
最近、スイスのヌーシャテル大学(University of Neuchatel)に所属するパトリック・グロフティザ氏ら研究チームは、メキシコの混作(2種類以上の作物を同じ畑で同時に栽培する)にて、トウモロコシの悲鳴をマメが聞いていることを報告しました。
⇧ amazing...
トウモロコシがアラートを上げて、マメ科植物が検知して対応しているとは、想像を絶しますな。
異常検知とは
Wikipediaによると、
異常検知(いじょうけんち、英: anomaly detection)や外れ値検知(はずれちけんち、英: outlier detection)とは、データマイニングにおいて、期待されるパターンまたはデータセット中の他のアイテムと一致しないアイテムやイベントや観測結果を識別すること。
異常検知技術には大きく分けて3通りの分類がある。
教師なし異常検知(unsupervised anomaly detection)手法は、データセット内のインスタンスの大多数は正常であるという仮定の下でデータセットの残りにほとんどフィットしないと思われるインスタンスを探すことによって、ラベル付されていないテストデータセットにある異常を見つける。
教師あり異常検知(supervised anomaly detection)手法は「正常」と「異常」にラベル付されたデータセットを必要とし、分類器を訓練することを含む(他の多くの統計分類問題との決定的な違いは固有の外れ値検出の不均衡な性質である)。
半教師あり異常検知(semi-supervised anomaly detection)手法は与えられた正常な訓練データセットから正常な振る舞いを表すモデルを構成し、そして学習したモデルによって生成されるテストインスタンスの尤度をテストする。
適用例
異常検知は、侵入検知システム、詐欺検知、文書中の誤り検出、不審な行動検出、機械の故障検知、システムヘルスモニタリング、センサネットワークのイベント検知、生態系の乱れの検知など、様々な分野に応用できる。データセットから異常なデータを除去するための前処理でしばしば使われる。教師あり学習では、データセットから異常なデータを除去することはしばしば精度の統計的に有意な増加をもたらす。
⇧ とあり、「データマイニング」における活用について言及されている。
機械学習、深層学習、強化学習、いずれでも異常検知ができるらしい
ネット上で公開されている『深層学習を用いた異常検知技術 A Review on Anomaly Detection Techniques using Deep Learning』という論文によると、
近年,深層学習に代表される機械学習が様々な分野に おいて大きな発展を遂げており,異常検知分野への実用化・適用研究が活発に進められている。
https://www.jstage.jst.go.jp/article/jsms/69/9/69_650/_pdf/-char/ja
異常検知 (Anomaly detection)は,主に品質管理(Quality Control) を目的に発展してきたと言われ,統計学において一世紀 近い歴史を有する伝統分野である。一方で,システムや 物理現象に対する異常検知が注目されてきたのは,インターネットが社会に浸透し始めた 1990 年以降であり, 計算機,ネットワークおよびセンサ技術の発展とともに, 現在,オンラインで対象を監視し異常検知を行う需要が高まってきている。
https://www.jstage.jst.go.jp/article/jsms/69/9/69_650/_pdf/-char/ja
⇧ とあり、そもそも「統計学」で発展してきたらしく、Wikipediaの情報が適当なのか、情報が錯綜していますと。そして、「深層学習」による「異常検知」も可能でありますと。
『機械学習を用いたネットワーク異常検知技術の WebAPI 化の研究』という論文によると、
あらまし 将来的な労働人口の減少に備えるため,ネットワークの障害対応の自動化が急務である。障害対応の自動化には,トリガとなる異常検知技術が欠かせない。
https://search.ieice.org/bin/pdf_link.php?category=B&lang=J&year=2019&fname=j102-b_5_343&abst=
一方近年,機械学習による異常検知技術の研究が盛んである。
しかし現状,ネットワークでこのような技術は普及していない。原因は次の二つである。
https://search.ieice.org/bin/pdf_link.php?category=B&lang=J&year=2019&fname=j102-b_5_343&abst=
(1) ネットワーク事業者にとって,検知対象に応じて複数の検知技術を導入する場合,技術に応じたデータ収集/前処理等の開発が必要である。
https://search.ieice.org/bin/pdf_link.php?category=B&lang=J&year=2019&fname=j102-b_5_343&abst=
(2) 検知技術開発者にとって,検知技術をネットワークで利用可能な技術に仕上げるには,ネットワークに関する機能/非機能要件も満たす必要がある。
https://search.ieice.org/bin/pdf_link.php?category=B&lang=J&year=2019&fname=j102-b_5_343&abst=
本論文ではこれらの障壁を解消する,異常検知技術の WebAPI 化ラッパの構成を提案する。ラッパは (1) ネットワークに対して共通の WebAPI の IF を提供し,1 回の開発で複数技術を導入可能とする。一方 (2) ラッパでの実装を肩代わりし,各検知技術の開発の障壁も解消する。ラッパを実装し,実際の検知技術を WebAPI 化することで,少ない工数でネットワークに導入できることを確認した。
また,検知技術をネットワークに対応させるためのプログラム変更は難易度の低いものであった。一方,ラッパによる実行時間のオーバーヘッドは,実測により許容範囲であると確認した。
https://search.ieice.org/bin/pdf_link.php?category=B&lang=J&year=2019&fname=j102-b_5_343&abst=
⇧ とあるように、「機械学習」における「異常検知」も可能でありますと。
「ベイジアン逆強化学習を用いた異常前兆予測検知手法の開発」という論文によると、
異常検出で最も興味深いアプリケーションシナリオの1つは、シーケンシャルデータが対象となる場合である。たとえば安全性が重視される環境において、監視センサーにより収集されたストリーミングデータのスクリーニングからリアルタイムで異常が検出された場合、異常な観測を報告する自動検出システムが不可欠となる。しかしながら、これらの潜在的な異常が意図的または目標指向である場合、前兆予測が重要となるにも関わらず、現状では有効な検出手法は確立されていない。そこで我々は、逆強化学習(IRL)を使用した前兆を含めたシーケンシャルな異常検出のためのエンドツーエンドのフレームワークを提案する。
https://www.jstage.jst.go.jp/article/pjsai/JSAI2020/0/JSAI2020_2J6GS202/_article/-char/ja/
⇧ とあるように、「強化学習」における「異常検知」も可能でありますと。
AI、機械学習、深層学習、強化学習など、どういった分類になっているか
そもそも、分類がカオスと化してる気がするのだけど、総務省が公開している情報だと令和元年から後進されていない...
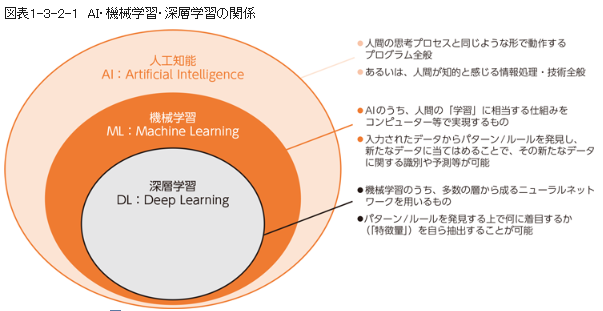
⇧「強化学習」すら反映されていないという哀しみ...
「カーネギーメロン大学」が公開してる「Principles of Generative AI A Technical Introduction」というPDFによると、
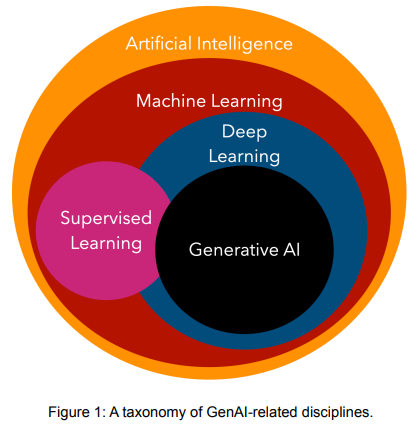
⇧ 上図のような感じで、「生成AI(Generative AI)」が入ってきたりしてますな。
他にも、

⇧ 上図のような感じのベン図が公開されていたりと、収拾が付かない状態ですと。
う~む、分類を正しく整理した情報を公開して欲しい...
異常検知の対象とするデータ
ネット上の情報を漁った感じでは、

⇧ 上記サイト様によりますと、大きく分けて、
- 画像
- 時系列データ
⇧ 2つに分類されるそうな。
⇧ 上記の3つの観点があるらしい。
異常検知で利用されるアルゴリズムは4つに大別されるらしい
ネットの情報によりますと、
アルゴリズムは大きく4つのアプローチにより分類できます。それぞれ、Classification Approach, Probabilistic Approach, Reconstruction Approach, Distance Approachです。この4つの分類に加えて、ディープラーニングを用いるか否かで分類をした表がこちらになります:
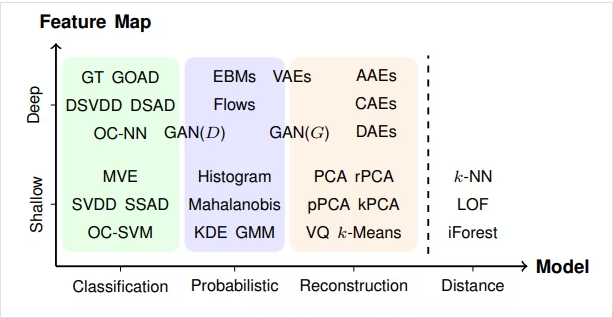
⇧ 上記サイト様によりますと、
- Classification
- Probabilistic
- Reconstruction
- Distance
の4つに大別されるらしく、「4. Distance」以外は、「機械学習」だけでなく「深層学習」にも対応してるってことですかね?
Pythonで時系列データの異常検知のライブラリどんなものがあるのか
で、一般的には、ライブラリを利用することになると思うのですが、どんなライブラリを利用するのが良いのか分からない...
ネット上の情報を漁ってみたところ、
⇧ 上記サイト様によりますと、
- ruptures
- Prophet
- scikit-learn
のいずれかが、利用されることが多いんですかね?
「Python 時系列データ 異常検知 ライブラリ」とかで検索したら、上位表示されていたので。
⇧「rupturres」、「prophet」は、開発が活発ではなくなってきてる感はありますが。
ライブラリ「scikit-learn」のどの機能で「異常検知」が実現できるのか?
とりあえず、「scikit-learn」で試してみることにして、参考サイト様の情報だと、「k近傍法」を利用する感じになると。
「k近傍法」はというと、
パターン認識(分類・回帰)でよく使われる。最近傍探索問題の一つ。k近傍法は、インスタンスに基づく学習の一種であり、怠惰学習 の一種である。その関数は局所的な近似に過ぎず、全ての計算は分類時まで後回しにされる。また、回帰分析にも使われる。
⇧ とあり、使われ方として、大きく分けて、
- パターン認識(分類・回帰)
- 回帰分析
の2つに大別できるとありますな。
k近傍法とは、学習データをベクトル空間上にプロットし、未知データ(入力データ)と学習データの距離が近い順に任意のK個を取得し、多数決でデータが属するクラスを推定するです。
比較的シンプルなアルゴリズムですが、時系列データの異常検知にも活用できます。
⇧ うむ、
- パターン認識(分類・回帰)
- 回帰分析
どっちを想定しているのか分からん...
参考サイト様によりますと、
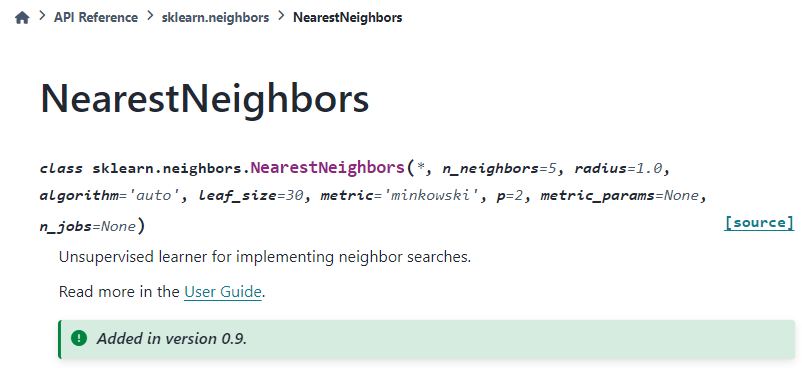
⇧ 上記のAPIを利用しているらしく、
『Unsupervised learner for implementing neighbor searches.』
とのことですが、結局、
- パターン認識(分類・回帰)
- 回帰分析
どっちを想定しているのか分からん...
時系列データは2つに大別されるらしく、「スライド窓」が利用されることが多いらしい
で、「時系列データ」はというと、「東京大学 数理・情報教育研究センター」が公開しているドキュメントによると、
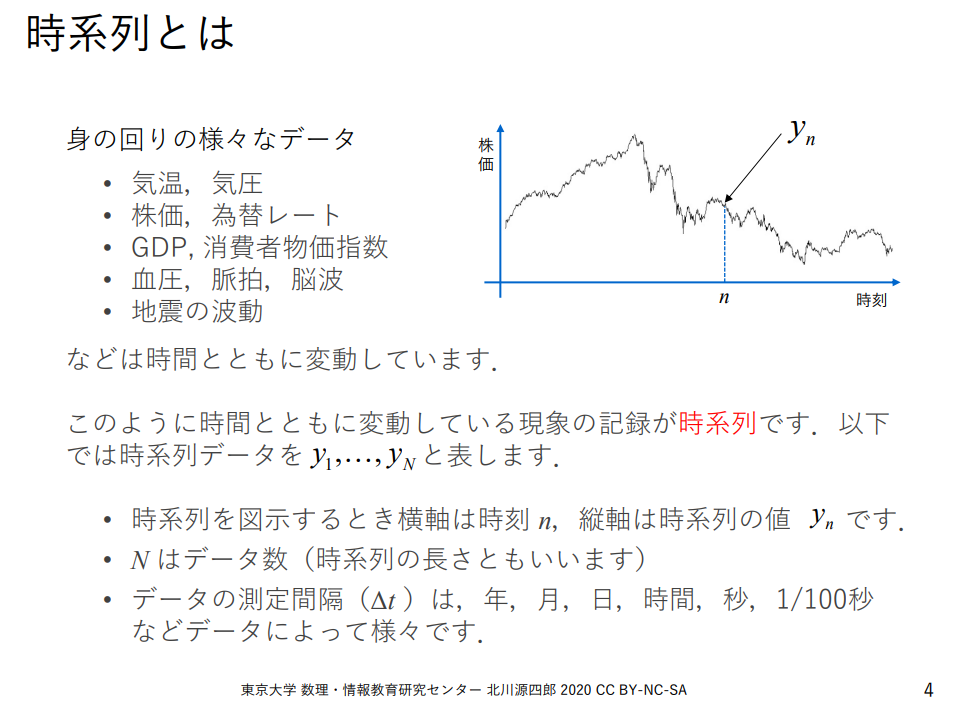

⇧ とあり、
- 時系列データ
- 多変量時系列データ
- 非多変量時系列データ
2つに大別できるということですかね。
で、
テキストで初めて知った「スライド窓」。
「窓」は時系列データの移動平均を取る際の「窓」(window)と同じ意味だと思います。
「Pythonによる異常検知」を寄り道写経 ~ 第3章3.5節「時系列データにおける異常検知」機械学習編①スライド窓k近傍法|ネイピア DS
多変量時系列データを用いた予測モデルを作る時、未来の一時点での目的の値を予測するために、入力として一定の時間幅で切り取ったデータを用いることが多くあります。とくに、ある多変量時系列データから一変数の時系列データを予測するモデルの学習、予測を行う場合、元の多変量時系列データから、各時刻において切り出したデータを予め作成しておく必要がある場合があります。
⇧ 用語が統一されていないのだけど、仮に「スライド窓」として、「時系列データ」のデータ分析では、「スライド窓」が使われることが多いらしい。
とりあえず、海外の情報だと、
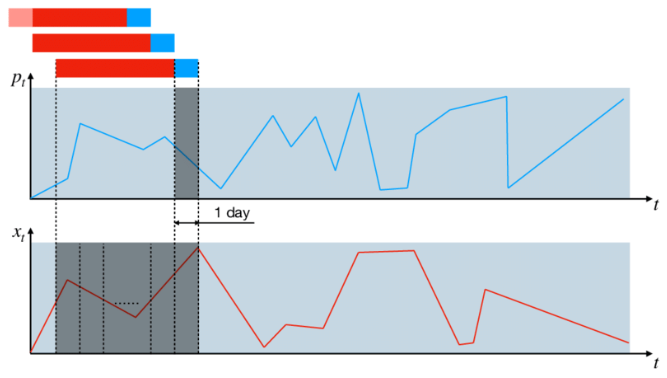
Figure 1: Sliding window technique for cutting the initial time series into fixed-length samples used afterward to trainand test machine learning algorithms. Each data sample consists of the time interval (red color) based on which thevalue of the bottom-hole pressure is predicted for the next day (blue color). The light red color is used for the timeintervals lying outside the original production period. The upper graph shows an example of the downhole pressurebehavior, while the lower one shows one of the time-dependent governing parameters, e.g., oil flow rate.

Fig. 2. The sliding window based time series analysis.
⇧「sliding windows」って用語が浸透している感じなんですかね?
「スライド窓」の粒度が分からんのだけど、
ここでは、多変量時系列データ dfX (nrow列 ncol行)から、各行においてサイズ M の窓でデータを切り出します。ここでは例として M = 60 ステップ(60秒) とします。
1回切り出したデータは M x ncolの行列となる。これを全ステップ繰り返すと nrow - M 枚の行列が得られ、これらを重ねると、 (nrow-M) x M x ncol の3次元配列が得られます。(図1)
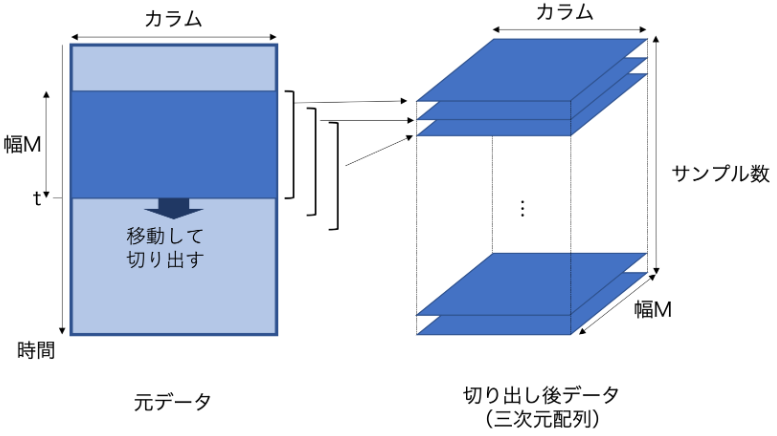
⇧ データの行数を「スライド窓」の大きさでブロックにしていく感じになるっぽいですな。トイレットペーパーを一定の間隔で切っていくようなものかね。
ライブラリ「scikit-learn」を導入して「異常検知」を試してみる
全くもって、理解できていませんが、参考サイト様を参考に試してみますか。
「sickit-learn」を利用するには、

⇧ 上記のライブラリが必要らしい。
一応、

⇧ 上記に記載あるように、「sicikit-learn」の導入方法としては、3通りの方法があるらしいですが、一番初めの「install the latest official release」で導入しておけば良さそう。
自分は、
⇧ 以前に構築していた環境を利用していこうと思います。
一般的には、
⇧ 上記サイト様にありますように、
- 「Webアプリケーション」用のプロジェクト
- 「機械学習」用のプロジェクト
とで、プロジェクトを分けた方が良いようですが、そもそも、「機械学習」用のプロジェクト構成とか分からんので、プロジェクトを分けずにいきます。
まずは、Python仮想環境にログインします。
現状、pipでインストール済のライブラリを確認してみる。
pip list --format columns
⇧「scikit-learn」はインストールされていないので、インストールしてみます。
pip install -U scikit-learn
⇧ インストールできたようです。
念のため確認。
⇧ インストールできてそうです。
で、
Scikit-learn plotting capabilities (i.e., functions starting with plot_ and classes ending with Display) require Matplotlib. The examples require Matplotlib and some examples require scikit-image, pandas, or seaborn. The minimum version of scikit-learn dependencies are listed below along with its purpose.
⇧ とありますように、「Matplotlib」や「pandas」などは別途、インストールが必要らしい、うむ、分かり辛い。
ちなみに、

⇧ 上記サイト様によりますと、「-U」はアップグレードオプションらしい。
「-U」を付けておけば、最新のバージョンでライブラリがインストールされるってことなんですかね?
とりあえず、参考サイト様の「異常検知」のサンプルの実装では、「Matplotlib」や「pandas」が必要なので、pip installしていきますか。
pip install -U pandas matplotlib
⇧ インストールできたっぽい。
念のため確認。
⇧ インストールできていることを確認。
とりあえず、必要なライブラリのインストールが完了できたので、実装の方に進みますか。
今回は、機械学習モデルの「学習データ」を「CSVファイル」ではなく、PostgreSQLに保存されてるレコードから取得したいので、
⇧ データ取得部分は、上記サイト様を参考にしていきます。
PostgreSQLのデータ取得対象のテーブルは、以下。
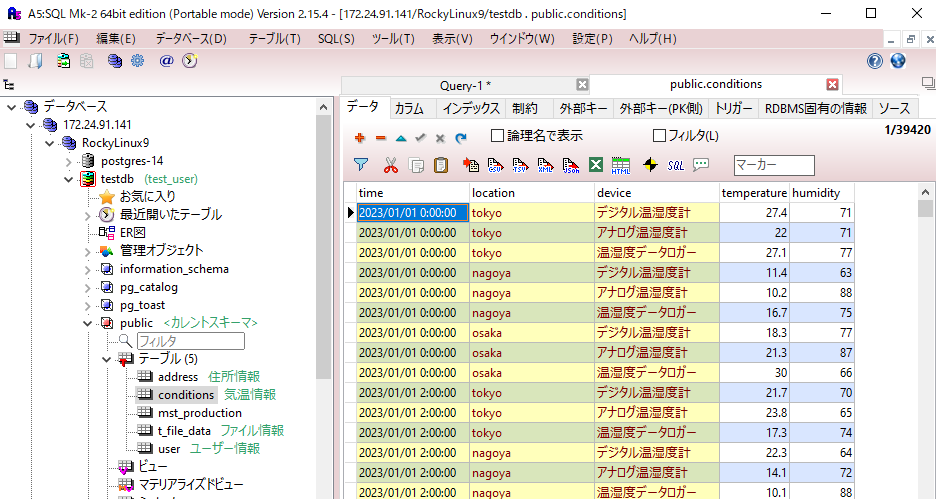
⇧ 4、5列目を取得する感じで。
PostgreSQLは、「WSL 2(Windows Subsystem for Linux 2)」にインストールしているRocky Linux上にインストールしている感じなので、起動しておく。
で、Pythonで「異常検知」の実装を試してみました。
■C:\Users\Toshinobu\Desktop\soft_work\python_work\fastapi\app\src\main\py\machine_learning\anomaly_detection\anomaly_detection_scikit-learn.py
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.dates import MonthLocator, DateFormatter
from sklearn.neighbors import NearestNeighbors
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import asyncio
import sys
from sqlalchemy import func, select, create_engine
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
import math
# from app.src.main.py.machine_learning.anomaly_detection.sliding_windows import (
# time_window_transform,
# )
def main():
# Windows環境でのイベントループポリシーの設定
if sys.platform == "win32":
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
# PostgreSQLのデータベース接続情報
CONNECTION_DB_URL = (
"postgresql+psycopg://test_user:password@172.24.91.141:5432/testdb"
)
engine = create_engine(CONNECTION_DB_URL, echo=True)
async_session = sessionmaker(engine, expire_on_commit=False, class_=AsyncSession)
# データベースからの読み込み
sql_query = """
SELECT
DATE_TRUNC('month', time) AS month,
device,
AVG(temperature) AS avg_temperature,
AVG(humidity) AS avg_humidity
FROM
conditions
GROUP BY
month, device
ORDER BY
month;
"""
df_sql = pd.read_sql_query(sql=sql_query, con=engine)
# 日本の2023年の月ごとの平均気温と湿度のデータ
japan_2023_data = {
"month": pd.date_range(start="2023-01-01", end="2023-12-01", freq="MS"),
"avg_temperature": [
5.2,
6.1,
9.8,
14.3,
18.9,
22.5,
26.4,
27.8,
23.9,
18.1,
12.3,
7.1,
],
"avg_humidity": [60, 62, 65, 68, 70, 75, 78, 80, 77, 72, 68, 64],
}
japan_2023_df = pd.DataFrame(japan_2023_data)
# グラフの設定
fig, axs = plt.subplots(1, 2, figsize=(18, 8))
# 日本の2023年のデータをプロット
axs[0].plot(
japan_2023_df["month"],
japan_2023_df["avg_temperature"],
label="Japan 2023 - Temperature",
color="black",
linestyle="--",
)
axs[1].plot(
japan_2023_df["month"],
japan_2023_df["avg_humidity"],
label="Japan 2023 - Humidity",
color="black",
linestyle="--",
)
# デバイスごとのデータをプロット
devices = df_sql["device"].unique()
colors = ["blue", "green", "orange"]
japan_2023_months = japan_2023_df["month"].dt.strftime("%Y-%m")
for i, device in enumerate(devices):
device_data = df_sql[df_sql["device"] == device]
# 温度のグラフ
axs[0].plot(
device_data["month"],
device_data["avg_temperature"],
label=f"{device} - Temperature",
color=colors[i],
)
# 異常値の塗りつぶし
for j, row in device_data.iterrows():
row_month = pd.to_datetime(row["month"]).strftime("%Y-%m")
month_index = japan_2023_df[japan_2023_months == row_month].index
if not month_index.empty:
if (
abs(
row["avg_temperature"]
- japan_2023_df.loc[month_index[0], "avg_temperature"]
)
> 3.0
):
axs[0].fill_between(
[row["month"] - pd.DateOffset(months=1), row["month"]],
row["avg_temperature"],
japan_2023_df.loc[month_index[0], "avg_temperature"],
color="pink",
alpha=0.3,
)
# 湿度のグラフ
axs[1].plot(
device_data["month"],
device_data["avg_humidity"],
label=f"{device} - Humidity",
color=colors[i],
)
# 異常値の塗りつぶし
for j, row in device_data.iterrows():
row_month = pd.to_datetime(row["month"]).strftime("%Y-%m")
month_index = japan_2023_df[japan_2023_months == row_month].index
if not month_index.empty:
if (
abs(
row["avg_humidity"]
- japan_2023_df.loc[month_index[0], "avg_humidity"]
)
> 3.0
):
axs[1].fill_between(
[row["month"] - pd.DateOffset(months=1), row["month"]],
row["avg_humidity"],
japan_2023_df.loc[month_index[0], "avg_humidity"],
color="pink",
alpha=0.3,
)
# 凡例の追加
axs[0].legend()
axs[1].legend()
# x軸のフォーマットを調整
for ax in axs:
ax.xaxis.set_major_locator(MonthLocator())
ax.xaxis.set_major_formatter(DateFormatter("%Y-%m"))
for label in ax.get_xticklabels():
label.set_rotation(45)
# 日本語フォントの設定
plt.rcParams["font.sans-serif"] = ["MS Gothic"] # Windowsの場合
plt.rcParams["axes.unicode_minus"] = False
plt.tight_layout()
plt.show()
# plt.savefig(
# "C:/Users/Toshinobu/Desktop/soft_work/python_work/fastapi/app/src/main/py/machine_learning/anomaly_detection/sample1.png"
# )
# スライド窓を使用してデータをまとめる関数
def create_sliding_windows(df, window_size, step_size):
windows = []
for start in range(0, len(df) - window_size + 1, step_size):
end = start + window_size
window = df.iloc[start:end]
windows.append(window)
return windows
if __name__ == "__main__":
main()
⇧ 保存。実行。
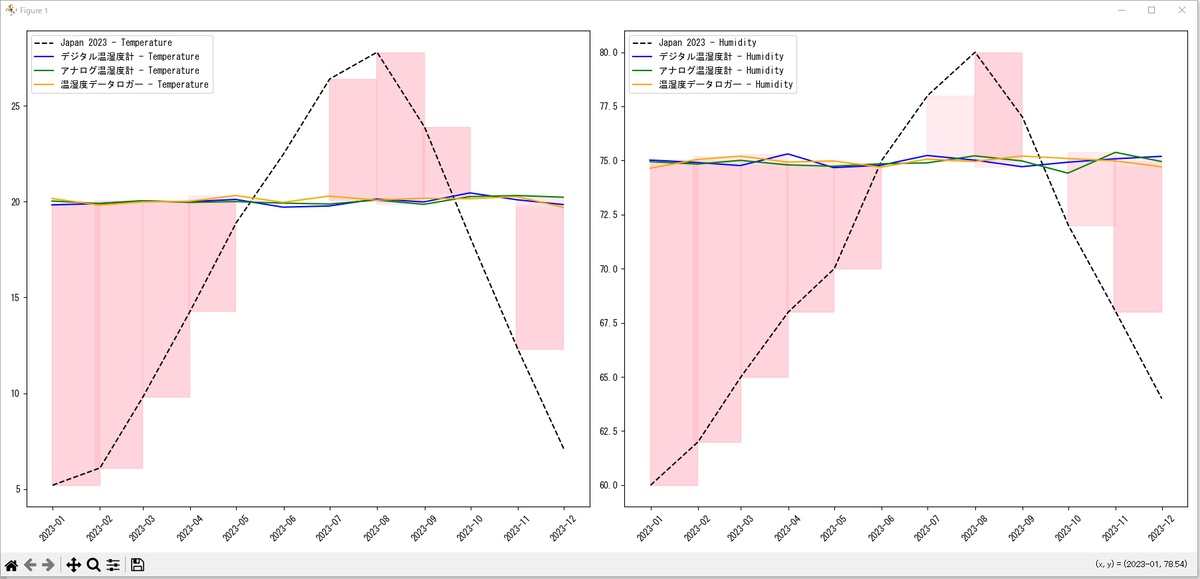
⇧ 何か、上手くいかない...
そもそも「スライド窓」が利用できておらんし...
う~む、ネットの情報を継ぎ接ぎした感じなので、正解が分からんのよな...正解じゃないということは何となく分かるんだが...
何某かの技術書を確認しないと駄目そうかね...
徒労感が半端ない...
毎度モヤモヤ感が半端ない…
今回はこのへんで。