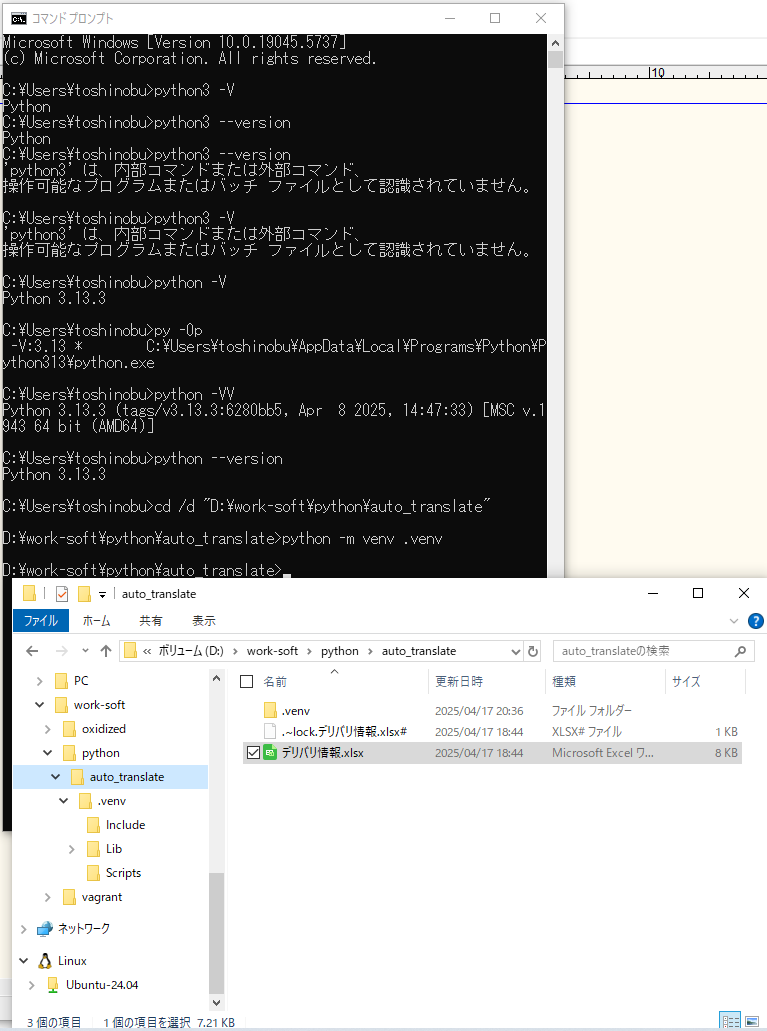
Python仮想環境にログインします。
必要なライブラリをインストール
pip install pandas deep-translator inflection openpyxl
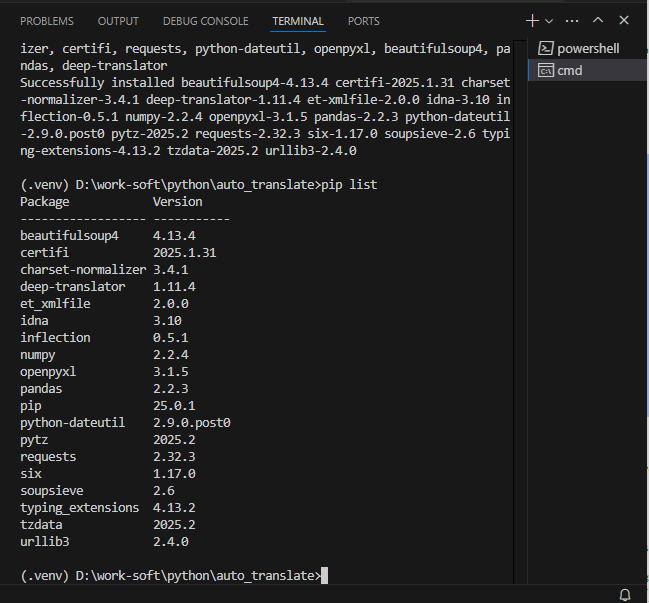
(.venv) D:\work-soft\python\auto_translate>pip list Package Version ------------------ ----------- beautifulsoup4 4.13.4 certifi 2025.1.31 charset-normalizer 3.4.1 deep-translator 1.11.4 et_xmlfile 2.0.0 idna 3.10 inflection 0.5.1 numpy 2.2.4 openpyxl 3.1.5 pandas 2.2.3 pip 25.0.1 python-dateutil 2.9.0.post0 pytz 2025.2 requests 2.32.3 six 1.17.0 soupsieve 2.6 typing_extensions 4.13.2 tzdata 2025.2 urllib3 2.4.0
⇧ とりあえず、諸々、インストールできた模様。
ExcelファイルとPythonのスクリプトファイルを用意。
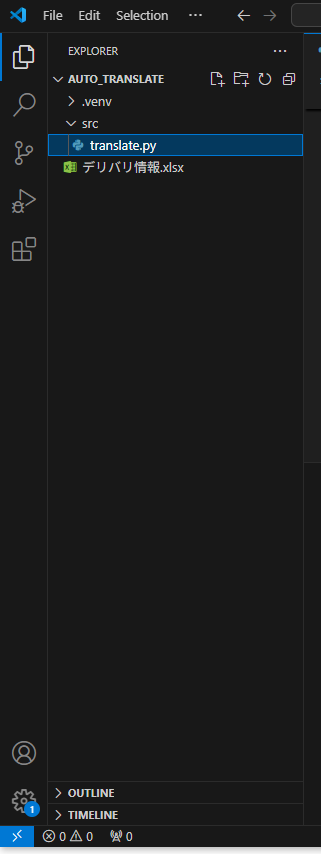
Excelファイルと言いつつ、実際は、無料で利用できるLibre Office Calcですが...
以下のようなソースコード。
■D:\work-soft\python\auto_translate\src\translate.py
import pandas as pd
from deep_translator import GoogleTranslator
import inflection
import os
import pprint
def convert_and_export_excel_headers(input_file, output_file):
# 元のExcelファイル読み込み
df = pd.read_excel(input_file, sheet_name='パラメーターシート', header=0, skiprows=4) # シート名は必要に応じて変更
# 3列目のみ取得(インデックス2が3列目)
third_column = df.iloc[:, 2]
# セルが空でない部分のみ翻訳
translated_third_column = [
GoogleTranslator(source='auto', target='en').translate(cell) if pd.notna(cell) else cell
for cell in third_column
]
pprint.pprint(translated_third_column) # 翻訳された3列目の内容を表示
# スネークケース変換(翻訳された3列目のデータ)
snake_case_translated_third_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else cell
for cell in translated_third_column
]
pprint.pprint(snake_case_translated_third_column) # スネークケースに変換された3列目を表示
# スネークケースに変換されたデータを元のDataFrameの3列目に戻す
df.iloc[:, 2] = snake_case_translated_third_column
# 新しいExcelファイルに書き出す(元のデータと変換結果両方を含む)
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='パラメーターシート', index=False) # 元のデータ(3列目だけ翻訳&スネークケース済み)
# メソッドの呼び出し部分
if __name__ == "__main__":
# 入力ファイルのパスと出力ファイルのパスを指定
input_file = r'D:\work-soft\python\auto_translate\デリバリ情報.xlsx' # 実際の入力ファイルのパスに変更
output_file = r'D:\work-soft\python\auto_translate\【Done】デリバリ情報.xlsx' # 出力ファイルのパスに変更
# ファイルが存在するか確認
if not os.path.exists(input_file):
print(f"入力ファイル '{input_file}' が存在しません。")
else:
# メソッドを呼び出して処理を実行
convert_and_export_excel_headers(input_file, output_file)
print(f"変換結果を '{output_file}' に書き出しました。")
⇧
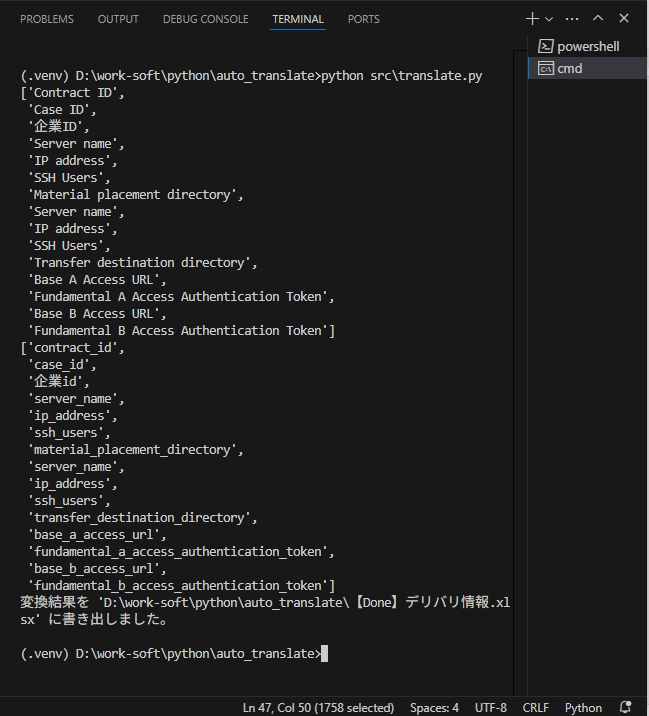
アウトプットされています。
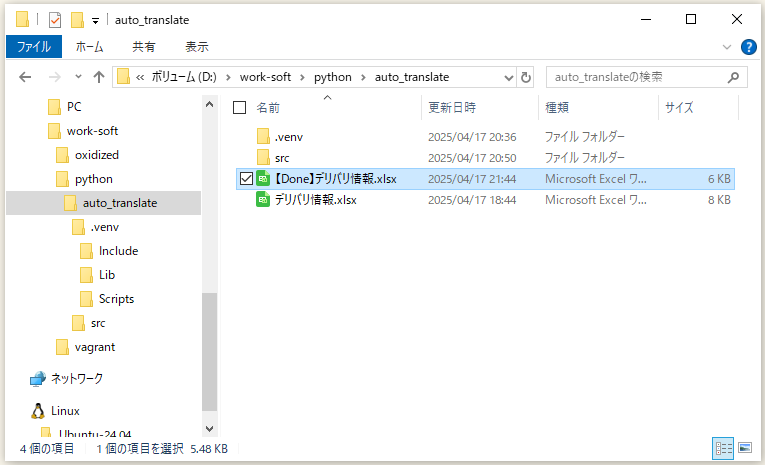
アウトプットのファイルを開いて確認してみると、
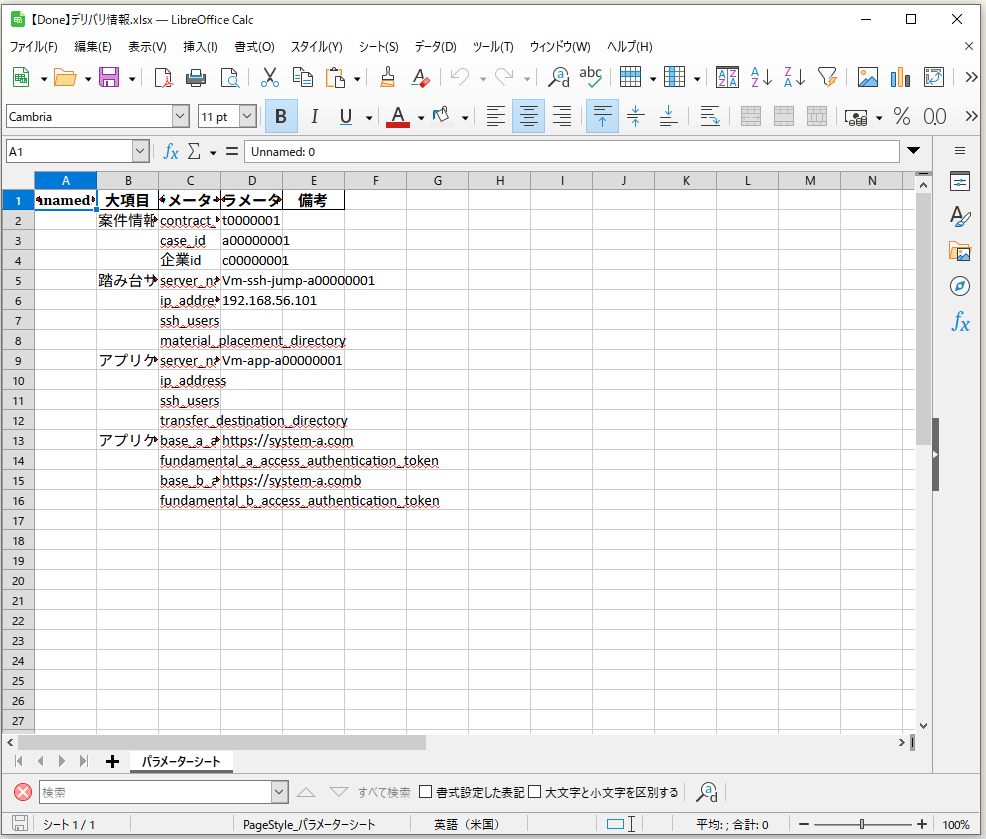
一応、アンダースコア区切りの英語名になったのだが、何故か「企業」だけ英語になっていない...
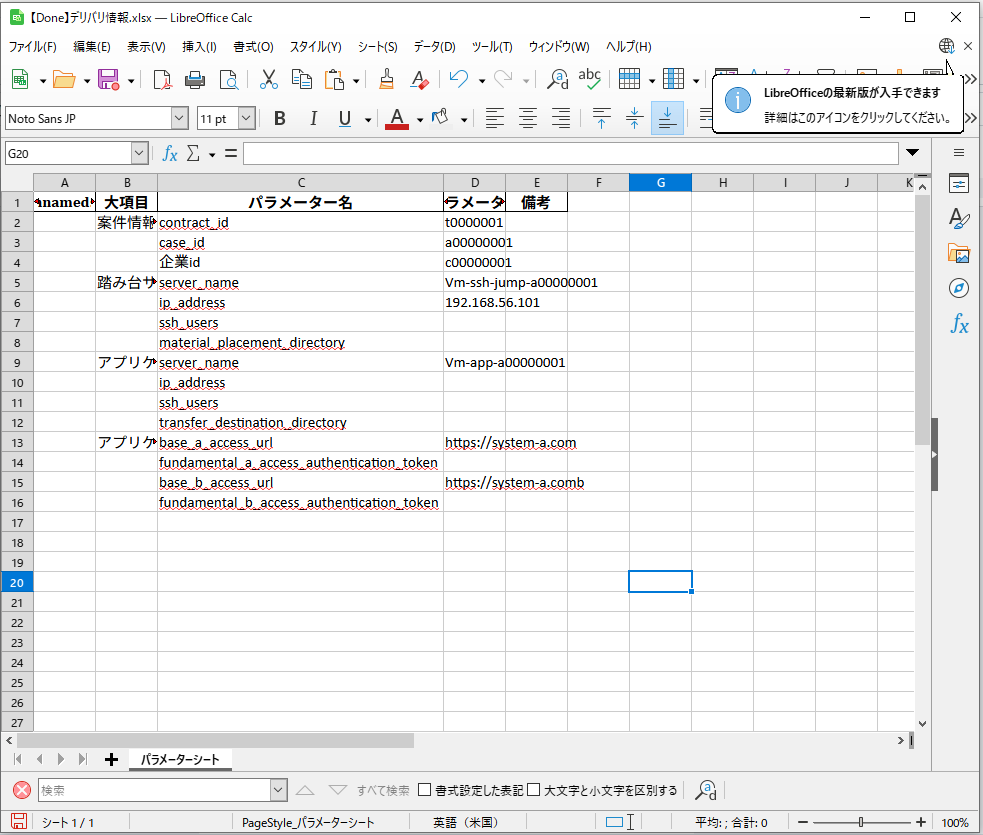
う~む、完全な翻訳は厳しい感じですかね...
英語圏以外の言語は、本質的な部分以外のエンジニアリングで余計な労力が必要になってくるのよね...
後は、「パラメーター名」だけだと名前が重複して一意にできないので、「大項目」も英語名に変換する必要がありますな...
後は、YAMLのフォーマットに整形する必要があると...
スマートにはいかないものですな...
毎度モヤモヤ感が半端ない…
今回はこのへんで。