
⇧ 何と言うか、
⇧「元号」はこの先も無くなりそうに無いと思うんで、
- 西暦
- 元号
を併記すれば良いんじゃないのかね。
Webシステムとかなら、サーバーサイド側でデータベースから情報を取得するような処理が入ると思うから、デジタル庁とかがデータベースで「西暦」と「元号」のマッピングデータを管理してくようにしてもらえれば、一度そこから情報を引っ張って来るだけにして、ソフトウェア側での面倒くさい変換処理とか無くせば良いと思うし。
更新バッチみたいなの用意しておいて、「元号」が変わったら、周知されると思うから、更新バッチを実施するような運用にしておけば良いと思うし。
紙媒体の申請書類とかは、上手い対策が思いつかんけど、Webシステムのようなものなら、「西暦」を入力したら「元号」は自動的に入力される仕組みとかにすれば良いと思うし、まぁ、そもそも、ユーザーの入力に頼らなくてもシステムの運用側でだけ必要な情報である可能性もあるので、何とも言えん...
ただ、単に表示される項目であるなら、「西暦」と「元号」を併記してくれた方が、「元号」の存在するシステム系で生活している我々にとっては、「日本人」「外国人」の区別に関係なく良い気はするんですけどね。
兎に角、一部のシステムでは使わないみたいなのは、後々、システム間の連携などで面倒くさいことになりかねないし、余計に混乱するので止めてもらって、統一しては欲しいですかね。
AWKとは?
Wikipediaさんによると、
AWK (awk /ɔːk/) is a domain-specific language designed for text processing and typically used as a data extraction and reporting tool. Like sed and grep, it is a filter, and is a standard feature of most Unix-like operating systems.
The AWK language is a data-driven scripting language consisting of a set of actions to be taken against streams of textual data – either run directly on files or used as part of a pipeline – for purposes of extracting or transforming text, such as producing formatted reports. The language extensively uses the string datatype, associative arrays (that is, arrays indexed by key strings), and regular expressions. While AWK has a limited intended application domain and was especially designed to support one-liner programs, the language is Turing-complete, and even the early Bell Labs users of AWK often wrote well-structured large AWK programs.
AWK was created at Bell Labs in the 1970s, and its name is derived from the surnames of its authors: Alfred Aho, Peter Weinberger, and Brian Kernighan. The acronym is pronounced the same as the name of the bird species auk, which is illustrated on the cover of The AWK Programming Language. When written in all lowercase letters, as awk, it refers to the Unix or Plan 9 program that runs scripts written in the AWK programming language.
⇧ ということらしい。
ドキュメントによると、
SYNOPSIS
awk [-F sepstring] [-v assignment]... program [argument...]
awk [-F sepstring] -f progfile [-f progfile]... [-v assignment]...
[argument...]
https://pubs.opengroup.org/onlinepubs/9699919799/utilities/awk.html
⇧ 2つの基本的な実行の仕方が用意されていて、
の2パターンになるってことかと。
awk [-F sepstring] [-v assignment]... program [argument...]
【2】.awkファイルを用意して、.awkファイルとしてawkのプログラム実行
awk [-F sepstring] -f progfile [-f progfile]... [-v assignment]...
[argument...]
⇧ という感じになると思うのだけど、ほぼほぼ「.sh」ファイルの中で直にawkのプログラムがコーディングされてるケースがほとんどのような気がする、つまり、「【1】.awkファイルは用意せず、awkプログラムを実行」の方。
『... program』の部分が、awkのプログラムの部分、つまりawkでの実際の処理をコーディングしていく部分になると思うのだけど、
⇧ の例にあるように、基本的には、
- BEGIN patterns(BEGIN block)
- missing pattern
- END patterns(END block)
の3つの構成に分ける感じになるようなのだけど、「2.missing pattern」以外の部分は無くても動くらしい。
で、
⇧ 上記サイト様にあるように、「ワンライナー(one-liner)」で記述する文化が基本なのかが分からんのだけど、if文などが多いケースにおいて、可読性が最悪であると、というかソースコードの解読が無茶苦茶し辛い...
ちなみに、公式の情報ではないですが、
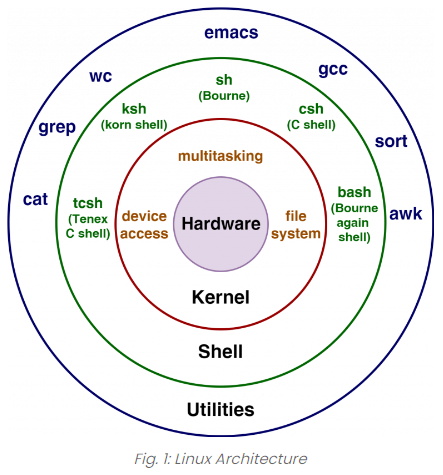
Figure 2. Simple architecture of a hypothetical shell

⇧「Shell」と「AWK」の関係は、上図のような感じになるっぽい。
awkコマンドは、catコマンドやwcコマンドなどと同じ枠組みに属するってことみたいですね。
ShellScriptでawkのワンライナー(one-liner)の部分のコードの自動整形とかしたいんだが
で、ようやっと、本題である表題の件になると。
awkのプログラム部分で、if文とかが複数出てくるケースで「ワンライナー(one-liner)」とかになっていると、ソースコードの読解が辛いですと。
例えば、
#!/bin/bash
# ワンライナーにしたいawkのプログラムをシェルスクリプトの変数に格納
AWK_SCRIPT=$(cat << 'EOS'
awk </home/ts0818/work/test_validate/data/file/csv/13.csv -F,
'BEGIN {
printf "【start】CSVファイルのバリデーションを開始します。\n";
correct_header_01= "ID,都道府県市区町村コード,市区町村名,基準メッシュ・コード";
correct_col_num = split(correct_header_01, correct_header_01_arr, /[,]/);
row_number_processed = 1;
}
{
# 【処理】ヘッダーのバリデーション
# 1行目、且つ、1ファイル目
if (NR == 1) {
# 末尾の改行を削除
sub(/\r?$/, "")
# 1行目の内容を配列に格納
split($0, first_row_arr, ",")
error_count = 0;
# ヘッダーの有無のチェック
for (i = 1; i <= correct_col_num; i++) {
if (first_row_arr[i] != correct_header_01_arr[i]) {
printf("ヘッダーが不正です。\n");
printf("[入力のヘッダー項目]%s\n[正しいヘッダー項目]%s\n", first_row_arr[i], correct_header_01_arr[i]);
error_count++;
}
}
if (error_count == 0) {
printf("[SUCCESS][CSV Validation][%d行目]%s\n", row_number_processed, "異常なし。");
printf("[入力のヘッダー]%s\n", $0);
printf("[正しいヘッダー]%s\n", correct_header_01);
}
# 行数をインクリメント
row_number_processed++;
next;
}
if (NR != 1) {
# 【処理】ヘッダー行以外のバリデーション
for (i = 1; i <= NF; i++) {
# 1カラム(列)目のバリデーション
if (i == 1) {
printf("【%d】行目のバリデーション開始。\n", row_number_processed);
# 必須チェック
if ($1 == "") {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。");
printf("[カラム][%s]%s\n", first_row_arr[i], $1);
# IDのフォーマットチェック
} else if ($1 !~/[A-Z]{1}[0-9]{5}/) {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "フォーマットが不正です。");
printf("[カラム][%s]%s\n", first_row_arr[i], $1);
} else {
printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。");
printf("[カラム][%s]%s\n", first_row_arr[i], $1);
}
}
# 2カラム(列)目のバリデーション
if (i == 2) {
# 必須チェック
if ($2 == "") {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。");
printf("[カラム][%s]%s\n", first_row_arr[i], $2);
# 半角数字5桁かどうかチェック
} else if ($2 !~/[0-9]{5}/) {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "半角数字5桁である必要があります。");
printf("[カラム][%s]%s\n", first_row_arr[i], $2);
} else {
printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。");
printf("[カラム][%s]%s\n", first_row_arr[i], $2);
}
}
# 3カラム(列)目のバリデーション
if (i == 3) {
# 必須チェック
if ($3 == "") {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。");
printf("[カラム][%s]%s\n", first_row_arr[i], $3);
# 全角かどうかチェック
} else if ($3 !~ /^[[:cntrl:][:print:]]*$/){
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "全て全角文字である必要があります。");
printf("[カラム][%s]%s\n", first_row_arr[i], $3);
} else {
printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。");
printf("[カラム][%s]%s\n", first_row_arr[i], $3);
}
}
# 4カラム(列)目のバリデーション
if (i == 4) {
# 必須チェック
if ($4 == "") {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。");
printf("[カラム][%s]%s\n", first_row_arr[i], $4);
# 半角数字5桁かどうかチェック
} else if ($4 !~/[0-9]{8}/) {
printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "半角数字8桁である必要があります。");
printf("[カラム][%s]%s\n", first_row_arr[i], $4);
} else {
printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。");
printf("[カラム][%s]%s\n", first_row_arr[i], $4);
}
}
if (i == NF) {
printf("【%d】行目のバリデーション終了。\n", row_number_processed);
# 行数をインクリメント
row_number_processed++;
}
}
}
}
END {
printf "【finish】CSVファイルのバリデーションを終了します。\n"
printf("%d行%s\n", row_number_processed, "が処理されました。(ヘッダー行1行を含む)")
}
' > result.log
EOS
)
# 改行を取り除いたものを出力
echo ${AWK_SCRIPT} | sed -e "s/[\r\n]\+//g" > convert_to_one_liner.sh
⇧ 上記のような処理があった場合に、最終的に「ワンライナー(one-liner)」にするとしても、処理を追うとなった場合に、「ワンライナー(one-liner)」のままだと人間の目では困難ではないかと。
試しに、改行コードを除いて、「ワンライナー(one-liner)」にしてみたのが以下。
awk </home/ts0818/work/test_validate/data/file/csv -F, 'BEGIN { printf "【start】CSVファイルのバリデーションを開始します。\n"; correct_header_01= "ID,都道府県市区町村コード,市区町村名,基準メッシュ・コード"; correct_col_num = split(correct_header_01, correct_header_01_arr, /[,]/); row_number_processed = 1; } { # 【処理】ヘッダーのバリデーション # 1行目、且つ、1ファイル目 if (NR == 1) { # 末尾の改行を削除 sub(/\r?$/, "") # 1行目の内容を配列に格納 split($0, first_row_arr, ",") error_count = 0; # ヘッダーの有無のチェック for (i = 1; i <= correct_col_num; i++) { if (first_row_arr[i] != correct_header_01_arr[i]) { printf("ヘッダーが不正です。\n"); printf("[入力のヘッダー項目]%s\n[正しいヘッダー項目]%s\n", first_row_arr[i], correct_header_01_arr[i]); error_count++; } } if (error_count == 0) { printf("[SUCCESS][CSV Validation][%d行目]%s\n", row_number_processed, "異常なし。"); printf("[入力のヘッダー]%s\n", $0); printf("[正しいヘッダー]%s\n", correct_header_01); } # 行数をインクリメント row_number_processed++; next; } if (NR != 1) { # 【処理】ヘッダー行以外のバリデーション for (i = 1; i <= NF; i++) { # 1カラム(列)目のバリデーション if (i == 1) { printf("【%d】行目のバリデーション開始。\n", row_number_processed); # 必須チェック if ($1 == "") { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。"); printf("[カラム][%s]%s\n", first_row_arr[i], $1); # IDのフォーマットチェック } else if ($1 !~/[A-Z]{1}[0-9]{5}/) { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "フォーマットが不正です。"); printf("[カラム][%s]%s\n", first_row_arr[i], $1); } else { printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。"); printf("[カラム][%s]%s\n", first_row_arr[i], $1); } } # 2カラム(列)目のバリデーション if (i == 2) { # 必須チェック if ($2 == "") { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。"); printf("[カラム][%s]%s\n", first_row_arr[i], $2); # 半角数字5桁かどうかチェック } else if ($2 !~/[0-9]{5}/) { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "半角数字5桁である必要があります。"); printf("[カラム][%s]%s\n", first_row_arr[i], $2); } else { printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。"); printf("[カラム][%s]%s\n", first_row_arr[i], $2); } } # 3カラム(列)目のバリデーション if (i == 3) { # 必須チェック if ($3 == "") { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。"); printf("[カラム][%s]%s\n", first_row_arr[i], $3); # 全角かどうかチェック } else if ($3 !~ /^[[:cntrl:][:print:]]*$/){ printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "全て全角文字である必要があります。"); printf("[カラム][%s]%s\n", first_row_arr[i], $3); } else { printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。"); printf("[カラム][%s]%s\n", first_row_arr[i], $3); } } # 4カラム(列)目のバリデーション if (i == 4) { # 必須チェック if ($4 == "") { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "必須項目です。"); printf("[カラム][%s]%s\n", first_row_arr[i], $4); # 半角数字5桁かどうかチェック } else if ($4 !~/[0-9]{8}/) { printf("[ERROR][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "半角数字8桁である必要があります。"); printf("[カラム][%s]%s\n", first_row_arr[i], $4); } else { printf("[SUCCESS][CSV Validation][%d行目%d列]%s\n", row_number_processed, i, "異常なし。"); printf("[カラム][%s]%s\n", first_row_arr[i], $4); } } if (i == NF) { printf("【%d】行目のバリデーション終了。\n", row_number_processed); # 行数をインクリメント row_number_processed++; } } } } END { printf "【finish】CSVファイルのバリデーションを終了します。\n" printf("%d行%s\n", row_number_processed, "が処理されました。(ヘッダー行1行を含む)") } ' > result.log
⇧ どうだろうか?
これを、「ワンライナー(one-liner)」の形の状態のままでも可読性ある、と認識している人間がいるとしたら、ちょっと「サヴァン症候群」的な能力を持っている天才としか思えないのだが、一般的な凡庸な民である我々のような人類にとって、上記のような「ワンライナー(one-liner)」のままでプログラミング処理を読解するのは難しいと言えるのでは無いか?
しかもである。
⇧ 何と、「ワンライナー(one-liner)」の形にするには、実際に動いていたコードに手を加える必要があるらしい...
awk、カオス過ぎる...
gawkのオプションでワンライナー(one-liner)からの自動整形が可能らしいのだが...
ネットの情報によると、
⇧ とあり、gawkの「--pertty-print」っていうオプションを使えば、「ワンライナー(one-liner)」の形のawkのソースコードを整形してくれるらしい。
If you are like many computer users, you would frequently like to make changes in various text files wherever certain patterns appear, or extract data from parts of certain lines while discarding the rest. To write a program to do this in a language such as C or Pascal is a time-consuming inconvenience that may take many lines of code. The job is easy with awk, especially the GNU implementation: gawk.
This software is part of the GNU Project.
⇧ GNUプロジェクトのawkということで「gawk」らしい。
「GNU」はと言うと、
GNU(グヌー、[ɡnuː](Section: The name "GNU"))とはオペレーティングシステムであり、かつコンピュータソフトウェアの広範囲に渡るコレクションである。GNUは完全にフリーソフトウェアから構成されている。
GNUは"GNU's Not Unix!"(「GNUはUNIXではない」)の再帰的頭字語である。この名称が選ばれたのは、GNUはUnix系の設計ではあるがUNIXとは違いフリーソフトウェアでありUNIXに由来するソースコードを全く使っていないことを示すためである。
⇧ とのこと。
gawkの「--pertty-print」っていうオプションはと言うと、
-o[file]
--pretty-print[=file]
Enable pretty-printing of awk programs. Implies --no-optimize. By default, the output program is created in a file named awkprof.out (see Profiling Your awk Programs). The optional file argument allows you to specify a different file name for the output. No space is allowed between the -o and file, if file is supplied.
NOTE: In the past, this option would also execute your program. This is no longer the case.
⇧ とあり、『Enable pretty-printing of awk programs.』とあるので、ソースコードを整形してくれるってことなんだと思う、多分。
で、Windows特有の問題らしいのですが、
⇧ まさかの「シングルクォーテーション」だと機能しないという...
致し方無いので、Windows環境では「ダブルクォーテーション」にしてあげる必要があるみたい。
「WSL 2(Windows Subsystem for Linux 2)」だと問題なさそう。
あと、衝撃なのが、awkだと「index」が予約語とか何のか知らんけど、for文で使ったら、エラーになるというね...
その他にも、いろいろ、エラーが出てしまうので、整形の対象のawkのコードが少なくなったけど、以下を実行。
gawk -o- 'BEGIN { printf "【start】CSVファイルのバリデーションを開始します。\n"; correct_header_01= "ID,都道府県市区町村コード,市区町村名,基準メッシュ・コード"; correct_col_num = split(correct_header_01, correct_header_01_arr, /[,]/); row_number_processed = 1;};{ printf("done") }'
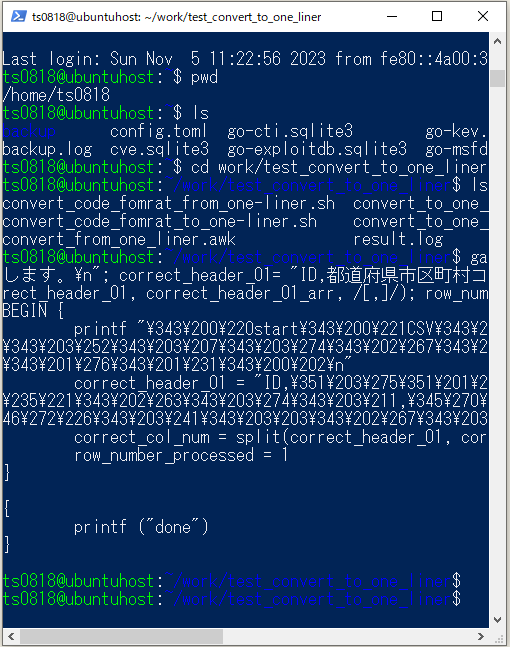
結果。
BEGIN {
printf "\343\200\220start\343\200\221CSV\343\203\225\343\202\241\343\202\244\343\203\253\343\201\256\343\203\220 \343\203\252\343\203\207\343\203\274\343\202\267\343\203\247\343\203\263\343\202\222\351\226\213\345\247\213\343\201\227 \343\201\276\343\201\231\343\200\202\n"
correct_header_01 = "ID,\351\203\275\351\201\223\345\272\234\347\234\214\345\270\202\345\214\272\347\224\272\346 \235\221\343\202\263\343\203\274\343\203\211,\345\270\202\345\214\272\347\224\272\346\235\221\345\220\215,\345\237\272\3 46\272\226\343\203\241\343\203\203\343\202\267\343\203\245\343\203\273\343\202\263\343\203\274\343\203\211"
correct_col_num = split(correct_header_01, correct_header_01_arr, /[,]/)
row_number_processed = 1
}
{
printf ("done")
}
⇧ う~む、日本語の部分は解釈できないのか、酷いことになっているし、実用するにはかなり厳しいんだけど...
でも、「ワンライナー(one-liner)」の形のコードを手動で整形とかしたくないんだが...
保守・運用の観点で言うなら、「ワンライナー(one-liner)」の形にするのは止めて「.awk」ファイルに処理を分けておくのが良さそうですかね...
勿論、短い処理とかなら「ワンライナー(one-liner)」の形にしてしまうのもありだと思うけど、複数の条件分岐とか存在するようなコードで「ワンライナー(one-liner)」の形にするのは宜しくない気がする...
毎度モヤモヤ感が半端ない...
今回はこのへんで。