
⇧ 本当に、保存期間が1万年であるのか検証しようのないところが辛いところですな...
PythonでCSVファイルのバリデーションはなかなかに辛い...
もしかしたら、PythonでCSVファイルのバリデーションをすることになるかもしれないということで、調べてたのですが、
⇧ 上記サイト様にあるように、自力でバリデーション処理を実装する必要がありそう...、地獄なんだが...
え~っと...
⇧ 巷ではPythonって人気の言語っぽいですと。
なのにですよ、バリデーションすらまともに用意されていないってどういうこと?
と言うか、誰も情報発信していないだけで、もしかして、標準の機能としてバリデーションは用意されているってことなんかね?
CSVファイルの読み書きについては、Pythonの組み込みの関数としてデフォルトで用意されているっぽいのだけど、
Dialect クラスと書式化パラメータ
レコードに対する入出力形式の指定をより簡単にするために、特定の書式化パラメータは表現形式 (dialect) にまとめてグループ化されます。表現形式は Dialect クラスのサブクラスで、様々なクラス特有のメソッドと、 validate() メソッドを一つ持っています。
⇧ ドキュメントに記載の「validate() メソッド」についての説明が一切無いので、「validate() メソッド」で何ができるのかが全く分からない...
stackoverflowによると、
The documentation may seem unclear if you just read that line, but a few lines above you can see that:
To make it easier to specify the format of input and output records, specific formatting parameters are grouped together into dialects. A dialect is a subclass of the Dialect class having a set of specific methods and a single validate() method.
Doing a simple help(csv.Dialect) in the REPL confirms that subclassing is a must when working with this class.
class Dialect(builtins.object)
| Describe a CSV dialect.
|
| This must be subclassed (see csv.excel). Valid attributes are:
| delimiter, quotechar, escapechar, doublequote, skipinitialspace,
| lineterminator, quoting.
|
| Methods defined here:
|
| __init__(self)
| Initialize self. See help(type(self)) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| delimiter = None
|
| doublequote = None
|
| escapechar = None
|
| lineterminator = None
|
| quotechar = None
|
| quoting = None
|
| skipinitialspace = None⇧ サブクラス化が必須ということに言及してるものの、「validate() メソッド」持っていないんだが...
"""
csv.py - read/write/investigate CSV files
"""
...省略
from _csv import Dialect as _Dialect
...省略
class Dialect:
"""Describe a CSV dialect.
This must be subclassed (see csv.excel). Valid attributes are:
delimiter, quotechar, escapechar, doublequote, skipinitialspace,
lineterminator, quoting.
"""
_name = ""
_valid = False
# placeholders
delimiter = None
quotechar = None
escapechar = None
doublequote = None
skipinitialspace = None
lineterminator = None
quoting = None
def __init__(self):
if self.__class__ != Dialect:
self._valid = True
self._validate()
def _validate(self):
try:
_Dialect(self)
except TypeError as e:
# We do this for compatibility with py2.3
raise Error(str(e))
...省略
⇧ とあるように、「_validate(self)」ってメソッドが定義されておりました。
クラス内の変数やメソッドの先頭にアンダースコアを1つ付与する場合は、慣例的な意味として、「クラス内でのみで参照・使用されるもの」を示します。
つまり、クラス外からアクセスされることを意図されていない変数・メソッドということです。と言っても慣例的な意味合いなので、アクセス自体は可能ですので、あくまでも意思表示(注意喚起)というような形です。
⇧ 上記サイト様によりますと、Pythonの「アンダースコア」の意味が様々らしいのですが、メソッドの先頭に付いている場合は、クラスの中だけで使って欲しいという意図が込められているんだとか...
何やら、Pythonのコーディング規約として標準ライブラリのコード規約「PEP」というものが有名らしいのですが、
Pythonのコーディング規約として有名なのは標準ライブラリのコード規約PEP 8であるが、Google Python Style Guideというものがあるという。
はじめに
この文書は Python の標準ライブラリに含まれているPythonコードのコーディング規約です。CPython に含まれるC言語のコードについては、対応するC言語のスタイルガイドを記した PEP を参照してください。
命名規約
実践されている命名方法
それに加えて、次のようにアンダースコアを名前の前後に付ける特別なやり方が知られています(これらに大文字小文字に関する規約を組み合わせるのが一般的です):
-
_single_leading_underscore: "内部でだけ使う" ことを示します。 たとえばfrom M import *は、アンダースコアで始まる名前のオブジェクトをimportしません。 -
single_trailing_underscore_: Python のキーワードと衝突するのを避けるために使われる規約です。例を以下に挙げます:tkinter.Toplevel(master, class_='ClassName')
-
__double_leading_underscore: クラスの属性に名前を付けるときに、名前のマングリング機構を呼び出します (クラス Foobar の__booという名前は_FooBar__booになります。以下も参照してください) -
__double_leading_and_trailing_underscore__: ユーザーが制御する名前空間に存在する "マジック"オブジェクト または "マジック"属性です。 たとえば__init__,__import__,__file__が挙げられます。この手の名前を再発明するのはやめましょう。ドキュメントに書かれているものだけを使ってください。
⇧ それによると、『"内部でだけ使う" ことを示します。』となっていますな。
で、「self」はと言うと、
Often, the first argument of a method is called self. This is nothing more than a convention: the name self has absolutely no special meaning to Python. Note, however, that by not following the convention your code may be less readable to other Python programmers, and it is also conceivable that a class browser program might be written that relies upon such a convention.
⇧ 全く役に立たない説明なんだが...
公式の情報では無いっぽいのだけど、

⇧ 上記サイト様の説明がイメージしやすいかと。
上記サイト様の説明が正しいと仮定すると、要するに、同じクラスのインスタンスを複数生成してる場合に、各々のインスタンスを識別するための用途、ということになるっぽいです。
で、「_validate(self)」って結局のところ、CSVファイルをバリデーションするような機能ではないっぽい、紛らわしい名前のメソッドっすな...
PythonでCSVファイルのバリデーションを行ってみる
調べた感じでは、PythonでCSVファイルのバリデーションを行うには、
- 自作でバリデーション処理を作る
- 外部ライブラリを利用する
のどちらかになる感じなんかね?
ただ、外部ライブラリだと、バリデーションを網羅できていないっぽい気がするので、結局のところ、自作で頑張るしか無さそうね...
CSVファイルのヘッダーの有無のチェックなどは、
⇧ 上記サイト様を参考にさせていただきました。
では、まずは、Pythonの環境を用意します。Windowsなので、pyランチャーでインストールされてるPythonのバージョンを確認し、Pythonのプロジェクト用のフォルダを作成しておいて、移動して、Python仮想環境を作成で。
VS code(Visual Studio Code)で、Pythonのプロジェクト用のフォルダを開きます。
PowerShell用のスクリプトファイルを実行し、Python仮想環境へログイン。
⇧ とりあえず、ログインできました。
今回は、Pythonに標準で用意されてるモジュールのみでバリデーションを実現していきますか。(pandasとか使ってる例は、参考サイト様があるので)
ファイルとかは、以下のような感じのものを作っています。
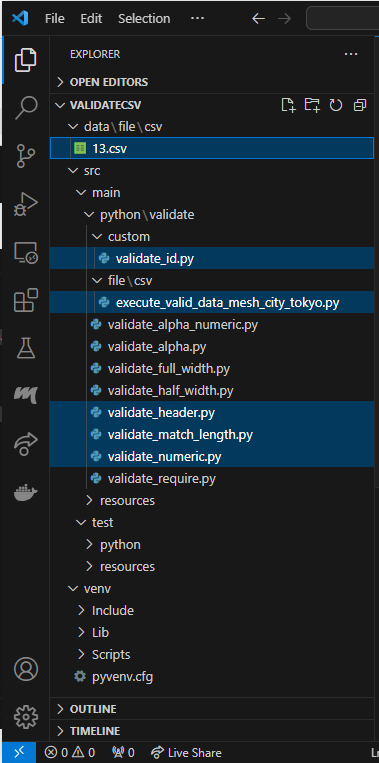
C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv
│
├─data
│ └─file
│ └─csv
│ 13.csv
│
├─log
│
├─src
│ ├─main
│ │ ├─python
│ │ │ └─validate
│ │ │ │ validate_alpha.py
│ │ │ │ validate_alpha_numeric.py
│ │ │ │ validate_full_width.py
│ │ │ │ validate_half_width.py
│ │ │ │ validate_header.py
│ │ │ │ validate_match_length.py
│ │ │ │ validate_numeric.py
│ │ │ │ validate_require.py
│ │ │ │
│ │ │ ├─custom
│ │ │ │ validate_id.py
│ │ │ │
│ │ │ └─file
│ │ │ └─csv
│ │ │ execute_valid_data_mesh_city_tokyo.py
│ │ │
│ │ └─resources
│ └─test
│ ├─python
│ │ └─validate
│ │ └─file
│ │ └─csv
│ │ test_execute_valid_data_mesh_city_tokyo.py
│ │
│ └─resources
│ └─data
│ └─file
│ └─csv
│ └─test_execute_valid_data_mesh_city_tokyo
│ └─input
└─venv
│ pyvenv.cfg
│
├─Include
├─Lib
│ └─site-packages
...省略
│
└─Scripts
activate
activate.bat
Activate.ps1
deactivate.bat
pip.exe
pip3.10.exe
pip3.exe
python.exe
pythonw.exe
今回、利用しているファイルについて、ソースコードなどを記載します。
※CSVファイルの中身については、省略しています。
■抜粋 C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\data\file\csv\13.csv
ID,都道府県市区町村コード,市区町村名,基準メッシュ・コード T00001,13101,千代田区,53394509 T00002,13101,千代田区,53394518 T00003,13101,千代田区,53394519 ...省略 T03426,13999,境界未定地域,45405294 T03427,13999,境界未定地域,47396763 T03428,13999,境界未定地域,47401024 T03429,13999,境界未定地域,47401034
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\custom\validate_id.py
import re
def validate_id(col: str):
"""
IDのフォーマットチェック
@param list[str] col 列
@return str エラーメッセージ
"""
pattern = r"[A-Z]\d{5}"
if not re.fullmatch(pattern, col):
return "IDのフォーマットが不正"
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\validate_header.py
import csv
def validate_header(file: any, inputHeader: list[str], correctHeader: list[str]):
"""
ヘッダーのチェック
@param
@param
"""
exsits_header(file)
if set(inputHeader) != set(correctHeader):
return "ヘッダーが不正です"
def exsits_header(file: any):
"""
ヘッダーの有無のチェック
@param
"""
row=file.read(1024)
file.seek(0)
existsHeader = csv.Sniffer().has_header(row)
if not existsHeader:
return "ヘッダーが存在しません"
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\validate_require.py
def validate_require(col: str):
"""
必須チェック
@param list[str] col 列
@return str エラーメッセージ
"""
if not col:
return "必須項目です。"
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\validate_numeric.py
import re
def validate_numeric(col: str):
"""
半角数字チェック
@param str col 列
@return str エラーメッセージ
"""
digitReg = re.fullmatch(r'^[0-9]+$', col)
if not digitReg:
return "半角数字のみの項目です。"
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\validate_match_length.py
def validate_match_length(col: str, matchLength: int):
"""
文字数チェック
@param str col 列
@param int matchLength 文字数
@return str エラーメッセージ
"""
if len(col) != matchLength:
return "固定長の項目です。"
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\file\csv\execute_valid_data_mesh_city_tokyo.py
import os
import sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '../../')))
import validate_header as validate_header
import validate_require as validate_require
import validate_numeric as validate_numeric
import validate_match_length as validate_match_length
import custom.validate_id as validate_id
import csv
projectRoot = os.path.dirname(os.path.abspath(os.path.join(os.path.dirname(__file__), '../../../../../')))
inputFileName='13.csv'
inputFileDir=os.sep.join(['data','file','csv', inputFileName])
inputEncoding='shift-jis'
inputFile=os.sep.join([projectRoot,inputFileDir])
correctHeader=['ID','都道府県市区町村コード','市区町村名','基準メッシュ・コード']
rowIndex=0
with open(inputFile, encoding=inputEncoding, newline='') as f:
csvreader = csv.reader(f)
print('【Start】validate csv file.')
for row in csvreader:
if rowIndex == 0:
validate_header.validate_header(f, row, correctHeader)
next(csvreader)
else:
# 1列目のバリデーション
validate_require.validate_require(row[0])
validate_id.validate_id(row[0])
# 2列目のバリデーション
validate_require.validate_require(row[1])
validate_numeric.validate_numeric(row[1])
validate_match_length.validate_match_length(row[1], 5)
# 3列目のバリデーション
validate_require.validate_require(row[2])
# 4列目のバリデーション
validate_require.validate_require(row[3])
validate_numeric.validate_numeric(row[3])
validate_match_length.validate_match_length(row[3], 8)
rowIndex +=1
print('【Finish】【Success】validate csv file.')
print('【インプット】' + inputFile)
print('【行数】' + str(rowIndex))
⇧ で、PowerShellで実行。
python -B .\execute_valid_data_mesh_city_tokyo.py
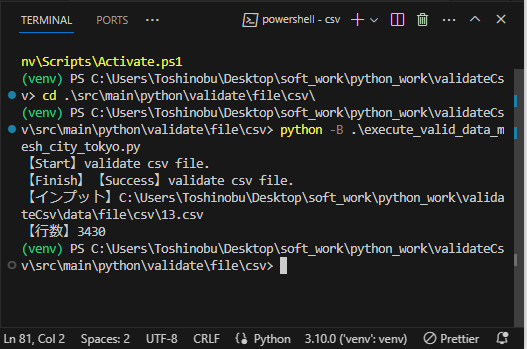
⇧ 「execute_valid_data_mesh_city_tokyo.py」の実行自体はできたようです。
後は、インプットのCSVファイルのデータをバリデーションでエラーメッセージが出るような内容のものに変えて、バリデーションが機能しているか確認すれば良さそうですが、時間の都合上、別の機会に確認します。
一応、処理時間などを追加したバージョンも掲載。
■C:\Users\Toshinobu\Desktop\soft_work\python_work\validateCsv\src\main\python\validate\file\csv\execute_valid_data_mesh_city_tokyo.py
import os
import sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '../../')))
import validate_header as validate_header
import validate_require as validate_require
import validate_numeric as validate_numeric
import validate_match_length as validate_match_length
import custom.validate_id as validate_id
import csv
import datetime
# プロジェクトのルートディレクトリ
projectRoot = os.path.dirname(os.path.abspath(os.path.join(os.path.dirname(__file__), '../../../../../')))
# インプット
inputFileName='13.csv'
inputFileDir=os.sep.join(['data','file','csv', inputFileName])
inputEncoding='shift-jis'
inputFile=os.sep.join([projectRoot,inputFileDir])
# バリデーション処理の開始時間
startDateTime=datetime.datetime.now()
# ログファイル
outputFileName='result_validate'+ startDateTime.strftime("%Y-%m-%d-%H%M%S%f") +'.log'
outputFileDir=os.sep.join(['log', outputFileName])
outputEncoding='utf-8'
outputFile=os.sep.join([projectRoot,outputFileDir])
# インプットのCSVファイルのヘッダー
correctHeader=['ID','都道府県市区町村コード','市区町村名','基準メッシュ・コード']
# ファイルの行数
rowIndex=0
# ファイルを開く
with open(inputFile, encoding=inputEncoding, newline='') as fi, open(outputFile, 'w', encoding=outputEncoding, newline='') as fw:
#csvreader = csv.reader(fi, skipinitialspace=True)
# インプットのファイルを読み込み
csvreader = csv.reader(fi)
print('【Start】validate csv file.')
#fw.write(csvreader+ '\n')
# 1行ずつ読み込み
for row in csvreader:
fw.write(",".join(row)+'\n')
# ヘッダー行の場合
if rowIndex == 0:
validate_header.validate_header(fi, row, correctHeader)
next(csvreader)
# ヘッダー行以外の場合
else:
# 1列目のバリデーション
validate_require.validate_require(row[0])
validate_id.validate_id(row[0])
# 2列目のバリデーション
validate_require.validate_require(row[1])
validate_numeric.validate_numeric(row[1])
validate_match_length.validate_match_length(row[1], 5)
# 3列目のバリデーション
validate_require.validate_require(row[2])
# 4列目のバリデーション
validate_require.validate_require(row[3])
validate_numeric.validate_numeric(row[3])
validate_match_length.validate_match_length(row[3], 8)
# 行数をインクリメント
rowIndex +=1
# バリデーション処理の終了時間
finishDateTime=datetime.datetime.now()
# バリデーション処理の結果をコンソールに出力
print('【Finish】【Success】validate csv file.')
print('【インプット】' + inputFile)
print('【行数】' + str(rowIndex))
print('【処理開始時間】' + startDateTime.strftime("%Y-%m-%d %H:%M:%S.%f"))
print('【処理終了時間】' + finishDateTime.strftime("%Y-%m-%d %H:%M:%S.%f"))
delta = finishDateTime - startDateTime
print('【処理時間】' + str(delta.total_seconds()))
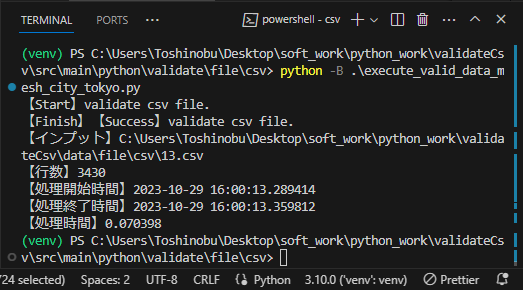
今回、時間が無くて対応できなかったけども、
⇧ 上記サイト様にありますように、
- ローカル環境
- テスト環境
- ステージング環境
- 本番環境
毎に適用する設定を分けれるようにできた方が良いような気がしている、Pythonだとどうするのが良いのかが分からんので何とも言えんけど...
「全角」と「半角」の区別を判定とかもPythonで正確にできるのか微妙そうなのもあるけど、Pythonでの「文字列」のバリデーションの情報がネット上でほとんど見当たらないのが謎なんだが...
データサイエンスとかで、「データクレンジング」する時は、厳密なバリデーションが不要なんかね?
う~む、エンタープライズ系のシステム開発とかで必要となってくる機能に対して、Pythonは向いていないってことなんかな...
⇧ 上記サイト様によりますと、中規模開発でもなかなかに厳しい結果になったという話がありますね、実際に業務として取り組んだ人の話は説得力がありますな。
「Python 大規模開発 事例」とかでネットの情報をググってみたけども、
⇧ 1件しか見当たらなかった...
情報の公開を禁止されてるのかもしらんけど、事例としての情報が少ないと、どうしてもPython本当に大規模開発に耐え得るのか、という疑念が払拭し辛いよね...
Pythonは科学計算系のライブラリが充実してることから、データサイエンスやゲーム開発に向いていそうではある気がするけども。
毎度モヤモヤ感が半端ない...
今回はこのへんで。