
TOP500は、米コロラド州デンバーで開催しているHPCの国際会議「SC23」で14日(現地時間)に公表された。米国の新型スパコン「Frontier」などが1位から3位までを占め、富岳は4位だった。AIの深層学習などに用いる単精度や半精度演算処理に関する性能ベンチマーク「HPL-MxP」(旧HPL-AI)でもFrontierが1位で、富岳は3位だった。
スパコン世界ランキングで「富岳」は4位に 「HPCG」は1位継続、「引き続き世界最高水準」と富士通 - ITmedia NEWS
一方、富岳が1位をとったHPCGは、産業利用などの実際のアプリケーションでよく用いられる共役勾配法の処理速度ランキング。富岳は432筐体(15万8976ノード)を用い、16.00PFLOPS(ペタフロップス)という高いスコアを記録した。「引き続き富岳の世界最高水準の総合的な性能を示すもの」(富士通)。
スパコン世界ランキングで「富岳」は4位に 「HPCG」は1位継続、「引き続き世界最高水準」と富士通 - ITmedia NEWS
⇧ アメリカが強いですな、とは言え、日本も頑張っていますな。
シェルスクリプトとawkのコーディング練習として、CSVファイルの加工をする
シェルスクリプトとawkの癖が強いので、動作確認の意味も込めて、CSVファイルの加工を練習してみました。
利用しているCSVファイルは、
⇧ 上記の記事の時のものになります。
awkについては、みんな大好き、ワンライナーで頑張ってみました。
「WSL 2(Windows Subsystem for Linux 2)」の「Ubuntu 22.04.2 LTS (GNU/Linux 5.15.90.1-microsoft-standard-WSL2 x86_64)」で動作確認しています。
シェルスクリプトを配置します。

■/home/ts0818/work/test_shell_syntax/test_lesson_shell.sh
#!/bin/bash
# このシェルスクリプトが配置されているディレクトリまでの絶対パス
SCRIPT_DIR=$(cd $(dirname $0); pwd);
# インプットの配置先ディレクトリ
test_input_dir=/home/ts0818/work/test_validate/data/file/csv
# インプットのCSVファイル
test_data_file=13.csv
# ベースとなるディレクトリ
test_base_dir=test_case;
# 各テスト用のディレクトリ
test_case_01=${test_base_dir}/test_01;
test_case_02=${test_base_dir}/test_02;
test_case_03=${test_base_dir}/test_03;
test_case_04=${test_base_dir}/test_04;
test_case_05=${test_base_dir}/test_05;
test_case_06=${test_base_dir}/test_06;
test_case_07=${test_base_dir}/test_07;
test_case_08=${test_base_dir}/test_08;
test_case_09=${test_base_dir}/test_09;
test_case_10=${test_base_dir}/test_10;
# 配列の初期化
test_case_arr=(\
${test_case_01} \
${test_case_02} \
${test_case_03} \
${test_case_04} \
${test_case_05} \
${test_case_06} \
${test_case_07} \
${test_case_08} \
${test_case_09} \
${test_case_10} \
);
# インデックス付きfor文
for ((idx = 0; idx < ${#test_case_arr[@]}; idx++))
do
# ディレクトリが存在しなければ作成
mkdir -p "${test_case_arr[${idx}]}";
done;
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 関数定義
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース1)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目に"0"を1文字追加
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function test_01() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {$1="0" $1; print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース2)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目の先頭から1文字削除
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function test_02() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {$1=substr($1, 2); print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース3)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目を空にする
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function test_03() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {gsub(/.*/, "", $1); print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ テストデータ作成
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
number_of_test_case=0;
echo -e "Number of test cases:"'\t'"${#test_case_arr[@]}\n";
for ((idx = 0; idx < ${#test_case_arr[@]}; idx++))
do
number_of_test_case=$((1+${idx}));
case "${number_of_test_case}" in
1)
test_01 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
2)
test_02 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
3)
test_03 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
4)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
5)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
6)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
7)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
8)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
9)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
10)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
*)
echo "The test_${number_of_test_case} case is Not in the plan."
;;
esac
done;
⇧ で、実行すると。
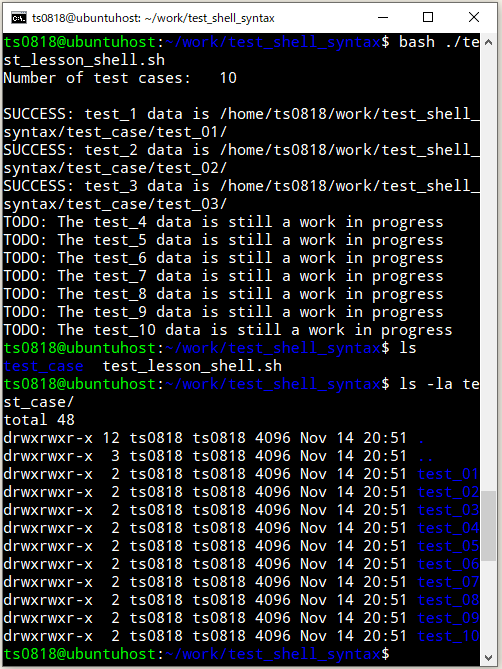

⇧ 意図した動きになっているようです。
2023年11月15日(水):↓ ここから
2列(カラム)目以降の列(カラム)を全て空にするというパターンも試してみました。
#!/bin/bash
# このシェルスクリプトが配置されているディレクトリまでの絶対パス
SCRIPT_DIR=$(cd $(dirname $0); pwd);
# インプットの配置先ディレクトリ
test_input_dir=/home/ts0818/work/test_validate/data/file/csv
# インプットのCSVファイル
test_data_file=13.csv
# ベースとなるディレクトリ
test_base_dir=test_case;
# 各テスト用のディレクトリ
test_case_01=${test_base_dir}/test_01;
test_case_02=${test_base_dir}/test_02;
test_case_03=${test_base_dir}/test_03;
test_case_04=${test_base_dir}/test_04;
test_case_05=${test_base_dir}/test_05;
test_case_06=${test_base_dir}/test_06;
test_case_07=${test_base_dir}/test_07;
test_case_08=${test_base_dir}/test_08;
test_case_09=${test_base_dir}/test_09;
test_case_10=${test_base_dir}/test_10;
# 配列の初期化
test_case_arr=(\
${test_case_01} \
${test_case_02} \
${test_case_03} \
${test_case_04} \
${test_case_05} \
${test_case_06} \
${test_case_07} \
${test_case_08} \
${test_case_09} \
${test_case_10} \
);
# インデックス付きfor文
for ((idx = 0; idx < ${#test_case_arr[@]}; idx++))
do
# ディレクトリが存在しなければ作成
mkdir -p "${test_case_arr[${idx}]}";
done;
# ■■■■■■■■■■■■■■■■■■■
# ■ 関数定義
# ■■■■■■■■■■■■■■■■■■■
# ■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース1)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目に"0"を1文字追加
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■
function test_01() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {$1="0" $1; print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース2)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目の先頭から1文字削除
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■
function test_02() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {$1=substr($1, 2); print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース3)作成
# ■ 処理概要
# ■ CSVファイルの1列(カラム)目を空にする
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■
function test_03() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {gsub(/.*/, "", $1); print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■
# ■ テストデータ(ケース4)作成
# ■ 処理概要
# ■ CSVファイルの2列(カラム)目以降の列(カラム)を空にする
# ■ 引数
# ■ param $1 テストデータのファイル名
# ■ param $2 インプットの配置先ディレクトリ
# ■ param $3 アウトプットの配置先ディレクトリ
# ■
# ■■■■■■■■■■■■■■■■■■■
function test_04() {
local _data_file="$1"
local _input_dir="$2"
local _output_dir="$3"
awk -F"," 'BEGIN {FS=",";}; NR==1 {print $0;next;}; NR!=1 {for(i=1;i<=NF;i++){if(i>=2){gsub(/.*/, "", $i)}}; print $0;};' "${_input_dir}/${_data_file}" > "${_output_dir}/${_data_file}";
}
# ■■■■■■■■■■■■■■■■■■■
# ■ テストデータ作成
# ■■■■■■■■■■■■■■■■■■■
number_of_test_case=0;
echo -e "Number of test cases:"'\t'"${#test_case_arr[@]}\n";
for ((idx = 0; idx < ${#test_case_arr[@]}; idx++))
do
number_of_test_case=$((1+${idx}));
case "${number_of_test_case}" in
1)
test_01 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
2)
test_02 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
3)
test_03 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
4)
test_04 ${test_data_file} ${test_input_dir} ${test_case_arr[${idx}]};
echo "SUCCESS: test_${number_of_test_case} data is ${SCRIPT_DIR}/${test_case_arr[${idx}]}/";
;;
5)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
6)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
7)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
8)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
9)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
10)
echo "TODO: The test_${number_of_test_case} data is still a work in progress"
;;
*)
echo "The test_${number_of_test_case} case is Not in the plan."
;;
esac
done;
⇧ で、実行すると、
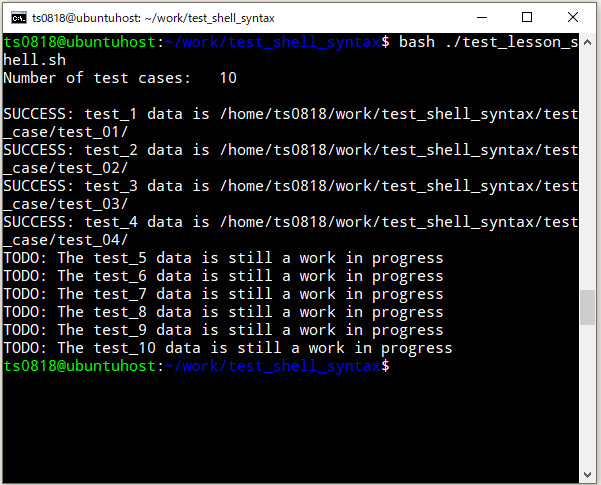
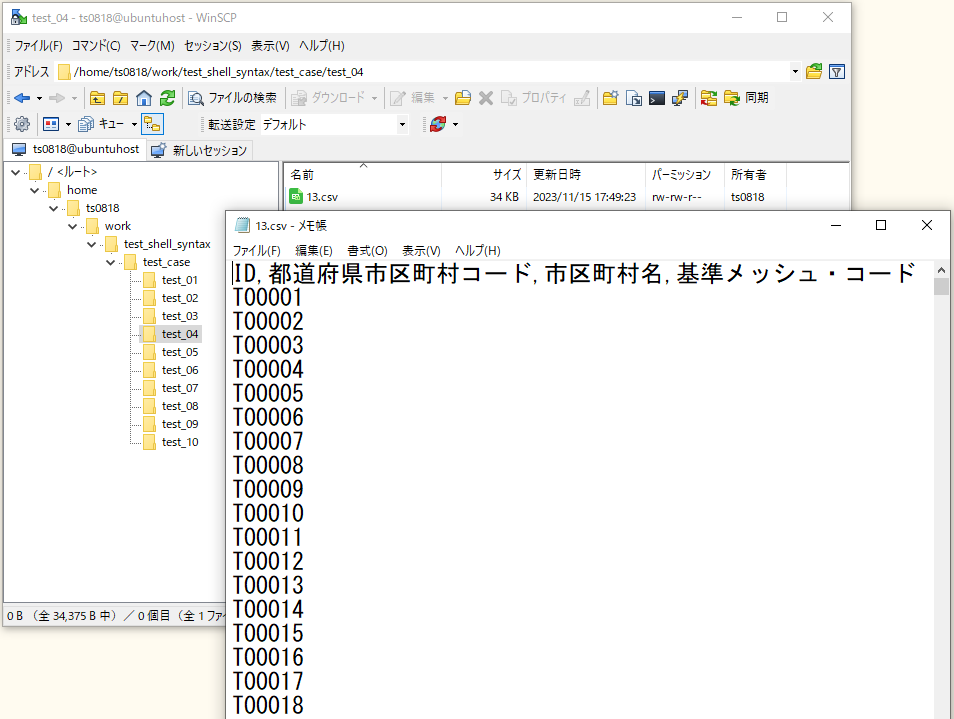
⇧ 1列(カラム)目以外の列(カラム)が全て空になっていることが確認できました。
ちなみに、Javaとかのsubstring()メソッドと違って、awkのsubstr()メソッドは、処理対象の文字が空であったとしてもエラーとか起きないみたい。
2023年11月15日(水):↑ ここまで
それにしても、シェルスクリプトもawkも公式のコーディング規約みたいなが無いのかしら...
ネットで情報を漁ってたら、
⇧ bashでのシェルスクリプトのコーディング規約についてまとめて下さっている方はおられました。
何と言うか、枯れた技術であるはずなのに、基本的なことについての情報が少ないのって何なんでしょうね...
それにしても、相変わらず、シェルスクリプトとawkが同じ$1、$2、$3、...とかって変数を使ってるの紛らわし過ぎるんよね...
毎度モヤモヤ感が半端ない...
今回はこのへんで。