
募集背景には、「KADOKAWAグループではこれまで(情報セキュリティや情報管理を)各社で個別運用していたが、ガバナンス強化やコンプライアンス強化を目的に、グループ横断での情報セキュリティ管理体制の構築や社内規定の見直しを図っている」などと説明。数年単位を想定した新たな情報セキュリティ体制の構築を目指す。
KADOKAWAグループ、セキュリティエンジニア募集中 最大年収800万円 「0→1を経験」 - ITmedia NEWS
⇧ KADOKAWAグループ社内でセキュリティエンジニアを育成する方針の話は出なかったのかしらね...
PostgreSQLの「過大属性格納技法(TOAST:The Oversized-Attribute Storage Technique)」とは
「第47回PostgreSQLアンカンファレンス」に参加して、
- 過大属性格納技法(TOAST:The Oversized-Attribute Storage Technique)
という機能が存在することを知ったのですが、どんな目的を実現する想定で用意されているものなのかが分からなかったので調べてみました。
PostgreSQLの公式ドキュメントの日本語版によると、
PostgreSQLは固定長のページサイズ(通常8キロバイト)を使用し、複数ページにまたがるタプルを許しません。 そのため、大規模なフィールド値を直接格納できません。 この限界を克服するため、大規模なフィールド値を圧縮したり、複数の物理的な行に分割したりしています。 これはユーザからは透過的に発生し、また、バックエンドのコード全体には小さな影響しか与えません。
この技法はTOAST(または「パンをスライスして以来最善のもの」)という愛称で呼ばれます。 [訳注:TOASTはパンのトーストと綴りが同じなので、スライスしたパンを美味しく食べる方法に掛けて洒落ています。] TOASTの基盤は大きなデータ値のインメモリで処理の改善にも使用されています。
⇧ とのこと。
う~む、分からん。
前提として、
■PostgreSQLシステム上の制限
- 『PostgreSQLは固定長のページサイズ(通常8キロバイト)を使用し、複数ページにまたがるタプルを許しません。 そのため、大規模なフィールド値を直接格納できません。』
■解決策
- 『この限界を克服するため、大規模なフィールド値を圧縮したり、複数の物理的な行に分割したりしています。 』
ということらしく、この「解決策」を実現する技法のことを、
- 過大属性格納技法(TOAST:The Oversized-Attribute Storage Technique)
と命名してるらしい。
PostgreSQLのタプルって何なのか
そもそもとして、PostgreSQLの「タプル」って何?
PostgreSQLの公式のドキュメントの日本語版だと、
属性を一定の順序で集めたもの。 この順序はタプルが含まれるテーブル(または他のリレーション)によって定義されます。その場合タプルは、しばしば行と呼ばれます。 また結果セットの構造によって定義される場合もあります。その場合、タプルはレコードと呼ばれることがあります。
https://www.postgresql.jp/docs/16/glossary.html#GLOSSARY-TUPLE
タプル内にある特定の名前とデータ型を持つ要素。
https://www.postgresql.jp/docs/16/glossary.html#GLOSSARY-TUPLE
⇧ 上記のような説明になっている。
う~む、分からん。
PostgreSQLのアーキテクチャが関係しているらしい
とりあえず、
富士通が後述の資料を参考にまとめたのだろうなと思われる記事。 非常によくまとまっているのでわかりやすい。
もっと細かく知りたいならPostgreSQL Internalsがおすすめ。 富士通の資料と重複するところがあるがこっちが本家。 Githubで管理されているので誤字脱字などあったら気軽にPRを出してほしい。
⇧ 上記サイト様が紹介してくれているサイトの情報を見てみる。
■PostgreSQLの基本構成
PostgreSQLの基本的な構成について説明します。はじめに、主なプロセス、メモリー、および、ファイルについての構成図を示します。
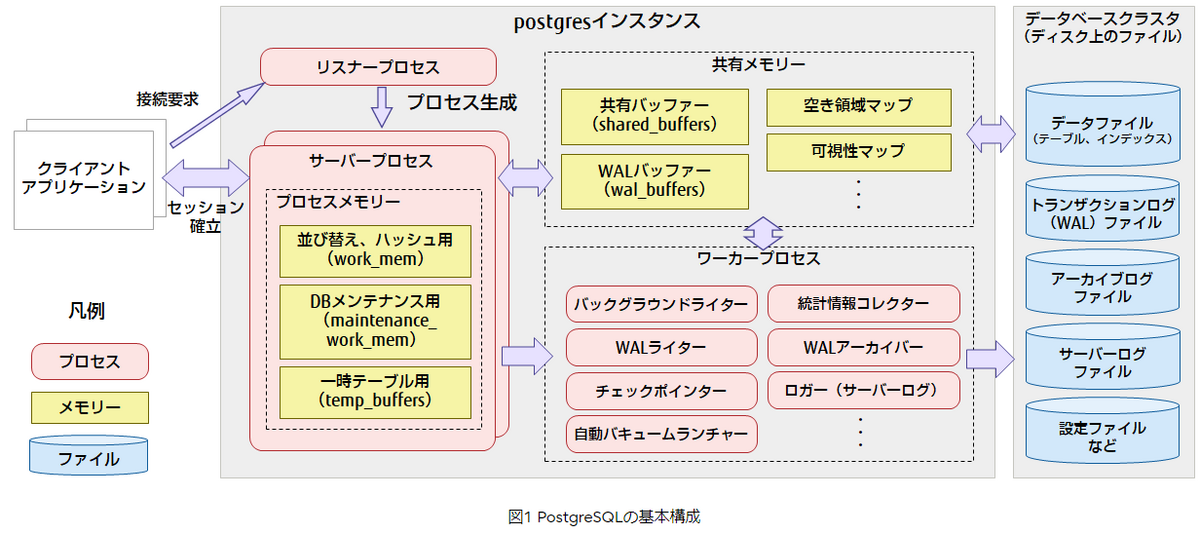
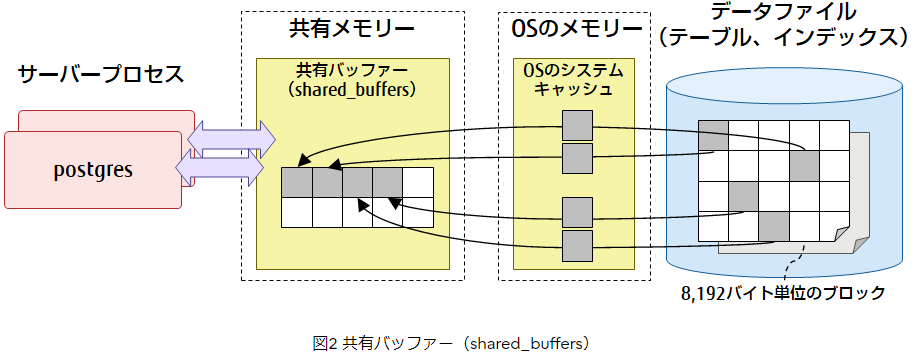
■共有バッファー(shared_buffers)
ディスク上にあるテーブルやインデックスのデータを、ブロック単位で共有メモリー上にキャッシュするための領域です。データファイルは、複数の8,192バイトのブロックで構成されおり、この単位でキャッシュします(OSのシステムキャッシュを経由します)。PostgreSQLのサーバープロセスは、共有バッファー上のテーブルやインデックスのデータにアクセスすることで、ディスクI/Oを削減しパフォーマンスを向上させます。共有バッファーに読み込まれたブロックは、「ページ」と呼びます。なお、各種技術文書では、「ページ」のことを「ブロック」や「バッファー」と表現されることもあります。
■PostgreSQLの基本的なアーキテクチャ
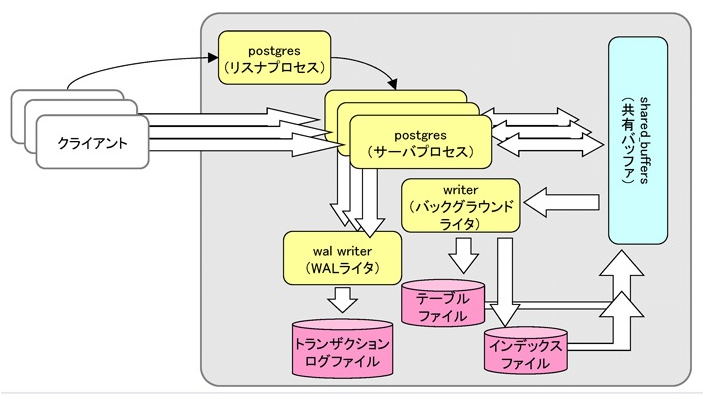
図の一番右側に共有バッファと呼ばれるメモリの空間がありますが、PostgreSQLの基本的なアーキテクチャというのは、共有バッファを中心として複数のプロセッサに連携しながら処理を行うというものです。
⇧ とあり、PostgreSQLでディスクとしている場所に保管しているデータをメモリ上に展開する際に、
『データファイルは、複数の8,192バイトのブロックで構成されおり、この単位でキャッシュします(OSのシステムキャッシュを経由します)』
『共有バッファーに読み込まれたブロックは、「ページ」と呼びます。なお、各種技術文書では、「ページ」のことを「ブロック」や「バッファー」と表現されることもあります。』
という制限があることから、
『PostgreSQLは固定長のページサイズ(通常8キロバイト)を使用し、複数ページにまたがるタプルを許しません。』
の話に戻ってくると。
PostgreSQLにおける「Tuple」が何なのか今いちハッキリしないのだけど、現状のPostgreSQLのアーキテクチャでは、
- PostgreSQLは固定長のページサイズ(通常8キロバイト)を使用
- 複数ページにまたがるタプルを許しません。
という縛りがあるせいで、
- 過大属性格納技法(TOAST:The Oversized-Attribute Storage Technique)
という仕組みが必要になったと。
と言うか、
PostgreSQLで可変長データ型を扱う時、内部的にはTOASTと呼ばれる機構を利用して、別の隠しテーブルに可変長のデータを格納するようになっている。この時、可変長のデータは適正な長さに分割されて格納されるので、タプル一個あたりのデータ長がブロックサイズを超える事はない。
⇧ 上記サイト様によりますと、PostgreSQL内部の処理で利用されている機能だったっぽい。
すごく雑に言うと、超長いデータを8KB固定のページに収めるための技術。
ユーザからみると基本的にはこれを意識することなく、勝手にPostgreSQLでやってくれる。
TOAST機能でデータを圧縮する場合、従来は規定の圧縮方式(pglz)のみを使っていたが、PostgreSQL 14からはlz4を選択可能になった。
⇧ 圧縮方式とかが設定できるそうな。
一応、PostgreSQL 17が出てはいるけど、現時点で、日本語版のドキュメントが用意されてるのが、PostgreSQL 16までっぽいので、PostgreSQL 16のドキュメントがの日本語版を確認したところ、
行内あるいは行外の圧縮データで使用される圧縮技術は、CREATE TABLEまたはALTER TABLEでCOMPRESSION列オプションを設定することで各列に対して選択できます。 明示的な設定のない列に対するデフォルトは、データが挿入されるときにdefault_toast_compressionパラメータを参照することです。
この変数は圧縮可能な列の値のデフォルトTOAST圧縮方式を設定します。 (これはCREATE TABLEあるいはALTER TABLEのCOMPRESSION列オプションを設定することにより、置き換えることができます。) サポートされている圧縮方式は、pglzとlz4(PostgreSQLが--with-lz4でコンパイルされている場合)です。 デフォルトはpglzです。
https://www.postgresql.jp/docs/16/runtime-config-client.html#GUC-DEFAULT-TOAST-COMPRESSION
⇧ 圧縮方式は、
- pglz
- lz4
の2つというのは変わっていないっぽいのだけど、デフォルトは「pglz」になっていますと。
選択肢が増えてしまったことから、PostgreSQLを利用するユーザーとしても意識せざるを得ないような...
まぁ、
一部のデータ型のみがTOASTをサポートします。 大規模なフィールド値を生成することがないデータ型にオーバーヘッドを負わせる必要はありません。
TOASTをサポートするためには、データ型は可変長(varlena)表現を持たなければなりません。 通常は、格納する値の最初の4バイトワードには値の長さ(このワード自体を含む)がバイト単位で含まれます。 TOASTは残りのデータ型の表現について制限しません。 TOAST化された値として集合的に呼ばれる特別な表現は、この先頭の長さのワードを更新または再解釈することで動作します。
したがって、TOAST可能なデータ型をサポートするC言語関数は、潜在的にTOAST化されている入力値の扱い方に注意しなければなりません。 つまり、入力がTOAST解除されなければ、それは実際には4バイトの長さのワードと内容から構成されていないかもしれないのです。 (通常これは、入力に対して何か作業をする前にPG_DETOAST_DATUMを呼び出すことで行われますが、もっと効率的な方法が可能な場合もあります 詳しくは38.13.1を参照してください)。
⇧ テーブルのカラムのデータ型で、
- 過大属性格納技法(TOAST:The Oversized-Attribute Storage Technique)
が必要になるようなものを採用していなければ関係なさそうではありますが...
毎度モヤモヤ感が半端ない…
今回はこのへんで。