
⇧ 250年って数字はどこから出てきたのか謎ですが、身体機能を保ったまま寿命を延ばせるとなった時代が到来した世界線で、定年が更に引き延ばされそうな暗い未来しか想像できない...
いまの人生100年時代の定年が65歳とした場合、人生の65%を労働しなければならないので、人生250年時代で同様の定年の割合だった場合、250年×65%の結果はと言うと、162.5になるので、162年6ヶ月を労働に費やすのかね?
ホラーですな...
不老を目指してくれるのはありがたいのですが、人類が働かなくて良い世界を実現して欲しいものですな...
寿命が延びた場合に、食糧問題とかエネルギー問題とか、別の問題が退っ引きならない状況になりそうですし、課題を解決すると別のところが問題になる、まさにシステムのバグと似てますな。
Linuxのcolumnコマンドとは?
columnコマンドのマニュアルページの内容を確認すると、
COLUMN(1) User Commands COLUMN(1)
NAME
column - columnate lists
SYNOPSIS
column [options] [file ...]
DESCRIPTION
The column utility formats its input into multiple columns. The util
support three modes:
columns are filled before rows
This is the default mode (required by backward compatibility).
rows are filled before columns
This mode is enabled by option -x, --fillrows
table
Determine the number of columns the input contains and create a
table. This mode is enabled by option -t, --table and columns
formatting is possible to modify by --table-* options. Use this
mode if not sure.
Input is taken from file, or otherwise from standard input. Empty lines
are ignored and all invalid multibyte sequences are encoded by x<hex>
convention.
OPTIONS
The argument columns for --table-* options is a comma separated list of
the column names as defined by --table-columns or it’s column number in
order as specified by input. It’s possible to mix names and numbers.
The special placeholder '0' (e.g. -R0) may be used to specify all
columns.
-J, --json
Use JSON output format to print the table, the option
--table-columns is required and the option --table-name is
recommended.
-c, --output-width width
Output is formatted to a width specified as number of characters.
The original name of this option is --columns; this name is
deprecated since v2.30. Note that input longer than width is not
truncated by default.
-d, --table-noheadings
Do not print header. This option allows the use of logical column
names on the command line, but keeps the header hidden when
printing the table.
-o, --output-separator string
Specify the columns delimiter for table output (default is two
spaces).
-s, --separator separators
Specify the possible input item delimiters (default is whitespace).
-t, --table
Determine the number of columns the input contains and create a
table. Columns are delimited with whitespace, by default, or with
the characters supplied using the --output-separator option. Table
output is useful for pretty-printing.
-N, --table-columns names
Specify the columns names by comma separated list of names. The
names are used for the table header or to address column in option
arguments.
-l, --table-columns-limit number
Specify maximal number of the input columns. The last column will
contain all remaining line data if the limit is smaller than the
number of the columns in the input data.
-R, --table-right columns
Right align text in the specified columns.
-T, --table-truncate columns
Specify columns where text can be truncated when necessary,
otherwise very long table entries may be printed on multiple lines.
-E, --table-noextreme columns
Specify columns where is possible to ignore unusually long (longer
than average) cells when calculate column width. The option has
impact to the width calculation and table formatting, but the
printed text is not affected.
The option is used for the last visible column by default.
-e, --table-header-repeat
Print header line for each page.
-W, --table-wrap columns
Specify columns where is possible to use multi-line cell for long
text when necessary.
-H, --table-hide columns
Don’t print specified columns. The special placeholder '-' may be
used to hide all unnamed columns (see --table-columns).
-O, --table-order columns
Specify columns order on output.
-n, --table-name name
Specify the table name used for JSON output. The default is
"table".
-L, --keep-empty-lines
Preserve whitespace-only lines in the input. The default is ignore
empty lines at all. This option’s original name was
--table-empty-lines but is now deprecated because it gives the
false impression that the option only applies to table mode.
-r, --tree column
Specify column to use tree-like output. Note that the circular
dependencies and other anomalies in child and parent relation are
silently ignored.
-i, --tree-id column
Specify column with line ID to create child-parent relation.
-p, --tree-parent column
Specify column with parent ID to create child-parent relation.
-x, --fillrows
Fill rows before filling columns.
-V, --version
Display version information and exit.
-h, --help
Display help text and exit.
ENVIRONMENT
The environment variable COLUMNS is used to determine the size of the
screen if no other information is available.
HISTORY
The column command appeared in 4.3BSD-Reno.
BUGS
Version 2.23 changed the -s option to be non-greedy, for example:
printf "a:b:c\n1::3\n" | column -t -s ':'
Old output:
a b c
1 3
New output (since util-linux 2.23):
a b c
1 3
Historical versions of this tool indicated that "rows are filled before
columns" by default, and that the -x option reverses this. This wording
did not reflect the actual behavior, and it has since been corrected
(see above). Other implementations of column may continue to use the
older documentation, but the behavior should be identical in any case.
EXAMPLES
Print fstab with header line and align number to the right:
sed 's/#.*//' /etc/fstab | column --table --table-columns SOURCE,TARGET,TYPE,OPTIONS,PASS,FREQ --table-right PASS,FREQ
Print fstab and hide unnamed columns:
sed 's/#.*//' /etc/fstab | column --table --table-columns SOURCE,TARGET,TYPE --table-hide -
Print a tree:
echo -e '1 0 A\n2 1 AA\n3 1 AB\n4 2 AAA\n5 2 AAB' | column --tree-id 1 --tree-parent 2 --tree 3
1 0 A
2 1 |-AA
4 2 | |-AAA
5 2 | `-AAB
3 1 `-AB
SEE ALSO
colrm(1), ls(1), paste(1), sort(1)
REPORTING BUGS
For bug reports, use the issue tracker at
https://github.com/karelzak/util-linux/issues.
AVAILABILITY
The column command is part of the util-linux package which can be
downloaded from Linux Kernel Archive
<https://www.kernel.org/pub/linux/utils/util-linux/>.
util-linux 2.37.2 2021-06-02 COLUMN(1)
⇧ 説明によると、「-t」オプションで出力をテーブルっぽく整形してくれるってことみたい。
イメージ的には、
テーブル(英: table)または表は、ビジュアルコミュニケーションの一形態であり、データを並べる手段である。テーブルはコミュニケーション、研究、データ解析など様々な分野で使われている。
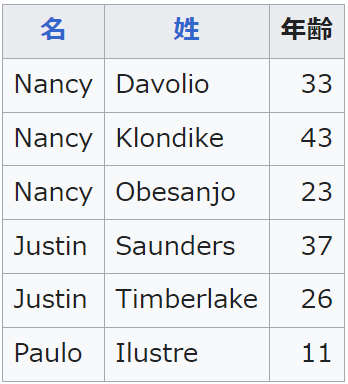
⇧ 見たいな感じで、列(カラム)を整列してくれるような感じなんかな。
Linuxのcolumnコマンドを使う時の区切り文字はカンマにするのが良さ気
で、区切り文字を指定できるらしいのですが、区切り文字としては「,(カンマ)」にしておいた方が無難そうな気がする。
少なくとも、「\t(タブ)」は、表示が崩れてしまったので。
というわけで、試してみました。
動作確認の環境は、「WSL 2(Windows Subsystem for Linux 2)」の「Ubuntu 22.04.2 LTS (GNU/Linux 5.15.133.1-microsoft-standard-WSL2 x86_64)」
■/home/ts0818/work/test_format/test_format.sh
#!bin/bash
# 対象のディレクトリ
WORK_DIR=/home/ts0818/work/test_format/data
header=""
body=""
LF=$'\n'
# CSVファイルの数だけ繰り返し
for file in $(find ${WORK_DIR} -type f -name '*.csv');
do
# 区切り文字をタブ
# header+='\t'"$(basename $file .csv)"
# body+='\t'"$(cat $file | wc -l)"
# 区切り文字をカンマ
header+=','"$(basename $file .csv)"
body+=','"$(cat $file | wc -l)"
done
DATE_TIME=$(date +"%F %T")
header="DATE_TIME${header}"
body="${DATE_TIME}${body}"
# テーブルっぽく出力
echo -e "${header}${LF}${body}" | column -t -s , | tee -a result.text
⇧ で、実行してみる。
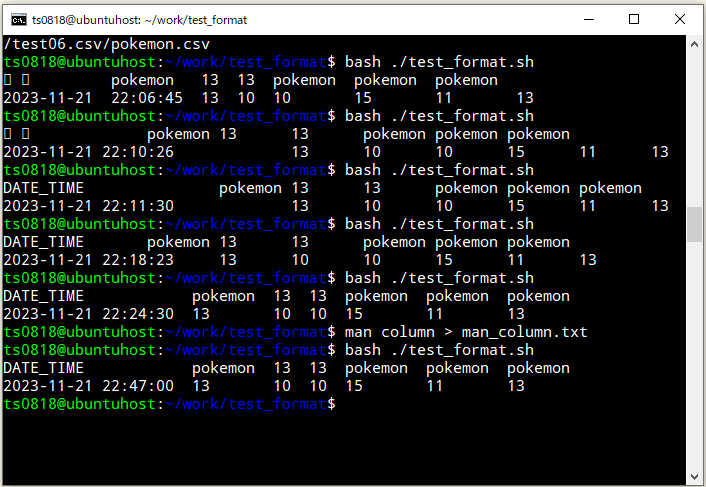

⇧ タブ区切りは崩れてしまっていますが、カンマ区切りの場合は、整形が上手くいっています。
CSVファイル名を少し長めにリネームして、試してみました。
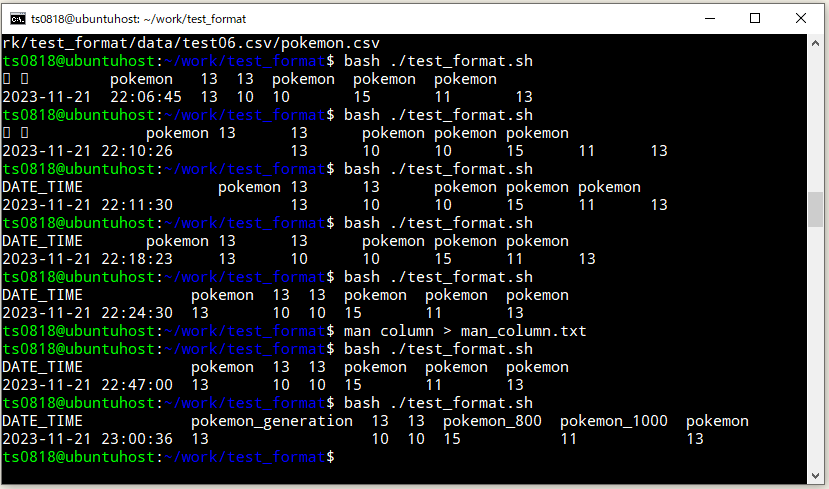
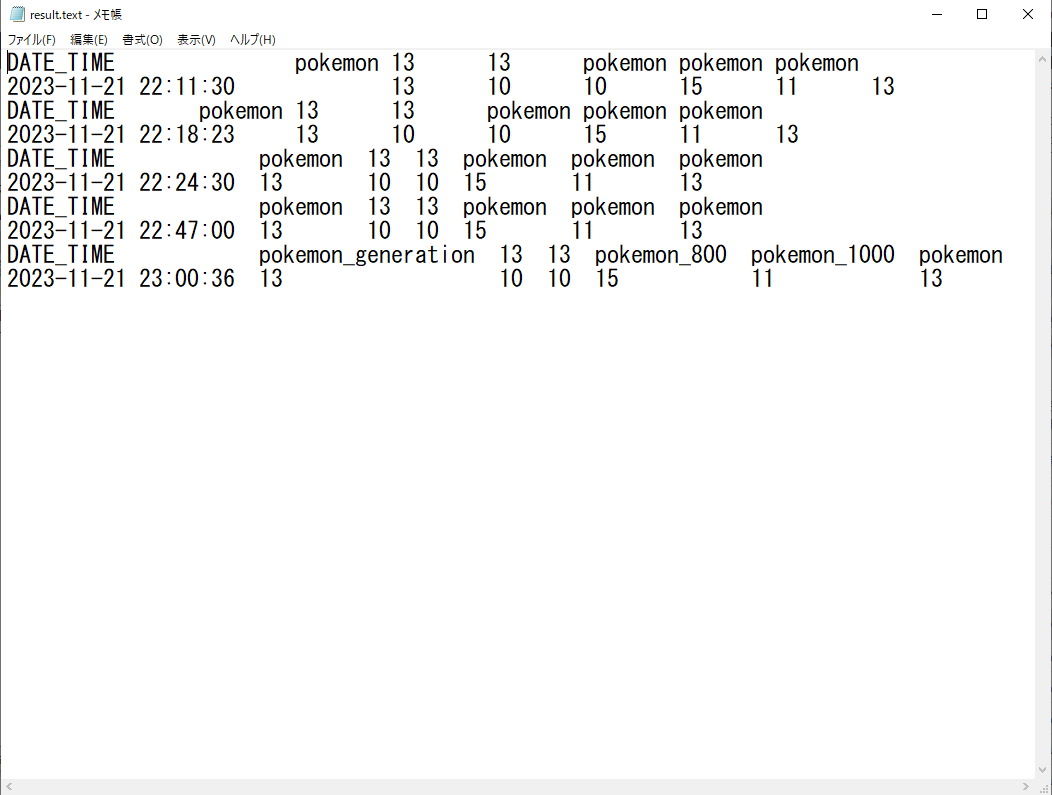
⇧ ある程度は、テーブルのフォーマットを保てそうです。
ただ、
⇧ 上記サイト様によりますと、表示したい列(カラム)の数を増やそうとする時は、注意が必要のようです。
ちなみに、
⇧ columnコマンドの利用がNGとなった場合は、自力で頑張るという手もあるようですが、なかなかに茨の道ですな...
そして、
⇧ wc -l って、改行の無い行はカウントされないという罠があると...
何やら、
⇧ grepでも罠があるらしい...GNU版であれば問題ないらしいですが...
毎度モヤモヤ感が半端ない...
今回はこのへんで。