
地球外生命の探究史の中では、火星のメタンや金星のホスフィンなど、生命の痕跡と期待される発見が数多くなされてきましたが、残念ながら確固たる証拠となるものはなく、依然として人類は宇宙で孤独な存在だと考えられています。ケンブリッジ大学の天文学者らのチームが、慎重な姿勢を保ちながらも、地球外での生物活動を示唆するものとしてはこれまでで最も強い化学的痕跡を検出したことを発表しました。
ケンブリッジ大学天文学研究所のニック・マドゥスダン教授らは、2025年4月16日に学術雑誌・The Astrophysical Journal Lettersに掲載された論文で、地球からしし座の方向に約124光年離れた位置にある惑星のK2-18bの大気中から、有機硫黄化合物であるジメチルスルフィド(DMS)と、ジメチルジスルフィド(DMDS)が検出されたと報告しました。
地球におけるDMSとDMDSの唯一の発生源は生命で、主に海洋性の植物プランクトンなどの微生物によって生成されます。研究チームは観測結果を有望視しており、統計的有意性を「3σ(シグマ)」、つまり誤検知の可能性はわずか0.3%と見積もりました。これは、科学的な証拠として認められるのに必要な「5σ(0.00006%未満)」を下回るものの、太陽系外惑星の生命の兆候としてこれまでで最も強力な結果です。
⇧ 何と言うか『科学的な証拠として認められるのに必要な「5σ(0.00006%未満)」』がいつ頃に確立されたのかが分からないので何とも言えないのだが、従来の説が覆ることが往々にしてあることから、『「5σ(0.00006%未満)」』の「統計的有意性」という指標にどれほどの効果があるのかは皆目見当が付かない...
故に『研究チームは観測結果を有望視しており、統計的有意性を「3σ(シグマ)」、つまり誤検知の可能性はわずか0.3%と見積もりました。』がどの程度、説得力があるのかサッパリ分かりませんな...
Excelファイルのデータを元にYAMLファイルを生成したかったのだが...
前回、
⇧ 上記の記事で、Excelの列の値の日本語名をアンダースコア区切りの英語名に変換しましたと。
まぁ、翻訳し切れない部分が出て来てましたが...
で、次なる課題としては、「Ansible」での処理で「Excel」ファイルを読み込む「モジュール」は用意されておらず、ファイルのフォーマットを変更する必要性があるのだが、
あたりの変換が候補として上がってきそう。
とりあえず、「Ansible」が「YAML」をベースにしていそうなこともあったので、「Excel」から「YAML」に変換する方針で進めてみたのだが、
⇧ まさかの、YAMLファイルのvalueに何も設定しないというのが実現できないという...
つまり、何かしら、設定が必須になると...
とりあえず、「Python仮想環境」にログインし「Python」の「ライブラリ」を追加でインストール。
■pyyamlのインストール
pip install pyyaml

ソースコードを修正・追記。
D:\work-soft\python\auto_translate\src\translate.py
import pandas as pd
from deep_translator import GoogleTranslator
import inflection
import os
import pprint
import yaml
import numpy as np
from collections import OrderedDict
from yaml import SafeDumper
# OrderedDictを使った順序維持
def represent_odict(dumper, instance):
return dumper.represent_mapping(u'tag:yaml.org,2002:map', instance.items())
def construct_odict(loader, node):
return OrderedDict(loader.construct_pairs(node))
yaml.add_representer(OrderedDict, represent_odict)
yaml.add_constructor(u'tag:yaml.org,2002:map', construct_odict)
# SafeDumper.add_representer(
# type(None),
# lambda dumper, value: dumper.represent_scalar(u'tag:yaml.org,2002:null', '')
# )
def convert_and_export_excel_headers(input_file, output_file):
# 元のExcelファイル読み込み
df = pd.read_excel(input_file, sheet_name='パラメーターシート', header=0, skiprows=4) # シート名は必要に応じて変更
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# 直前の英語の大項目を保存する変数
prev_translated_second_value = None
# セルが空でない部分のみ翻訳
translated_second_column = []
translated_third_column = []
for i in range(len(second_column)):
# 2列目(日本語)翻訳
if pd.notna(second_column[i]):
translated_second_value = GoogleTranslator(source='auto', target='en').translate(second_column[i])
prev_translated_second_value = translated_second_value # 翻訳後の値を保存
translated_second_column.append(translated_second_value)
else:
# 空の場合、直前に翻訳された値を使用
translated_second_column.append(prev_translated_second_value)
# 3列目(日本語)翻訳
if pd.notna(third_column[i]):
translated_third_column.append(GoogleTranslator(source='auto', target='en').translate(third_column[i]))
else:
translated_third_column.append('') # 3列目が空の場合、空文字列として保持
# 2列目と3列目に対するスネークケース変換
snake_case_translated_second_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_second_column
]
snake_case_translated_third_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_third_column
]
# スネークケースに変換されたデータを元のDataFrameに戻す
df.iloc[:, 1] = snake_case_translated_second_column
df.iloc[:, 2] = snake_case_translated_third_column
# 新しいExcelファイルに書き出す
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='パラメーターシート', index=False)
print(f"変換結果を '{output_file}' に書き出しました。")
def convert_excel_to_yaml(output_file, yaml_file):
# 翻訳後のExcelファイル読み込み
df = pd.read_excel(output_file, sheet_name='パラメーターシート', header=0)
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# YAMLファイル作成用のデータ構造(OrderedDictを使用)
yaml_data = OrderedDict() # ここでOrderedDictを使うことで順序を保持します
current_second_key = None # 前回の2列目の値を保持
for i in range(len(df)):
second_value = second_column[i]
third_value = third_column[i]
fourth_value = fourth_column[i]
print(fourth_value)
# 初回の処理(i == 0)の場合
if i == 0:
current_second_key = second_value # 最初の値で current_second_key を初期化
yaml_data[current_second_key] = OrderedDict() # 最初の大項目を作成
elif second_value != current_second_key: # 2列目(second_column)の値が変わった場合
current_second_key = second_value # 新しい大項目が出てきた
yaml_data[current_second_key] = OrderedDict()
# 3列目(third_column)の値をスネークケースに変換
snake_case_third_value = third_value.replace(" ", "_").lower() if pd.notna(third_value) else ''
# 4列目(fourth_column)の値が NaN でない場合に格納
if pd.notna(fourth_value):
yaml_data[current_second_key][snake_case_third_value] = fourth_value
else:
yaml_data[current_second_key][snake_case_third_value] = None
# YAMLファイルに出力
with open(yaml_file, 'w', encoding='utf-8') as f:
yaml.dump(yaml_data, f, default_flow_style=False, allow_unicode=True)
print(f'YAMLファイルを {yaml_file} に書き出しました。')
# メソッドの呼び出し部分
if __name__ == "__main__":
# 入力ファイルのパスと出力ファイルのパスを指定
input_file = r'D:\work-soft\python\auto_translate\デリバリ情報.xlsx' # 実際の入力ファイルのパスに変更
output_file = r'D:\work-soft\python\auto_translate\【Done】デリバリ情報.xlsx' # 出力ファイルのパスに変更
yaml_file = r'D:\work-soft\python\auto_translate\output.yaml' # YAML出力先のファイルパス
# ファイルが存在するか確認
if not os.path.exists(input_file):
print(f"入力ファイル '{input_file}' が存在しません。")
else:
# メソッドを呼び出して処理を実行
convert_and_export_excel_headers(input_file, output_file)
convert_excel_to_yaml(output_file, yaml_file)
で、実行。
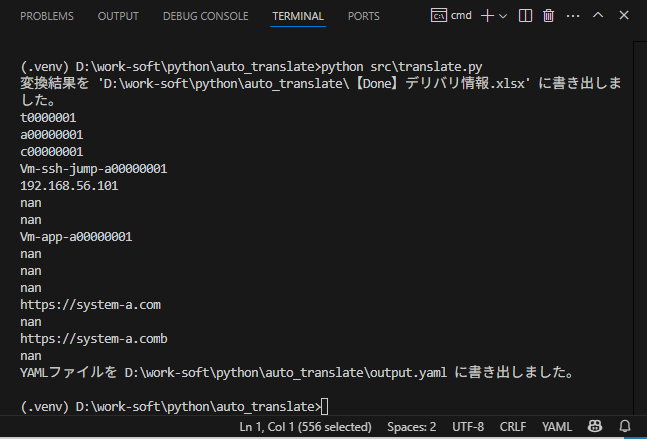
出力されたYAMLファイル
■D:\work-soft\python\auto_translate\output.yaml
案件情報: contract_id: t0000001 case_id: a00000001 企業id: c00000001 stool_server: server_name: Vm-ssh-jump-a00000001 ip_address: 192.168.56.101 ssh_users: null material_placement_directory: null application_server: server_name: Vm-app-a00000001 ip_address: null ssh_users: null transfer_destination_directory: null application_settings: base_a_access_url: https://system-a.com fundamental_a_access_authentication_token: null base_b_access_url: https://system-a.comb fundamental_b_access_authentication_token: null

⇧ 翻訳できない部分が増えてますな...
そして、nullとかも不要なんだが...
それにしても、YAMLファイルのvalueに何も設定しないというのが実現できないというのは最早、欠陥と言っても過言ではない気がするんだが...
Python標準とPyYAMLで方針が異なるという罠
YAMLファイルに出力される順序が維持されない問題で、ネットの情報を漁っていたのだが、


⇧ とあるのだが、いずれも、自分の環境では順序が維持されないという...
ちなみに、利用している「Python」のバージョンは、3.13.3となっているので、3.7以降という要件は満たしているはずなんだが...
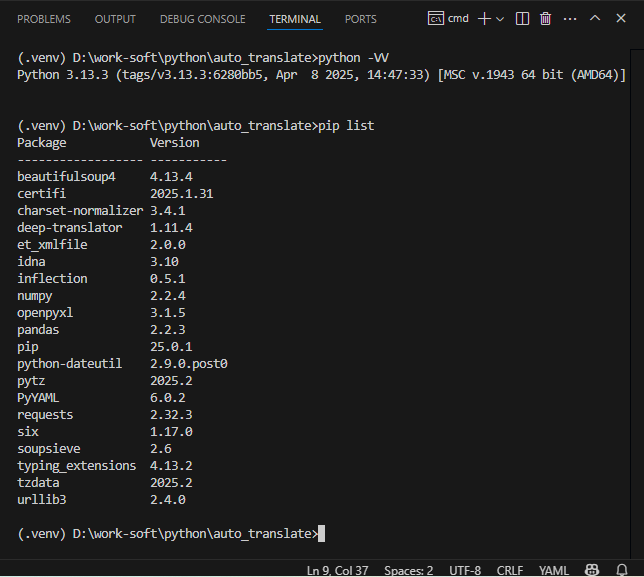
2025年4月19日(土)時点の「Python」のバージョンを確認してみても、

⇧ 新しめのバージョンを利用していると思うんだが...
■D:\work-soft\python\auto_translate\src\translate.py
import pandas as pd
from deep_translator import GoogleTranslator
import inflection
import os
import pprint
import yaml
import numpy as np
from collections import OrderedDict
from yaml import SafeDumper
# OrderedDictを使った順序維持
# def represent_odict(dumper, instance):
# return dumper.represent_mapping(u'tag:yaml.org,2002:map', instance.items())
# def construct_odict(loader, node):
# return OrderedDict(loader.construct_pairs(node))
# yaml.add_representer(OrderedDict, represent_odict)
# yaml.add_constructor(u'tag:yaml.org,2002:map', construct_odict)
# SafeDumper.add_representer(
# type(None),
# lambda dumper, value: dumper.represent_scalar(u'tag:yaml.org,2002:null', '')
# )
def convert_and_export_excel_headers(input_file, output_file):
# 元のExcelファイル読み込み
df = pd.read_excel(input_file, sheet_name='パラメーターシート', header=0, skiprows=4) # シート名は必要に応じて変更
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# 直前の英語の大項目を保存する変数
prev_translated_second_value = None
# セルが空でない部分のみ翻訳
translated_second_column = []
translated_third_column = []
for i in range(len(second_column)):
# 2列目(日本語)翻訳
if pd.notna(second_column[i]):
translated_second_value = GoogleTranslator(source='auto', target='en').translate(second_column[i])
prev_translated_second_value = translated_second_value # 翻訳後の値を保存
translated_second_column.append(translated_second_value)
else:
# 空の場合、直前に翻訳された値を使用
translated_second_column.append(prev_translated_second_value)
# 3列目(日本語)翻訳
if pd.notna(third_column[i]):
translated_third_column.append(GoogleTranslator(source='auto', target='en').translate(third_column[i]))
else:
translated_third_column.append('') # 3列目が空の場合、空文字列として保持
# 2列目と3列目に対するスネークケース変換
snake_case_translated_second_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_second_column
]
snake_case_translated_third_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_third_column
]
# スネークケースに変換されたデータを元のDataFrameに戻す
df.iloc[:, 1] = snake_case_translated_second_column
df.iloc[:, 2] = snake_case_translated_third_column
# 新しいExcelファイルに書き出す
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='パラメーターシート', index=False)
print(f"変換結果を '{output_file}' に書き出しました。")
def convert_excel_to_yaml(output_file, yaml_file):
# 翻訳後のExcelファイル読み込み
df = pd.read_excel(output_file, sheet_name='パラメーターシート', header=0)
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# YAMLファイル作成用のデータ構造(OrderedDictを使用)
# yaml_data = OrderedDict() # ここでOrderedDictを使うことで順序を保持します
yaml_data: dict = {}
current_second_key = None # 前回の2列目の値を保持
for i in range(len(df)):
second_value = second_column[i]
third_value = third_column[i]
fourth_value = fourth_column[i]
print(fourth_value)
# 初回の処理(i == 0)の場合
if i == 0:
current_second_key = second_value # 最初の値で current_second_key を初期化
# yaml_data[current_second_key] = OrderedDict() # 最初の大項目を作成
yaml_data[current_second_key]: dict = {}
elif second_value != current_second_key: # 2列目(second_column)の値が変わった場合
current_second_key = second_value # 新しい大項目が出てきた
# yaml_data[current_second_key] = OrderedDict()
yaml_data[current_second_key]: dict = {}
# 3列目(third_column)の値をスネークケースに変換
snake_case_third_value = third_value.replace(" ", "_").lower() if pd.notna(third_value) else ''
# 4列目(fourth_column)の値が NaN でない場合に格納
if pd.notna(fourth_value):
yaml_data[current_second_key][snake_case_third_value] = fourth_value
else:
yaml_data[current_second_key][snake_case_third_value] = None
# YAMLファイルに出力
with open(yaml_file, 'w', encoding='utf-8') as f:
# yaml.dump(yaml_data, f, default_flow_style=False, allow_unicode=True)
yaml.safe_dump(yaml_data, f, default_flow_style=False, allow_unicode=True)
print(f'YAMLファイルを {yaml_file} に書き出しました。')
# メソッドの呼び出し部分
if __name__ == "__main__":
# 入力ファイルのパスと出力ファイルのパスを指定
input_file = r'D:\work-soft\python\auto_translate\デリバリ情報.xlsx' # 実際の入力ファイルのパスに変更
output_file = r'D:\work-soft\python\auto_translate\【Done】デリバリ情報.xlsx' # 出力ファイルのパスに変更
yaml_file = r'D:\work-soft\python\auto_translate\output.yaml' # YAML出力先のファイルパス
# ファイルが存在するか確認
if not os.path.exists(input_file):
print(f"入力ファイル '{input_file}' が存在しません。")
else:
# メソッドを呼び出して処理を実行
convert_and_export_excel_headers(input_file, output_file)
convert_excel_to_yaml(output_file, yaml_file)
で、実行。
■出力されたExcelファイル

■出力されたYAMLファイル

■D:\work-soft\python\auto_translate\output.yaml
application_server: ip_address: null server_name: Vm-app-a00000001 ssh_users: null transfer_destination_directory: null application_settings: base_a_access_url: https://system-a.com base_b_access_url: https://system-a.comb fundamental_a_access_authentication_token: null fundamental_b_access_authentication_token: null stool_server: ip_address: 192.168.56.101 material_placement_directory: null server_name: Vm-ssh-jump-a00000001 ssh_users: null 案件情報: case_id: a00000001 contract_id: t0000001 企業id: c00000001
⇧ 並び順が維持されていないんだが...
何やら、

https://stackoverflow.com/questions/5121931/in-python-how-can-you-load-yaml-mappings-as-ordereddicts

https://stackoverflow.com/questions/5121931/in-python-how-can-you-load-yaml-mappings-as-ordereddicts
⇧ とありますと。
『In python 3.6+, it seems that dict loading order is preserved by default without special dictionary types. The default Dumper, on the other hand, sorts dictionaries by key. Starting with pyyaml 5.1, you can turn this off by passing sort_keys=False:』
『Note that this is still undocumented from PyYAML side, so you shouldn't rely on this for safety critical applications.』
足並みを揃えて欲しいんだが...
stackoverflowの情報にあるように、「yaml.safe_dump」の引数で「sort_keys=False」を指定するということを反映したところ、
■D:\work-soft\python\auto_translate\src\translate.py
import pandas as pd
from deep_translator import GoogleTranslator
import inflection
import os
import pprint
import yaml
import numpy as np
from collections import OrderedDict
from yaml import SafeDumper
# OrderedDictを使った順序維持
# def represent_odict(dumper, instance):
# return dumper.represent_mapping(u'tag:yaml.org,2002:map', instance.items())
# def construct_odict(loader, node):
# return OrderedDict(loader.construct_pairs(node))
# yaml.add_representer(OrderedDict, represent_odict)
# yaml.add_constructor(u'tag:yaml.org,2002:map', construct_odict)
# SafeDumper.add_representer(
# type(None),
# lambda dumper, value: dumper.represent_scalar(u'tag:yaml.org,2002:null', '')
# )
def convert_and_export_excel_headers(input_file, output_file):
# 元のExcelファイル読み込み
df = pd.read_excel(input_file, sheet_name='パラメーターシート', header=0, skiprows=4) # シート名は必要に応じて変更
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# 直前の英語の大項目を保存する変数
prev_translated_second_value = None
# セルが空でない部分のみ翻訳
translated_second_column = []
translated_third_column = []
for i in range(len(second_column)):
# 2列目(日本語)翻訳
if pd.notna(second_column[i]):
translated_second_value = GoogleTranslator(source='auto', target='en').translate(second_column[i])
prev_translated_second_value = translated_second_value # 翻訳後の値を保存
translated_second_column.append(translated_second_value)
else:
# 空の場合、直前に翻訳された値を使用
translated_second_column.append(prev_translated_second_value)
# 3列目(日本語)翻訳
if pd.notna(third_column[i]):
translated_third_column.append(GoogleTranslator(source='auto', target='en').translate(third_column[i]))
else:
translated_third_column.append('') # 3列目が空の場合、空文字列として保持
# 2列目と3列目に対するスネークケース変換
snake_case_translated_second_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_second_column
]
snake_case_translated_third_column = [
inflection.underscore(str(cell).strip().replace(' ', '_')).lower() if pd.notna(cell) else ""
for cell in translated_third_column
]
# スネークケースに変換されたデータを元のDataFrameに戻す
df.iloc[:, 1] = snake_case_translated_second_column
df.iloc[:, 2] = snake_case_translated_third_column
# 新しいExcelファイルに書き出す
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='パラメーターシート', index=False)
print(f"変換結果を '{output_file}' に書き出しました。")
def convert_excel_to_yaml(output_file, yaml_file):
# 翻訳後のExcelファイル読み込み
df = pd.read_excel(output_file, sheet_name='パラメーターシート', header=0)
# 2列目、3列目、4列目を取得(インデックス1が2列目、インデックス2が3列目、インデックス3が4列目)
second_column = df.iloc[:, 1] # 大項目(2列目)
third_column = df.iloc[:, 2] # パラメーター名(3列目)
fourth_column = df.iloc[:, 3] # パラメーター(4列目)
# YAMLファイル作成用のデータ構造(OrderedDictを使用)
# yaml_data = OrderedDict() # ここでOrderedDictを使うことで順序を保持します
yaml_data: dict = {}
current_second_key = None # 前回の2列目の値を保持
for i in range(len(df)):
second_value = second_column[i]
third_value = third_column[i]
fourth_value = fourth_column[i]
print(fourth_value)
# 初回の処理(i == 0)の場合
if i == 0:
current_second_key = second_value # 最初の値で current_second_key を初期化
# yaml_data[current_second_key] = OrderedDict() # 最初の大項目を作成
yaml_data[current_second_key]: dict = {}
elif second_value != current_second_key: # 2列目(second_column)の値が変わった場合
current_second_key = second_value # 新しい大項目が出てきた
# yaml_data[current_second_key] = OrderedDict()
yaml_data[current_second_key]: dict = {}
# 3列目(third_column)の値をスネークケースに変換
snake_case_third_value = third_value.replace(" ", "_").lower() if pd.notna(third_value) else ''
# 4列目(fourth_column)の値が NaN でない場合に格納
if pd.notna(fourth_value):
yaml_data[current_second_key][snake_case_third_value] = fourth_value
else:
yaml_data[current_second_key][snake_case_third_value] = None
# YAMLファイルに出力
with open(yaml_file, 'w', encoding='utf-8') as f:
# yaml.dump(yaml_data, f, default_flow_style=False, allow_unicode=True)
yaml.safe_dump(yaml_data, f, default_flow_style=False, allow_unicode=True, sort_keys=False)
print(f'YAMLファイルを {yaml_file} に書き出しました。')
# メソッドの呼び出し部分
if __name__ == "__main__":
# 入力ファイルのパスと出力ファイルのパスを指定
input_file = r'D:\work-soft\python\auto_translate\デリバリ情報.xlsx' # 実際の入力ファイルのパスに変更
output_file = r'D:\work-soft\python\auto_translate\【Done】デリバリ情報.xlsx' # 出力ファイルのパスに変更
yaml_file = r'D:\work-soft\python\auto_translate\output.yaml' # YAML出力先のファイルパス
# ファイルが存在するか確認
if not os.path.exists(input_file):
print(f"入力ファイル '{input_file}' が存在しません。")
else:
# メソッドを呼び出して処理を実行
convert_and_export_excel_headers(input_file, output_file)
convert_excel_to_yaml(output_file, yaml_file)


■D:\work-soft\python\auto_translate\output.yaml
案件情報: contract_id: t0000001 case_id: a00000001 企業id: c00000001 stool_server: server_name: Vm-ssh-jump-a00000001 ip_address: 192.168.56.101 ssh_users: null material_placement_directory: null application_server: server_name: Vm-app-a00000001 ip_address: null ssh_users: null transfer_destination_directory: null application_settings: base_a_access_url: https://system-a.com fundamental_a_access_authentication_token: null base_b_access_url: https://system-a.comb fundamental_b_access_authentication_token: null
⇧ 順序が維持されたっぽい。
ネットの情報が錯綜し過ぎなんよね...
いずれにしろ、YAMLファイルのvalueに何も設定しないということが実現できないという欠陥は解決方法が無いようだが...
ちなみに、



⇧「Python」の標準ライブラリとしては、YAMLを扱えるものが無いようだ...
「Ansible」とかでも「PyYAML」が利用されているらしい。
他にも、

⇧「YAML」に依存しているライブラリがあるっぽい。
そして、「TOML」の方は「Python」の標準ライブラリに追加されたらしい。


⇧「Python」以外のプログラミング言語でもサポートされているらしいのだが、「YAML」に依存しているライブラリは、いまさら「TOML」を利用する形にリファクタリングする気が無いような気がするのだが...
ちなみに、「Java」の「フレームワーク」である「Spring Boot」の話になるのだが、
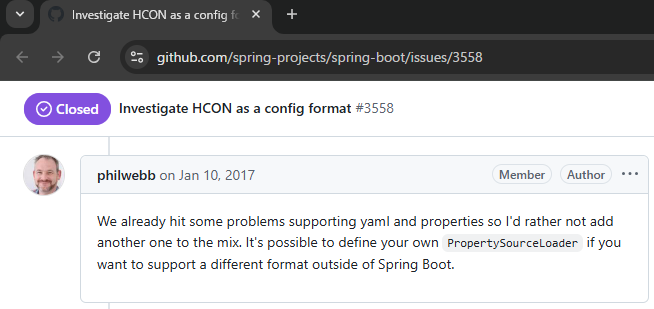
⇧「Spring Boot」の開発に関わっている人の話だと、「YAML」の導入でも問題が起こっていると言っており、他のフォーマットをサポートする余裕は無さそうではある。
「Kubernetes」とかも「YAML」ファイルを利用してた気がしますし、「YAML」に依存しているライブラリが数多くあるのだから「Python」の標準ライブラリとして「TOML」をサポートする前段階として、「YAML」をサポートして欲しかった...
面倒な部分は、「ライブラリ」や「フレームワーク」側で吸収して、利用者側が気にする必要が無いように隠蔽して欲しい気はするが、「ブラックボックス」な部分が増えることの方が多い気もするので悩ましいところですな...
「ライブラリ」や「フレームワーク」が対応に付いていけないような「標準」の追加は避けて欲しいのだが...
所謂「破壊的変更」に見合うだけのメリットがあるのかが分からないと、対応する気にならないと思いますし...
毎度モヤモヤ感が半端ない…
今回はこのへんで。