
⇧ 大規模なシステムになるほど、要件や仕様が定義された経緯や背景が、ドキュメントや実装から読み取れない部分が多くなってくると思うので、引継ぎした担当者はシステムに対して理解が不十分な状態で新規機能の追加や改修することにならざるを得ないとなり、結果、不具合が埋め込まれやすくなるような流れになるという悪循環も起因してる気がするんですけどね。
曖昧で不明な点が多い仕様や要件に対して有効なテストを実施するのは難しい気がしますけどね。
とは言え、ビジネス側の言い分で多いのは、
『利益を出さなければならぬ、兎に角、運用・保守しやすいなんてことはどうでも良い、今は動けば良い』
って考えだから、技術者と考え方が平行線なんよね。
要件や仕様が意味不明な状況になった状態で、まともなリファクタリングしきれないと思うし、結局のところ、後進が負担の皺寄せを受ける形になると思うんよね。
そして、
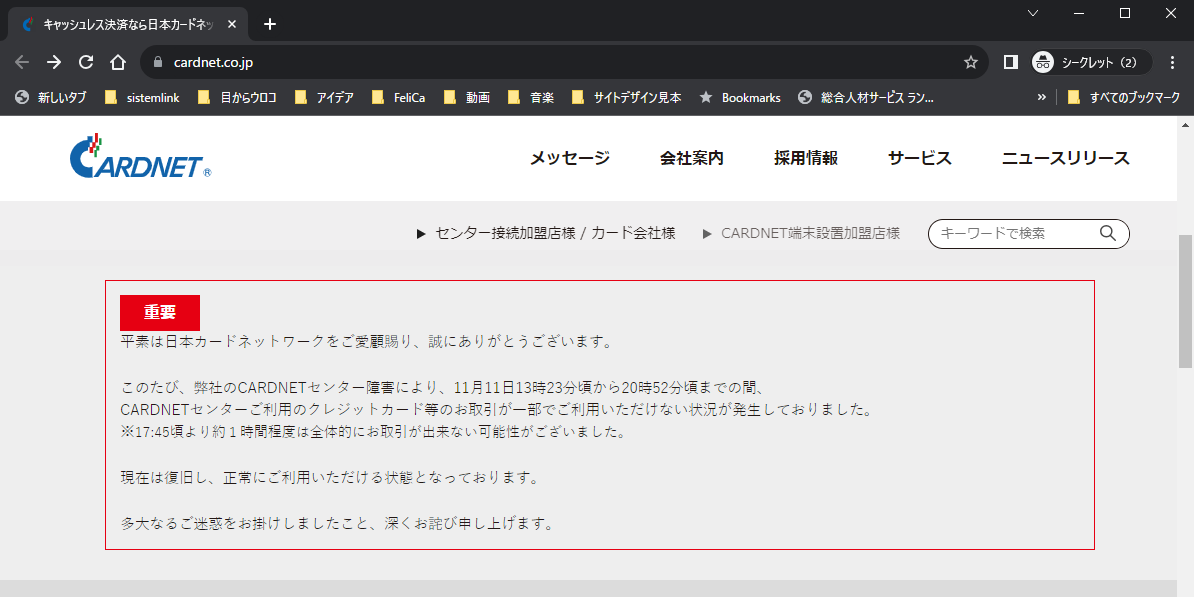
⇧ クレジット決済界隈でも障害があったみたいですね、原因は良く分からんですが。
まぁ、金融系のシステム開発には関わりたくないという思いが、より一層深まりしたかね。
awkでCSVファイルの内容を加工して新たなCSVファイルに出力してみる
テストのインプットでCSVファイルの加工が必要になることってあるあるだと思うんですよね。
列(カラム)に対しての加工のニーズが多いのではないかと。
例えば、正常に処理がなされるインプットとしてのCSVファイルを雛型として、不正な値を混ぜることで、バリデーションの機能を検証するためのインプットとなるCSVファイルを用意するなんてケースあると思います。
バリデーションの機能の要件にもよりますが、
- 必須チェック
→空の値を含める - 半角数字のみ許容
→半角数字以外の値を含める - 半角英字のみ許容
→半角英字以外の値を含める - 全角のみ許容
→全角以外の値を含める - 固定長
→許容されていない文字数の値を含める
⇧ のような感じで、列(カラム)毎に必要な値が変わってくるとは思いますが。
で、awkの使い方がよく分からず、無茶苦茶に泥沼にハマったんだが...
とりあえず、
⇧ この時と同じCSVファイルをインプットとして使っています。
awkとシェルスクリプトのコーディング内容は以下になりました。
■/home/ts0818/work/test_validate/tool/awk/make_test_data.awk
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 処理
# ■ インプットのCSVファイルの内容を加工して、
# ■ 新たな内容を出力する
# ■ 引数
# ■ param ARGV[0] awk ←awk側で勝手に設定されるっぽい
# ■ param ARGV[1] CSVファイル(インプット)
# ■ param ARGV[2] ログファイル
# ■ param ARGV[3] CSVファイル(インプット)の総行数
# ■ param ARGV[4] 乱数生成用のseed
# ■ 戻り値
# ■ return CSVファイルの内容を加工したもの
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# 初回の処理
BEGIN {
input_csv_file=ARGV[1]
log_file=ARGV[2]
total_row_num=ARGV[3]
seed=ARGV[4]
for (i=0; i<length(ARGV); i++) {
printf("ARGV[%d]%s\n", i, ARGV[i]) >> log_file;
}
# ファイルではない引数はエラーになるので削除しておく
delete ARGV[3]
#close(ARGV[3])
delete ARGV[4]
srand(seed);
printf("[総行数]%d件\n", total_row_num) >> log_file;
# 総行数の半分(小数点は切り捨て)
half_rows_num=int(total_row_num/2)
# 総行数の1/4(小数点は切り捨て)
one_fourth_rows_num=int(half_rows_num/2)
# 総行数の3/4
three_fourth_rows_num=one_fourth_rows_num + half_rows_num
printf("[総行数の半分(小数点は切り捨て)]%d件\n", half_rows_num) >> log_file;
printf("[総行数の1/4(小数点は切り捨て)]%d件\n", one_fourth_rows_num) >> log_file;
printf("[総行数の3/4]%d件\n", three_fourth_rows_num) >> log_file;
printf "【start】CSVファイルの加工を開始します。\n" >> log_file;
correct_header="ID,都道府県市区町村コード,市区町村名,基準メッシュ・コード";
correct_col_num=split(correct_header, correct_header_arr, /[,]/);
row_number_processed=1;
# 正規表現
# 半角数字
regex_half_numeric=@/[0-9]/
# 半角英字(小文字)
regex_half_lower_alpha=@/[a-z]/
# 半角英字(大文字)
regex_half_upper_alpha=@/[A-Z]/
# 全角文字
regex_full_width=@/[[:cntrl:][:print:]]*$/
regex_arr[0]=regex_half_numeric
regex_arr[1]=regex_half_lower_alpha
regex_arr[2]=regex_half_upper_alpha
regex_arr[3]=regex_full_width
}
{
# 1行目
if (NR == 1) {
print $0
split($0, csv_header, ",")
next
}
if (NR != 1) {
if (row_number_processed >= total_row_num) {
printf("[現在の行数]%s\n", row_number_processed) >> log_file
close(log_file)
close(input_csv_file)
#next
#break
exit
}
printf("[row]%d\n", row_number_processed) >> log_file
printf("[input][$1]%s\n", $1) >> log_file
printf("[input][$2]%s\n", $2) >> log_file
printf("[input][$3]%s\n", $3) >> log_file
printf("[input][$4]%s\n", $4) >> log_file
# 1/4行目から3/4行目まで
if (NR >= one_fourth_rows_num && NR <= three_fourth_rows_num) {
printf("[modify clomun value][row]%d\n", row_number_processed) >> log_file
printf("[before][$1]%s\n", $1) >> log_file
printf("[before][$2]%s\n", $2) >> log_file
printf("[before][$3]%s\n", $3) >> log_file
printf("[before][$4]%s\n", $4) >> log_file
# 1カラム目
# 置換後の値に差し替え
$1=replace_char_column($1, regex_arr)
# 2カラム目
# 置換後の値に差し替え
$2=replace_char_column($2, regex_arre)
# 3カラム目
# 置換後の値に差し替え
$3=replace_char_column($3, regex_arr)
# 4カラム目
# 置換後の値に差し替え
$4=replace_char_column($4, regex_arr)
printf("[after][$1]%s\n", $1) >> log_file
printf("[after][$2]%s\n", $2) >> log_file
printf("[after][$3]%s\n", $3) >> log_file
printf("[after][$4]%s\n", $4) >> log_file
}
# 出力
print $1, $2, $3, $4
row_number_processed++;
}
#next
}
END {
printf "【finish】CSVファイルの加工を終了します。\n" >> log_file;
printf("処理件数%d件\n", row_number_processed) >> log_file;
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 関数定義
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 列(カラム)の値を変更する
# ■ 引数
# ■ param string target_column
# ■ param object regex_arr
# ■ 戻り値
# ■ return string join_arr_element
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function replace_char_column(target_column, regex_arr){
delete target_column_arr
join_arr_element = ""
# 文字の配列にする
n = split(target_column, target_column_arr, "")
for (i = 1; i <= n; i++) {
# 先頭の1文字目の場合
if (i == 1) {
target_column_arr[1]=replace_char(select_rand_regex(regex_arr))
#printf("target_column_arr[0]%s\n", target_column_arr[0])
}
# 配列の要素を結合する
join_arr_element = join_arr_element target_column_arr[i]
}
# 置換後の値を返却
return join_arr_element
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 配列(正規表現)のインデックスをランダムに選択する
# ■ 引数
# ■ param array regex_arr
# ■ 戻り値
# ■ return int select_index
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function select_rand_regex(regex_arr){
# 選択する正規表現
select_index=length(regex_arr) * rand();
return select_index;
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ 1文字を返す
# ■ 引数
# ■ param int select_index
# ■ 戻り値
# ■ return string 1文字
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function replace_char(select_index){
replaced_char=""
#printf("[select_index]%d\n", select_index)
# 選択された正規表現
switch (int(select_index)) {
case 0:
return rand_select_regex_half_numeric();
break;
case 1:
return rand_select_regex_half_lower_alpha();
break;
case 2:
return rand_select_regex_half_upper_alpha();
break;
case 3:
return rand_select_regex_full_width();
break;
default:
break;
}
# if (int(select_index) == 0) {
# return rand_select_regex_half_numeric();
# }
# if (int(select_index) == 1) {
# return rand_select_regex_half_lower_alpha();
# }
# if (int(select_index) == 2) {
# return rand_select_regex_half_upper_alpha();
# }
# if (int(select_index) == 3) {
# return rand_select_regex_full_width();
# }
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ ランダムに半角数字を1文字を返す
# ■ 引数
# ■ なし
# ■ 戻り値
# ■ return 半角数字1文字
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function rand_select_regex_half_numeric(){
delete arr
n = split("0123456789", arr, "");
#printf("[rand_select_regex_half_numeric()]arr[int(n * rand()]%s\n", arr[int(n * rand())])
return arr[int(n * rand())];
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ ランダムに半角英字(小文字)を1文字を返す
# ■ 引数
# ■ なし
# ■ 戻り値
# ■ return 半角英字(小文字)1文字
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function rand_select_regex_half_lower_alpha(){
delete arr
n = split("abcdefghijklmnopqrstuvwxyz", arr, "");
#printf("[rand_select_regex_half_lower_alpha()]arr[int(n * rand()]%s\n", arr[int(n * rand())])
return arr[int(n * rand())];
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ ランダムに半角英字(大文字)を1文字を返す
# ■ 引数
# ■ なし
# ■ 戻り値
# ■ return 半角英字(大文字)1文字
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function rand_select_regex_half_upper_alpha(){
delete arr
n = split("ABCDEFGHIJKLMNOPQRSTUVWXYZ", arr, "");
#printf("[rand_select_regex_half_upper_alpha()]arr[int(n * rand()]%s\n", arr[int(n * rand())])
return arr[int(n * rand())];
}
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
# ■ ランダムに全角文字を1文字を返す
# ■ 引数
# ■ なし
# ■ 戻り値
# ■ return 全角文字1文字
# ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
function rand_select_regex_full_width(){
delete arr
n = split("ABCDEFGHIJKLMNOPQRSTUVWXYZあかさたな佐藤鈴木田中高橋", arr, "");
#printf("[rand_select_regex_full_width()]arr[int(n * rand()]%s\n", arr[int(n * rand())])
return arr[int(n * rand())];
}
■/home/ts0818/work/test_validate/tool/make_test_data.sh
#!/bin/bash
# 結果格納用
output_dir=./output
mkdir -p ${output_dir}
# アウトプットのCSVファイル
output_csv_file=${output_dir}/test_data.csv
# 処理開始日時
START_TIME=$(date +%Y%m%d_%H%M%S_%3N)
# ログファイル
log_file=${output_dir}/log_${START_TIME}.log
echo -e "START_TIME"'\t'"${START_TIME}" | tee -a ${log_file}
# このシェルスクリプトのファイルがある位置に移動
cd `dirname $0`
# 今いる場所を表示
WORK_DIR=$(pwd)
echo -e "current_directory:"'\t'"${WORK_DIR}" | tee -a ${log_file}
# インプットのCSVファイル
input_csv_file=/home/ts0818/work/test_validate/data/file/csv/13.csv
# インプットのCSVファイルの行数
rows_input_csv_file=$(cat ${input_csv_file} | wc -l)
# インプットのCSVファイルの内容を加工し、新たなCSVファイルに出力
awk -F ',' -f awk/make_test_data.awk ${input_csv_file} ${log_file} ${rows_input_csv_file} $RANDOM > ${output_csv_file}
# 処理終了日時
FINISH_TIME=$(date +%Y%m%d_%H%M%S_%3N)
echo -e "FINISH_TIME"'\t'"${FINISH_TIME}" | tee -a ${log_file}
で、「make_test_data.sh」を実行すると、
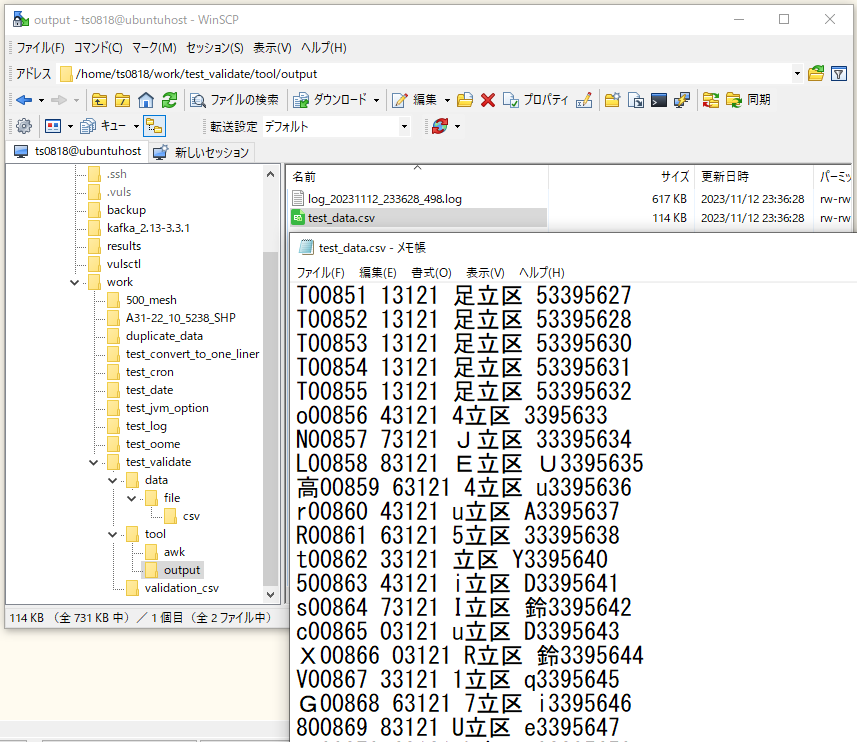
⇧ CSVファイルを加工(各カラムの先頭1文字だけですが)した内容で、新しいCSVファイルを生成されます。
文字列をsplitした時に生成される配列のインデックスの始まりが、1からとかって言うのも罠過ぎる...最初、気付かずに、当然0始まりだろうと考えてたから、先頭に1文字追加されてしまっていたのに気付くのに時間かかりましたわ...
▼以下、参考にさせていただいたサイト様
■正規表現など
■乱数など
■複数ファイルなど
■関数など
何て言うか、awkはよく分からんことが多過ぎる...
CSVファイルの読み込み処理と書き込み処理の両方を行う場合、読み込んだ行数を自分で把握して、exitしないと無限ループになるとか、罠過ぎる...
素直に、1行ずつループ処理で制御できるようにさせてくれれば良いものを、awk側でわけ分からんループのさせ方を強制させられるから、本当に扱い辛いことこの上ないですわ...
あと、数字の比較が分かり辛い...
わざわざ、明示的にint()で整数にしないといけないんなら、静的型付けのようにデータ型をハッキリさせて欲しいですわ...
その他、諸々、分かり辛いことのオンパレードで、且つ、現在進行形ですわ...
毎度モヤモヤ感が半端ない...
今回はこのへんで。