
見立てに誤りがあった原因は、引継ぎの不足だ。実は、移行を担当した人物は入社2カ月ほど。前任者からファイルサイズについては話を聞いていたものの、ファイル数については共有されていなかったという。
「Google Cloudのデータ転送で課金爆死」 あるSIerの顧客事例が教訓に満ちていた 失敗の原因は - ITmedia NEWS
今回の事例について、G-genは「Cloud Storageの利用料金はデータ容量だけでなくリクエストの回数による課金も発生することを念頭に置いて利用することが大切だと、改めて実感する」としており、同様のミスへの注意喚起も兼ねて、顧客に許可を得た上で詳細を公開したという。
「Google Cloudのデータ転送で課金爆死」 あるSIerの顧客事例が教訓に満ちていた 失敗の原因は - ITmedia NEWS
⇧ こういう有益な情報を公開してくれるのは、誠にありがたいですな。こういった顧客のIT業界に対する理解が、IT業界をより良くしてくれるんでしょうね。
オンプレミス環境とクラウド環境とで、コストの考え方も違ってそうだけど、
- 見積もり作業
- 実際の移行作業
ってフェーズはオンプレミス環境とクラウド環境のどちらの場合も存在すると思うので、見積もり(概算見積もり、詳細見積もり、で言ったら詳細見積もりが該当すると思うけど)でコスト面の見積もり精度の確からしさについては、ある程度見通しを立てておく必要があると。
入社2か月の人間に見積もりさせていたとしたら、酷だと思いますが...
あとは、クラウド環境の課金の実態が分かり辛いってのも大いにあるとは思うけど...
認識齟齬を発生させないドキュメント作成の難しさを物語っていますな...
PowerShellでCSVファイルの列(カラム)の全ての値のデータ型をチェックしたい
ちょっと前に、
- CSVファイルの「列(カラム)」で不正な値を見つけて欲しい。
- システムの仕様は不明である。
- IF(インターフェイス)定義書はなく、「列(カラム)」に入る値のデータ型は不明である。
- CSVファイルの種類がいくつあるかは分からない。
- CSVファイルにヘッダーは付いている。
- 数値のみ許容の「列(カラム)」に、数値以外が混入してるらしいことだけは分かっている。
- データベースのどのテーブルと紐づいているか不明である。
- PowerShellは使える環境である。
- OSS(Open Source Software)を含め何かをインストールするの実質不可能である。
という状況になりまして、PowerShellでチェックするスクリプトを組めたら良かったんですが、その時はPowerShell 何も分からんな状態だったので、業務外の時間で実際にPowerShell でチェックするスクリプトが実現できるのか調査&試行錯誤してみました。
で、PowerShellでスクリプトを組むとしたら、
- CSVファイルのヘッダーが同じものを集める
- 数値のみの「列(カラム)」を特定する
- 「列(カラム)」名を保持する
- 「列(カラム)」の数の差分を確認する
のような感じになるのかと思ったけど、「必須」じゃない「列(カラム)」とかが考慮できてなかったことに気付いてしまったのだけど、一旦、中途半端にはなるけれど、スクリプトを作ってみました。
とりあえず、以下のような感じで。
■C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\sort_csv_file.ps1
# PowerShell Script
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 処理
# ■ CSVファイルのヘッダーが同じものでソートする
# ■ 引数
# ■ param $root_dir CSVファイルが配置されているディレクトリ
# ■ param $output_result_file ログファイル
# ■ 戻り値
# ■ return ソート実施後のCSVファイル
# ■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
Function sortCsvHeaderValue($root_dir, $output_result_file){
# CSVファイルのフルパスを取得する
[array] $csv_file_full_path_arr = (Get-ChildItem $root_dir -Recurse -Filter '*.csv' -File).FullName
#Write-Output -InputObject $csv_file_full_path_arr | Out-File -Encoding default $output_result_file -Append
$csv_hash_arr_list=@{}
#$csv_hash_arr = @{}
# CSVファイルの数だけ繰り返し処理
for ($index = 0; $index -lt $csv_file_full_path_arr.Length; $index++) {
$csv_data = Get-Content $csv_file_full_path_arr[$index]
#$csvColumnNames = (Get-Content $csv_file_full_path_arr[$index] | Select-Object -First 1).Split(",")
# CSVファイルのフルパス、CSVヘッダーを要素の連想配列を生成する
$csv_hash_arr = @{
file_path=$csv_file_full_path_arr[$index]
csv_header=$csv_data[0]
}
# 連想配列に連想配列を追加する
$csv_hash_arr_list.Add($csv_hash_arr_list.Count +1, $csv_hash_arr)
Write-Output -InputObject $csv_hash_arr | Out-File -Encoding default $output_result_file -Append
}
#Write-Output -InputObject $csv_hash_arr_list | Out-File -Encoding default $output_result_file -Append
#Write-Output -InputObject $csv_hash_arr | Out-File -Encoding default $output_result_file -Append
#$csv_hash_arr_list | Sort-Object -Property csv_header | Out-File -Encoding default $output_result_file -Append
# CSVヘッダーの値でソートする
#$sorted_csv_hash_arr_list = $csv_hash_arr_list.GetEnumerator() | Sort-Object { $_.Value.csv_header }
#$sorted_csv_hash_arr_list = $csv_hash_arr_list.Keys | Sort-Object { $csv_hash_arr_list[$_].csv_header }
#$sorted_csv_hash_arr_list = $csv_hash_arr_list.Values | Sort-Object { $_.csv_header }
#$sorted_csv_hash_arr_list = $csv_hash_arr_list.Values | Sort-Object csv_header
# CSVヘッダーの値でソートする
#$csv_hash_arr_list.GetEnumerator() | Sort-Object { $_.Value.csv_header } | ForEach-Object {
# $csv_hash_arr_list[$_.Key] = $_.Value
# $_.Value | Out-File -Encoding default $output_result_file -Append
#}
# ソートされたデータをファイルに書き込む
#$csv_hash_arr_list | ForEach-Object { $_.Value | Out-File -Encoding default $output_result_file -Append }
# エラーになる
# $csv_hash_arr_list | ConvertTo-Json
# $csv_hash_arr_list | Format-Custom | Out-File -Encoding default $output_result_file -Append
#return $csv_hash_arr_list
# CSVヘッダーの値でソートする
$sorted_csv_hash_arr_list = $csv_hash_arr_list.GetEnumerator() | Sort-Object { $_.Value.csv_header }
# ソートされたデータをファイルに書き込む
$sorted_csv_hash_arr_list | ForEach-Object {
$_.Value | Out-File -Encoding default $output_result_file -Append
}
# ソートされたデータを元のハッシュテーブルに反映
$csv_hash_arr_list.Clear()
$sorted_csv_hash_arr_list | ForEach-Object {
$csv_hash_arr_list.Add($csv_hash_arr_list.Count + 1, $_.Value)
}
# ソートされたデータを返す
return $csv_hash_arr_list
}
■C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\csv_column_checker.ps1
# PowerShell Script
# 読み込み
. ".\sort_csv_file.ps1"
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 処理
# ■ CSVファイルの列のデータ型が全て同じかチェック
# ■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ルートディレクトリ
$root_dir = 'C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\data'
# 結果出力先ファイル
$output_result_file = 'C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\output\result.txt'
# CSVファイルのソート
$csv_hash_arr_list = sortCsvHeaderValue $root_dir $output_result_file
#Write-Output -InputObject "csv_hash_arr_list" | Out-File -Encoding default $output_result_file -Append
#$csv_hash_arr_list | Format-Custom | Out-File -Encoding default $output_result_file -Append
$fileNumer = 1
$start_date_time = Get-Date -Format "yyyy-MM-dd hh:mm:ss"
Write-Output "['$start_date_time'][start]`t check data type for columns of CSV file" | Out-File -Encoding default $output_result_file -Append
# ■行毎に処理
# CSVファイルの数だけ繰り返し
foreach ($element in $csv_hash_arr_list.Keys) {
# Write-Output -InputObject $csv_hash_arr_list[$element].file_path | Out-File -Encoding default $output_result_file -Append
# CSVファイルのパス
$csvFilePath = $csv_hash_arr_list[$element].file_path
# CSVファイルのヘッダー
$csvFileHeader = $csv_hash_arr_list[$element].csv_header
# CSVファイルの中身を取得
$csvLines = Get-Content -Path $csvFilePath
# ヘッダーの処理(最初の行をヘッダーとして取得)
$header = $csvLines[0] -split ','
# データ部分の処理(ヘッダー以外の行を取得)
$dataLines = $csvLines[1..($csvLines.Count - 1)]
# 行数カウンターの初期化
$rowNumber = 1
# 列(カラム)のデータ型をチェックした結果の出力メッセージ
$result_check_message = ''
# ファイルに出力
Write-Output "[FileNumber] '$fileNumer'" | Out-File -Encoding default $output_result_file -Append
Write-Output "[FilePath] '$csvFilePath'" | Out-File -Encoding default $output_result_file -Append
Write-Output "[CsvHeader] '$csvFileHeader'" | Out-File -Encoding default $output_result_file -Append
# 行の数だけ繰り返し
foreach ($line in $dataLines) {
# 行をカンマで分割
$values = $line -split ','
# 列(カラム)の数だけ繰り返し
for ($i = 0; $i -lt $values.Count; $i++) {
$columnName = $header[$i]
$columnValue = $values[$i]
# 列(カラム)の値が数値かどうかをチェック
$isNumeric = $columnValue -as [double] -ne $null
# 列(カラム)の値が空だった場合
if ([string]::IsNullOrEmpty($columnValue)) {
$result_check_message = "is Empty"
# 列(カラム)の値が数値だった場合
} elseif ($isNumeric) {
$result_check_message = "is Numeric"
#Write-Output "[row]`t '$rowNumber' `t[column]`t '$columnName' `t[value]`t '$columnValue' `t is Numeric" | Out-File -Encoding default $output_result_file -Append
# 列(カラム)の値が空でなく、且つ、数値でない場合
} else {
$result_check_message = "is NonNumeric"
#Write-Output "[row]`t '$rowNumber' `t[column]`t '$columnName' `t[value]`t '$columnValue' `t is NonNumeric" | Out-File -Encoding default $output_result_file -Append
}
# 結果をファイルに出力
Write-Output "[row]`t '$rowNumber' `t[column]`t '$columnName' `t[value]`t '$columnValue' `t '$result_check_message'" | Out-File -Encoding default $output_result_file -Append
}
# 行数を増やす
$rowNumber++
}
# 次のファイル
$fileNumer++
}
# 処理終了日時
$finish_date_time = Get-Date -Format "yyyy-MM-dd hh:mm:ss"
Write-Output "['$finish_date_time'][finished]`t check data type for columns of CSV file" | Out-File -Encoding default $output_result_file -Append
# ■列(カラム)毎に処理
# 結果出力先ファイル
$output_result_columns_file = 'C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\output\result_columns.txt'
# 結果出力先ファイル(サマリー)
$output_result_columns_summary_file = 'C:\Users\Toshinobu\Desktop\soft_work\winodws_work\work_powershell\csv_column_check\output\result_columns_summary.txt'
# 処理開始日時
$start_date_time = Get-Date -Format "yyyy-MM-dd hh:mm:ss"
Write-Output "['$start_date_time'][start]`t check data type for columns of CSV file" | Out-File -Encoding default $output_result_columns_file -Append
# CSVファイルの数をカウント用
$fileNumer = 1
# CSVファイルの数だけ繰り返し
foreach ($element in $csv_hash_arr_list.Keys) {
# CSVファイルのパス
$csvFilePath = $csv_hash_arr_list[$element].file_path
# CSVファイルのヘッダー
$csvFileHeader = $csv_hash_arr_list[$element].csv_header
# CSVファイルの中身を取得
$csvLines = Get-Content -Path $csvFilePath
#Write-Output -InputObject $csvFileHeader.GetType().FullName | Out-File -Encoding default $output_result_columns_file -Append
#Write-Output -InputObject $csvLines.GetType().FullName | Out-File -Encoding default $output_result_columns_file -Append
# ファイルに出力
Write-Output "[FileNumber] '$fileNumer'" | Out-File -Encoding default $output_result_columns_file -Append
Write-Output "[FilePath] '$csvFilePath'" | Out-File -Encoding default $output_result_columns_file -Append
Write-Output "[CsvHeader] '$csvFileHeader'" | Out-File -Encoding default $output_result_columns_file -Append
# CSVファイルのヘッダーを含める
$csvObjects = $csvLines | ConvertFrom-Csv -Header ($csvFileHeader -split ',')
$result_check_column_message = ''
# CSVファイルのヘッダーの列(カラム)の数だけ繰り返し
foreach ($csvColumnName in $csvFileHeader.split(",")) {
# 各列(カラム)毎に、全行取得
$csvColumnValues = $csvObjects | Select-Object -ExpandProperty $csvColumnName
# 各列(カラム)毎に、行の数だけ繰り返し
$csvColumnValues | ForEach-Object {
# 列(カラム)の値が、数値で無い場合
if (-not [double]::TryParse($_
, [System.Globalization.NumberStyles]::Number
, [System.Globalization.CultureInfo]::InvariantCulture
, [ref]$null)) {
$result_check_column_message = "Non All Numeric"
}
}
# 列(カラム)が、全て数値の場合
if ([string]::IsNullOrEmpty($result_check_column_message)) {
$result_check_column_message = "All Numeric"
}
# ファイルに出力
Write-Output " [result]`t '$result_check_column_message'`t [column]`t '$csvColumnName' `t[values]`t $($csvColumnValues -join ', ')" | Out-File -Encoding default $output_result_columns_file -Append
# 出力メッセージをリセット
$result_check_column_message = ''
}
# ファイル(サマリー用)に書き込む
# Write-Output "[FileNumber] '$fileNumer'" | Out-File -Encoding default $output_result_columns_summary_file -Append
# Write-Output "[FilePath] '$csvFilePath'" | Out-File -Encoding default $output_result_columns_summary_file -Append
# Write-Output "[CsvHeader] '$csvFileHeader'" | Out-File -Encoding default $output_result_columns_summary_file -Append
# 数値でないカラム名を保存するための配列
$nonNumericColumns = @()
# CSVファイルのヘッダーの列(カラム)の数だけ繰り返し
foreach ($csvColumnName in $csvFileHeader.split(",")) {
# 各列(カラム)毎に、全行取得
$csvColumnValues = $csvObjects | Select-Object -ExpandProperty $csvColumnName
# 列(カラム)の値が、数値で無い場合
$csvColumnValues | ForEach-Object {
if (-not [double]::TryParse($_
, [System.Globalization.NumberStyles]::Number
, [System.Globalization.CultureInfo]::InvariantCulture
, [ref]$null)) {
$nonNumericColumns += $csvColumnName
continue;
}
}
}
# 一時的な文字列変数に結合してからファイルに出力
$outputString = "[FileNumber]`t '$fileNumer'`t " +
"[FilePath]`t '$csvFilePath'`t " +
"[CsvHeader]`t '$csvFileHeader'`t " +
"[Non-Numeric Columns]`t $($nonNumericColumns -join ', ')"
# 数値でないカラム名を出力
Write-Output $outputString | Out-File -Encoding default $output_result_columns_summary_file -Append
# 次のファイル
$fileNumer++
}
# 処理終了日時
$finish_date_time = Get-Date -Format "yyyy-MM-dd hh:mm:ss"
Write-Output "['$finish_date_time'][finished]`t check data type for columns of CSV file" | Out-File -Encoding default $output_result_columns_file -Append
⇧ で、実行すると、
日本語の列(カラム)が上手くいってなさそうだけど、英数字の列(カラム)については、数値かどうかの判定はできてそう。
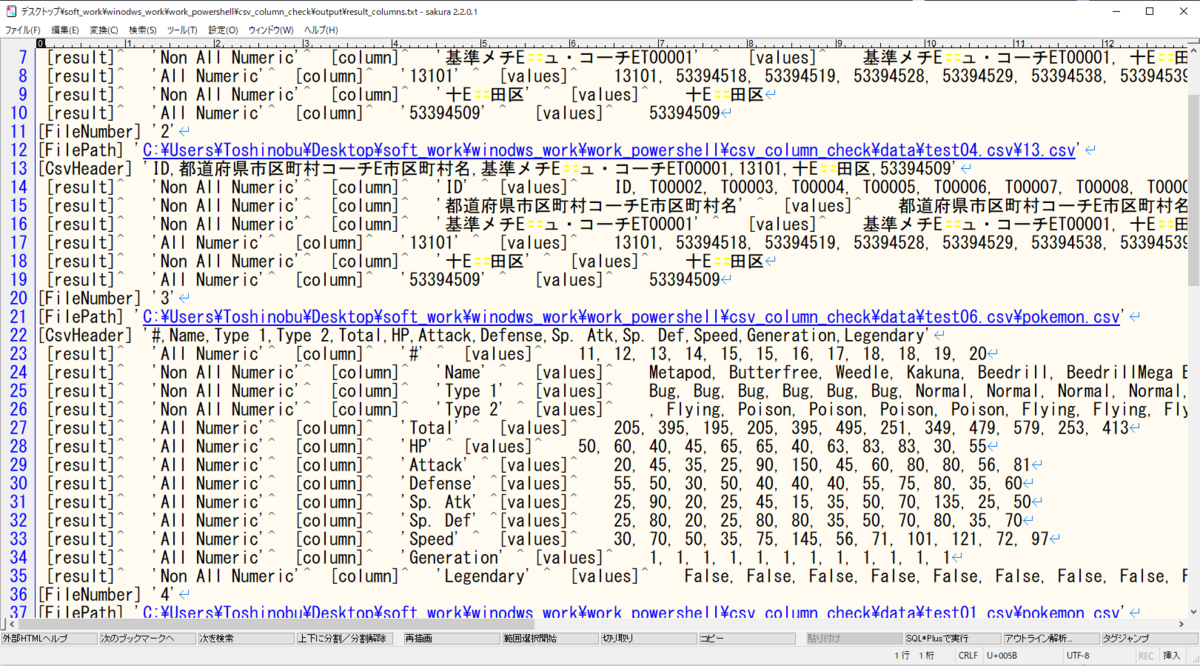
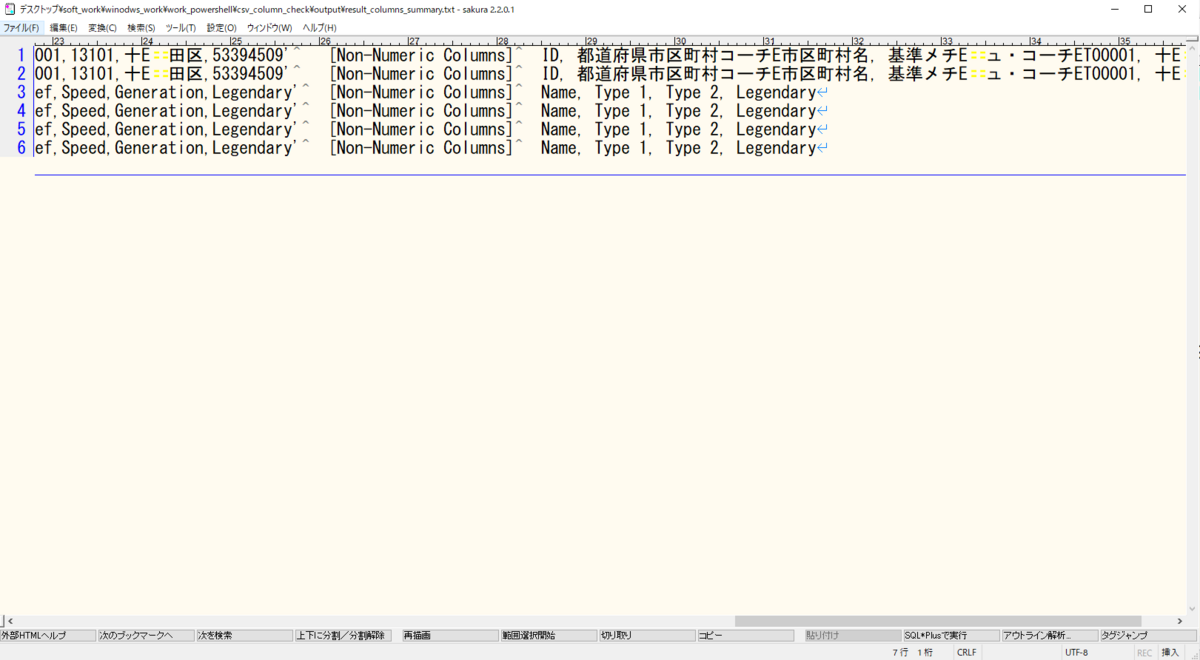
⇧ 上記の結果を、Excelなどに転記して、同一のCSVヘッダーのCSVファイルで数値のみの列(カラム)の数が異なっているかどうかなどを比較するぐらいしか、どの列(カラム)に数値以外が混入しているのか検証のしようがないような気がする。
一度に調査する対象のCSVファイルは、Excelで許容されてる行数に収める必要はあるけど...
Excelの仕様を確認する限り、
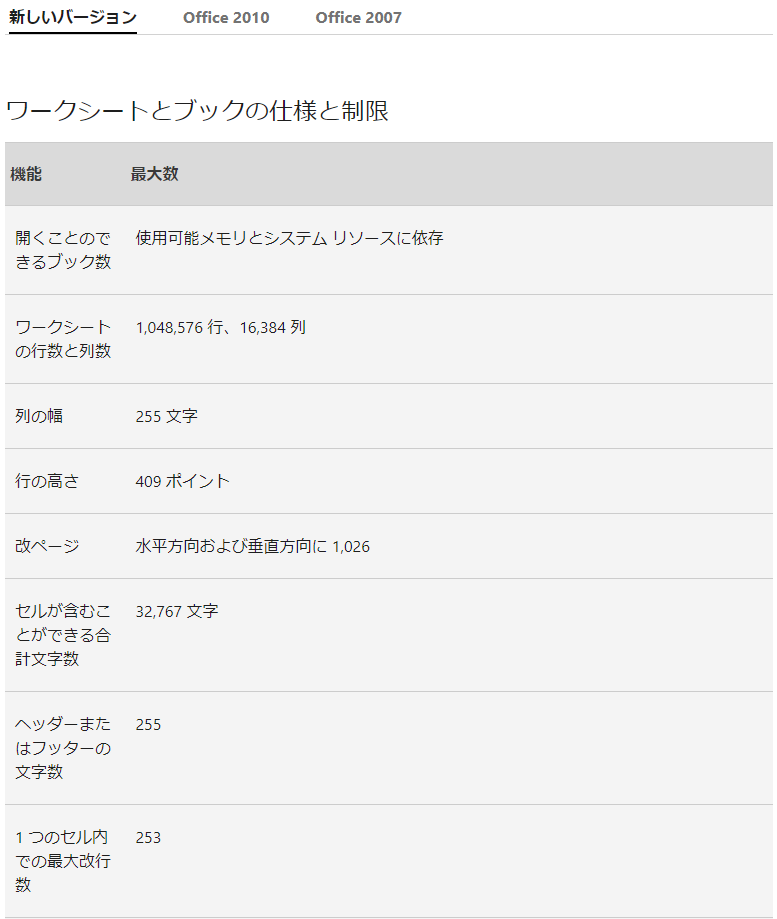
⇧ 1048576行が上限らしいので、調査対象のCSVファイルについては、ザックリ100万ファイル毎に、フォルダに分ける必要はあると。
調査対象のCSVファイルの数が、1000万ぐらいまでであり、且つ、日本語を含まないのであれば、今回のPowerShellのスクリプトで何とか調査を進められそうですが、調査対象のファイルの数が1億以上とかになってくると、スクリプトでCSVヘッダーが同一のファイル同士で列(カラム)の数の差分比較とかまで実装する必要がありますな。
あと、必須項目では無い列(カラム)だと、空白の値が出てくるから、空白だった場合をどういう判定にするかは悩みどころですな...
空白は、今回の数値かどうかを知りたいという意味ではノイズになるから(必須チェックをしたいわけではない)、数値と見なして、無視してしまうという考えもあるとは思うけど...
それにしても、これといった情報が見つからず、とりあえず動くものを実現するのに難航した調査&試行錯誤を経たわけですが、改めて、う~む、PowerShell 何も分からん...
参考にさせていただいたサイト様
■CSVファイルの読み込み
■CSVヘッダーを取得する
■列(カラム)が数値か判定
■列(カラム)毎に処理する
何と言うか、PowerShell の扱い辛さ、何とかならんもんか...
Microsoftさんのソフトだから使い辛いのは致し方ないのかな...
今時は、PowerShell が利用される機会がほぼほぼ無いってことなんですかね?
まぁ、PowerShell はコーディングの癖が強過ぎるんよなぁ...
Import-Csvとかいう処理に至っては、CSVのヘッダーが重複してたらエラーになるとか、意味分からん仕様になってるみたいだし...
ChatGPTを駆使しつつもPowerShellでの実現方法の調査に何やかんやで、2週間ぐらい時間を無駄にしましたかね...
とりあえず、「IF(インターフェイス)定義書」があると、どの列(カラム)を確認すれば良いのか絞り込みやすいんだけどなぁ、と思うなどした。
列(カラム)のデータ型が分かれば、全く見当ちがいな対象について調査対象から外したりして調査時間を削減できたりもしますし...
エラーログから障害の原因が分かるのが一番ではあるんですが、エラーログで肝心なことが出力されないことはあるあるですからな...
毎度モヤモヤ感が半端ない...
今回はこのへんで。