
Ruby言語用のパッケージ管理システムであるRubyGemsのGitHub Enterpriseの名称が勝手に変更され、既存のメンテナが追放されるという事態が発生しました。背景には、Rubyエコシステムのイノベーションを推進する団体「Ruby Central」とのいざこざがあったと伝えられています。
「RubyGems」のGitHub Enterpriseが勝手に「Ruby Central」に改名されて既存のメンテナが追放される事態が発生 - GIGAZINE
当然ながらRubyGemsコミュニティは変更を元に戻すように要望しましたが、このメンテナはホート氏の許可がなければ復元できないとして拒否。メンテナはホート氏と話し合った後、9月15日にメンテナの権限を戻し、ホート氏も削除は間違いだったと認めました。しかし、依然としてホート氏はGitHubエンタープライズのオーナーに指定されており、RubyGemsチームはこれに対応して公式ガバナンスポリシーを導入しました。
「RubyGems」のGitHub Enterpriseが勝手に「Ruby Central」に改名されて既存のメンテナが追放される事態が発生 - GIGAZINE
ホート氏は9月18日に、何の説明もなくRubyGemsやBundler、およびRubyGems.orgメンテナチームのすべての管理者について、GitHubエンタープライズのメンバーシップを取り消しました。こうすることでホート氏は、RubyGemsの権限を掌握したと伝えられています。
「RubyGems」のGitHub Enterpriseが勝手に「Ruby Central」に改名されて既存のメンテナが追放される事態が発生 - GIGAZINE
Ruby Centralは、昨今のソフトウェアサプライチェーン攻撃の増加を受け、RubyGemsエコシステムをエンドツーエンドで保護するための積極的な対策として、管理者アクセスを安全に保つ措置が必要だったと主張しています。
「RubyGems」のGitHub Enterpriseが勝手に「Ruby Central」に改名されて既存のメンテナが追放される事態が発生 - GIGAZINE
なお、Ruby Centralのオープンソース責任者兼RubyGemsプロジェクトの調整役であったアンドレ・アルコ氏は自身のブログで、「チームメイトのエレンが記録している通り、 RubyGemsチームはもう存在しません 。パッケージ管理を機能的に維持し、Rubyコミュニティ全体に貢献するという途方もない任務を担う皆様の幸運を祈っています。その間、私は新しい自由時間を、本当にワクワクするプロジェクトに集中して過ごすことを楽しみにしています」と述べ、RubyGemsプロジェクトから離れたことを報告しました。
「RubyGems」のGitHub Enterpriseが勝手に「Ruby Central」に改名されて既存のメンテナが追放される事態が発生 - GIGAZINE
⇧ 無責任の極みですな...
何故、事前に話し合わないのか...
「報・連・相(ほう・れん・そう)」とかの文化が無いのかね?
報・連・相(ほう・れん・そう)は、「報告」「連絡」「相談」を分かりやすくほうれん草と掛けた略語。主にビジネスにて使われる。
誤解
「上司の状況判断に必要な、部下からの自発的な情報伝達」を習慣的に行わせるためのしつけとして捉えられているが、そもそも、提唱者の山崎の著書では、管理職が「イヤな情報、喜ばしくないデータ」を遠ざけず、問題点を積極的に改善していくことで、生え抜きでない社員や末端社員であっても容易に報告・連絡・相談が行える風通しの良い職場環境をつくるための手段として報連相を勧めているのであって、部下の努力目標ではない。
⇧ 上記にある通り、「問題」の共有や「課題」の発見を促進する取り組みですと。
そもそも、「コミュニケーション」をしようとすらしていないのが宜しくない気はするが...
「メンテナ」の不信感を募らせるだけの愚策だったわけだが、諫言する者が誰もいなかったのも誠に遺憾である...
まぁ、「責任者」が全く仕事していなかったことが明るみに出たということですかね...
Apache Icebergとは
先日、
⇧ 上記の「セッション」を傾聴してきまして、今更ながらではありますが、「Apache Iceberg」について調査したりしたので備忘録として。
Wikipediaによると、
Apache Iceberg is a high performance open-source format for large analytic tables. Iceberg enables the use of SQL tables for big data while making it possible for engines like Spark, Trino, Flink, Presto, Hive, Impala, StarRocks, Doris, and Pig to safely work with the same tables, at the same time.
Iceberg is released under the Apache License.
Iceberg addresses the performance and usability challenges of Apache Hive tables in large and demanding data lake environments.
Vendors currently supporting Apache Iceberg tables include Buster, CelerData, Cloudera, Crunchy Data, Dremio, IBM watsonx.data, IOMETE, Snowflake, Starburst, Tabular, AWS, , Google Cloud, and Databricks.
⇧ とあり、各々の独自の「フォーマット」の「テーブル」に対して、一般的な「SQL」を扱える「フォーマット」の「テーブル」として扱えるようにできる「機能」を提供してくれる「OSS(Open Source Software)」であると。
「Netflix」の「システム」が抱えていた「課題」を解決するために始まった「プロジェクト」であったらしく、
Iceberg was started at Netflix by Ryan Blue and Dan Weeks. Apache Hive was used by many different services and engines in the Netflix infrastructure. Hive was never able to guarantee correctness and did not provide stable atomic transactions.
Many at Netflix avoided using these services and making changes to the data to avert unintended consequences from the Hive format.
Ryan Blue set out to address three issues that faced the Hive table by creating Iceberg:
Iceberg development started in 2017. The project was open-sourced and donated to the Apache Software Foundation in November 2018. In May 2020, the Iceberg project graduated to become a top-level Apache project.
Iceberg is used by multiple companies including Airbnb, Apple, Expedia, LinkedIn, Adobe, Lyft, and many more.
⇧ 2017年に開発が始まって、2018年には「Apache Software Foundation」に寄贈されたとあるので、尋常じゃない開発スピードですな。
で、例の如く、公式である「Apache Software Foundation」では、「Apache Iceberg」の「システム構成概要図」的な「俯瞰」して「全体像」が把握できる「ドキュメント」が公開されていないようだ...
■Before(Apache Iceberg 導入前)
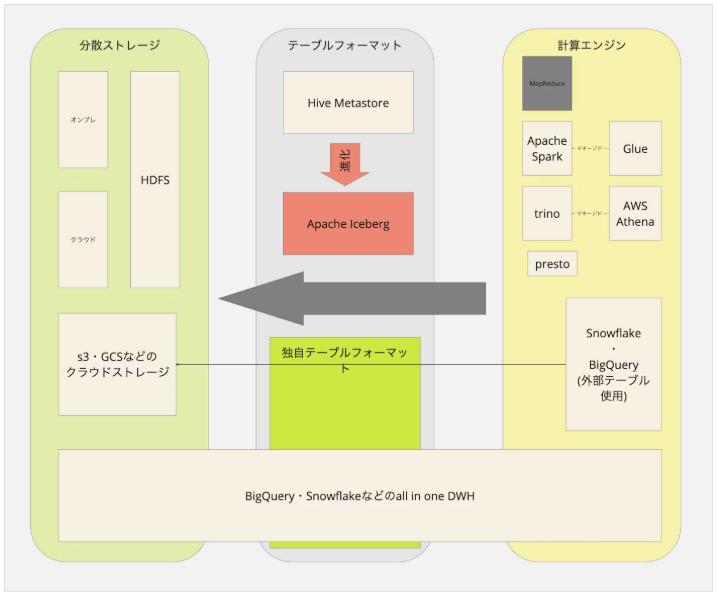
■After(Apache Iceberg 導入後)

⇧ 上記サイト様によると、「データ」が「Apache Iceberg」管理下に集約されることになるようで、「Apache Iceberg」経由での「操作」を強制させられるってことなのかね?
いずれにしろ、

⇧ 上記にあるように、様々な「ソフトウェア」を必要とするようだ。
「Apache Iceberg」自体の「データ」を保存する先が必要らしく、「AWS(Amazon Web Services)」の公開しているドキュメントによると、

⇧ 上図のような感じで「Apache Iceberg」で生成されるファイル群を管理するために「オブジェクトストレージ」が必要らしく、「Amazon S3」が利用されている。
VagrantとVirtualBoxでDocker ComposeにてApache Iceberg環境を構築してみる
ネットの情報を漁っていたところ、
⇧ 上記サイト様で「オンプレミス環境」でも構築できそうなことが分かったので、上記サイト様の情報を参考に、ローカル環境で「Apache Iceberg」を試すことができる環境を構築してみる。
参考サイト様で紹介されているのは、
⇧ 公式の「Apache Spark」と連携する「Quickstart」になるようなのだが、「Apache Iceberg」で生成されるファイル群を保存する「オブジェクトストレージ」としては、「MinIO」というものが利用されているようだ。
MinIO is an object storage system released under GNU Affero General Public License v3.0. It is API compatible with the Amazon S3 cloud storage service. It is capable of working with unstructured data such as photos, videos, log files, backups, and container images with the maximum supported object size being 50TB.
MinIO is a high-performance, S3-compatible object storage solution released under the GNU AGPL v3.0 license. Designed for speed and scalability, it powers AI/ML, analytics, and data-intensive workloads with industry-leading performance.
⇧「Amazon S3」の「API(Application Programming Interface)」と互換性があるとのことなのだが、「Apache Iceberg」は「AWS(Amazon Web Services)」に依存してしまっているのかね?
まぁ、「Apache Iceberg」のドキュメントで、
とあることから、「クラウドサービスプロバイダー」の「マネージドサービス」としては、今のところ「AWS(Amazon Web Services)」しか対応していないってことなんかね?
とりあえず、方針としては、
で「仮想マシン」を作成して、「仮想マシン」に「Docker」などをインストールして、「Docker Compose」で環境を構築していく。
「仮想マシン」の「OS(Operation System)」としては、「AlmaLinux」を利用するので、
⇧ 上記の「RHEL(Red Hat Enterprise Linux)」の手順にあるスクリプトを実行していく感じになるかと。
ちなみに、「Vagrant」を利用して「仮想マシン」を作成する場合、「仮想マシン」の「NIC」に「NAT」が自動的に割り当てられるっぽいので、
⇧ 上記サイト様にありますように、「Docker Compose」の「Composeファイル」である「docker-compose.yml」で「ポートフォワーディング」されることになるっぽいので、別のPCやスマホとかから接続できるってことなんかね?
話が脱線しますが、
⇧ 上記サイト様にありますように、「-wait」オプションなるものが存在するらしいのですが、誠に遺憾であるのだが、正常に処理されても、必ず「1」が返ってきてしまうらしい...
「シェルスクリプト」的には、「0」が正常とされるので、本来であれば「0」が返ってきて欲しいところなのだが、「-wait」オプションは未対応らしい...
で、一番、肝心の「ハードウェア」の
- CPU
- メモリ
の最低必要量についての情報が無いのよね...
とりあえず、吾輩の「Windows 10 Home」は、
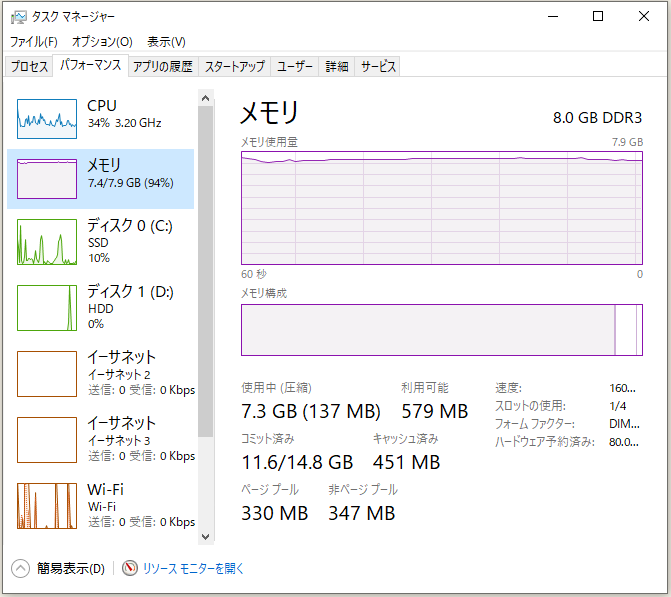
⇧「メモリ」としては「8GB」がMAXなのよね...
とりあえず、「仮想マシン」の「メモリ」として「5120 B(5 GiB)」を割り当てる必要があった...
う~む、やはり「PC」の「メモリ」が最低限「16 GiB」は無いと開発環境を構築するのは厳しいよね...
■Vagrantで構築する際の必要なファイル群
D:\work-soft\vagrant\iceberg
│ Vagrantfile
│
└─vms
└─server
│ docker-compose.yml
│
└─scripts
setup.sh
各々のファイルの中身。
■D:\work-soft\vagrant\iceberg\vms\server\docker-compose.yml
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: apache/iceberg-rest-fixture
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: |
/bin/sh -c "
until (/usr/bin/mc alias set minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
■D:\work-soft\vagrant\iceberg\vms\server\scripts\setup.sh
#!/bin/bash
# https://docs.docker.com/engine/install/rhel/
# 既存のDocker関連パッケージ・podmanなどを削除
sudo dnf remove -y docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine \
podman \
runc
# 必要なプラグインインストール
sudo dnf -y install dnf-plugins-core
# Dockerの公式リポジトリを追加
sudo dnf config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
# Docker Engineと関連ツールをインストール
sudo dnf install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Dockerサービスを有効化・起動
sudo systemctl enable --now docker
# Dockerサービスの状態を確認(オプション)
sudo systemctl status docker --no-pager
# Dockerのバージョン確認
sudo docker -v
# Docker Composeのバージョン確認(プラグインとしてのdocker composeコマンド)
sudo docker compose version
# Docker Composeのファイルを配置
sudo mkdir -p /app
sudo mv /tmp/server/docker-compose.yml /app/docker-compose.yml
cd /app
pwd
# Docker Composeでコンテナを作成・起動
sudo docker compose up -d --wait
# Docker Composeで作成・起動したDockerコンテナの起動状態の確認
sudo docker compose ps
# Docker ComposeでpullされたDocker イメージの確認
sudo docker compose images
# メモリとかチェック
top
free -h
vmstat 1 5
■D:\work-soft\vagrant\iceberg\Vagrantfile
# https://portal.cloud.hashicorp.com/vagrant/discover/almalinux/9
IMAGE_NAME = "almalinux/9"
IMAGE_VESION = "9.6.20250522"
Vagrant.configure("2") do |config|
config.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 1
end
# クライアントVM設定
config.vm.define "iceberg-client" do |client|
client.vm.box = IMAGE_NAME
client.vm.box_version = IMAGE_VESION
client.vm.hostname = "client"
# 内部ネットワーク
client.vm.network "private_network", ip: "192.168.10.1", virtualbox__intnet: "internal_net"
# クライアントVMに関する設定など
client.vm.provision "shell", inline: <<-SHELL
# DNSの接続に関するデバッグ用途
sudo dnf install -y bind-utils
SHELL
end
# Apache Icebergサーバー用VM設定(Apache Icebergインストール)
config.vm.define "iceberg-server" do |server|
server.vm.provider "virtualbox" do |v|
v.memory = 5120
v.cpus = 2
end
server.vm.disk :disk, size: "200GB", primary: true
server.vm.box = IMAGE_NAME
server.vm.box_version = IMAGE_VESION
# Apache Icebergサーバー用VMのホスト名を設定
server.vm.hostname = "iceberg.local"
# ホストオンリーアダプター
# ホスト側のブラウザからApache Icebergに接続するため用
server.vm.network "private_network", ip: "192.168.56.201"
# 内部ネットワーク
server.vm.network "private_network", ip: "192.168.10.2", virtualbox__intnet: "internal_net"
# ホスト側からゲストOS側にファイルコピー
server.vm.provision "file", source: "vms/server/scripts/setup.sh", destination: "/tmp/server/scripts/setup.sh"
server.vm.provision "file", source: "vms/server/docker-compose.yml", destination: "/tmp/server/docker-compose.yml"
# Apache Icebergサーバー用VMにDockerをインストール
server.vm.provision "shell", inline: <<-SHELL
chmod +x /tmp/server/scripts/setup.sh
/tmp/server/scripts/setup.sh
SHELL
end
end
⇧ 上記のファイルを用意したらば、「コマンドプロンプト」などを立ち上げて「Vagrantfile」の配置されたディレクトリに移動して、「Vagrantfile」の内容を実行する。

⇧「Vagrantfile」の処理が完了したらば、ホスト側(吾輩の場合は、「Windows 10 Home」になる)の「ブラウザ」から、以下のURLにアクセス。
■「spark-iceberg」のコンテナの「jupyter notebook」環境にアクセス
http://[ホストオンリーアダプターのIPアドレス]:8888/tree?
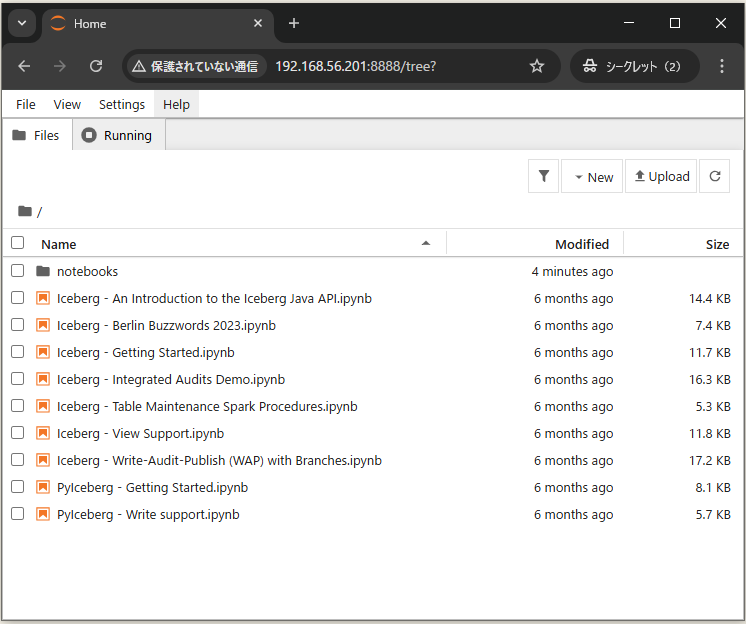
⇧「Iceberg - Getting Started.ipynb」を選択すると、「ブラウザ」の別タブでページ遷移するので、「Run」タブをクリックすると選択肢が出てくるので、「Run All Above Selected Cell」を選択すると、ページにあるスクリプトを全て実行してくれる。

⇧ 最後のスクリプトまで実行されたら、以下のURLにアクセスして、「MinIO」にアクセスする。
■「MinIO」にアクセス
http://[ホストオンリーアダプターのIPアドレス]:9001
以下の情報でログインできるっぽい。
| No | 項目 | 内容 |
|---|---|---|
| 1 | Username | admin |
| 2 | Password | password |

「Buckets」に生成されたファイル群が保存されているらしい。


一応、意図された動作はしたということで良いんだろうか?
実際の「データ」がサイロ化された「分散システム」で活用するには「情報」が足りませんな...
「Apache Iceberg」の「Catalog」の保存先としては、「Apache Spark」で必要となる「Apache Hadoop」が利用されているということなんかね?
「Docker Compose」で「隠蔽」されてしまっているから、各々の「ソフトウェア」や「ライブラリ」の関連がよく分かりませんな...
毎度モヤモヤ感が半端ない…
今回はこのへんで。