
2024年度からは単なる利用を超えて、より実践的な取り組みに重点を置くようになった。この時期、経済産業省の「GENIAC」プロジェクトによってGPUが国内のAIスタートアップ企業にも行きわたりはじめたが、同時に“日本語データの不足”という新たな課題も顕在化した。「GoogleやFacebookには日本語のデータが豊富にあるものの、日本のスタートアップ企業には十分なデータが蓄積されておらず、GPU資源の確保だけでは学習が進まなかった」と楠氏は振り返る。
デジタル庁 楠正憲氏が進めたAI活用基盤構築──「他国に取り残される」危機感から始めた施策の舞台裏 (2/3)|EnterpriseZine(エンタープライズジン)
この課題を解決すべく、デジタル庁はまず日本語のデータ収集から着手した。その際、著作権の問題が生じない公文書を活用してデータセット構築を試みたが、技術的な困難に直面したという。公文書はすべてPDFかつ縦書きで組版があり、表が混在するなど、非常に複雑な構造だったのだ。これをAIに読み込ませる作業が大変だったと楠氏は明かす。
デジタル庁 楠正憲氏が進めたAI活用基盤構築──「他国に取り残される」危機感から始めた施策の舞台裏 (2/3)|EnterpriseZine(エンタープライズジン)
⇧ ツッコミどころが多過ぎるのだが...
- スタートアップ企業に限定してる理由が分からない
- 公文書の苦労話は良いから成果物の所在を明らかにして欲しい
- 公文書とは具体的にどの分野のものを対象としたのか明らかにして欲しい
とりあえず、「税金」の「使用内訳」を明らかにできる「データ」を公開して欲しいところですな...
と言うのも、
たしかに、消費税法第一条2項には「消費税は…医療費及び介護の社会保障給付並びに少子化に対処するための施策に要する経費に充てるものとする」と書いてある。この条文は2012年8月、野田民主党政権下に書き加えられたもの。当時の民主党は消費税の税率を5%から10%に引き上げようとしており、国民を納得させようとしてこんな条文を書き加えたのだ。
その証拠は政府自身が毎年発表する、「一般会計予算歳出・歳入の構成」を見れば一目瞭然だ(下円グラフ参照)。
円グラフを見ればわかるように、右に一般会計歳入があり、所得税、法人税、消費税等の歳入合計が112兆5717億円となっている。この歳入合計を左側の円グラフの歳出、社会保障費、防衛関係費、公共事業費、国債費等々に充てているのだ。


⇧ 政府組織が、「税金」について、
- 一般会計歳入
- 一般会計歳出
の対応と明確な「使用内訳」を提示できていないのよね...
仕事が適当過ぎるのだが...

(注1)令和5年度までは決算、令和6年度は補正後予算、令和7年度は予算による。点線は当初予算による。
(注2)公債発行額は、平成2年度は湾岸地域における平和回復活動を支援する財源を調達するための臨時特別公債、平成6~8年度は消費税率3%から5%への引上げに先行して行った減税による租税収入の減少を補うための減税特例公債、平成23年度は東日本大震災からの復興のために実施する施策の財源を調達するための復興債、平成24年度及び25年度は基礎年金国庫負担2分の1を実現する財源を調達するための年金特例公債を除いている。

(注1)令和5年度末までは実績、令和6年度末は補正予算、令和7年度末は予算に基づく見込み。
(注2)普通国債残高は、建設公債残高、特例公債残高及び復興債残高。特例公債残高は、昭和40年度の歳入補填債、国鉄長期債務、国有林野累積債務等の一般会計承継による借換債、臨時特別公債、減税特例公債、年金特例公債、GX経済移行債及び子ども・子育て支援特例公債を含む。
(注3)令和7年度末の翌年度借換のための前倒債限度額を除いた見込額は1,074兆円程度。
⇧ 上記のグラフが正しいとすると、1975年に15兆円ほどだったのが、2025年には1129兆円になるかもって、50年でおよそ1115兆円借金が増えたってことなのか?
「買い入れ予定額の減額」という表現が込み入って理解しにくいので、手っ取り早く表現すれば、600兆円近い長期国債を20カ月後に7~8%程度(40兆円超)減額するということだ。
600兆円近くまで膨らんだ日銀保有の国債、買い入れ減額で誰が引き取るのか? 「いばらの道」に踏み出した日銀、切り拓くには投資家の多様化が不可欠(1/5) | JBpress (ジェイビープレス)
⇧ 状況が悪化の一途を辿っているのは疑う余地が無さそうではある...
BOM(Byte Order Mark)とは
Wikipediaによると、
バイト順マーク (バイトじゅんマーク、英: byte order mark) 、バイトオーダーマークあるいはBOM(ボム)は、Unicodeの符号化形式で符号化したテキストの先頭につける数バイトのデータ。元にUnicodeで符号化されていることおよび符号化の種類の判別に使用する。
概要
プログラムがテキストデータを読み込む時、その先頭の数バイトからそのデータがUnicodeで表現されていること、また符号化形式(エンコーディング)としてどれを使用しているかを判別できるようにしたものである。
経緯
Unicodeが開発された当初は、アメリカではASCII、ヨーロッパなどではISO-8859、日本ではShift_JISやEUC-JPといった他の文字コードが主流であり、使用されている符号化方式がUnicodeのものであることを明示する必要があった。また、Unicodeの符号化方式は複数あり、特にUTF-16やUTF-32にはそれぞれエンディアンが異なる2種類があるため、符号化方式同士を区別する必要があった。その方法として、先頭のデータにテキスト以外のデータを入れることが発案された。
⇧ とあり、「文字コード」が元凶らしい...
使用するべきか否か
実際にBOMを使用すべきか、あるいは使用すべきでないかは、Unicodeを利用したより上位の仕様によって定められることがある。"XML Media Types" (RFC 3023) では、XMLをUTF-16で符号化する場合は先頭のBOMを必須とし、またXMLを解釈するソフトウェアでは、先頭にBOMがあった場合はxml宣言における<?xml encoding="..."?>の指定よりも優先してエンコーディングを判別すべきとしている。
JSONの場合は、ネットワークで送信する場合はBOMを付けてはならないとしている。
UTF-8は文字コードとしてASCIIを前提としたプログラムでもおよそ支障なく動作するように設計されているが、BOMによって正常に処理できなくなる場合がある。Unicodeの規格において、UTF-8においてBOMは容認されるが、必須でも勧められるものでもないとされている。また、データベースやメモリにロードするデータなど、内部的なデータ形式では、プログラムの性能や効率の観点から普通BOMは用いられない。
⇧ 概ね、「BOM(Byte Order Mark)」は悪影響しかもたらさないような気がするのだが...
「XML(Extensible Markup Language)」を扱っているような「システム」の場合を除いて「BOM(Byte Order Mark)」を利用する機会は無いような気がするのだが、どうなのだろうか?
「Phind」に質問してみたところ、以下の回答が返ってきた。
■XMLを利用しているシステム
| システム名 | 主な用途 | 技術的特徴 | 利点 | 適用場面 |
|---|---|---|---|---|
| EDINET | 有価証券報告書の管理・公開 | XBRLフォーマット、API連携 | 標準化されたデータ形式、効率的な検索 | 企業の財務情報公開 |
| Yakumo | 全文検索システム | PostgreSQL/PGroonga | 高速な検索機能、詳細なデータ管理 | 文書の効率的な検索・分析 |
| SWIFT | 国際決済取引 | 標準化されたメッセージフォーマット | 安全性の高いデータ交換 | 銀行間の取引データ処理 |
| 税務申告システム | 電子申告処理 | 大量データ処理対応 | 自動処理による効率化 | 税務データの集計・分析 |
| 統計データベース | 複雑な統計データ管理 | 階層構造対応 | 詳細なデータ分析 | 統計情報の管理・分析 |
■システム特徴
| 機能要件 | EDINET | Yakumo | SWIFT | 税務システム | 統計DB |
|---|---|---|---|---|---|
| データ標準化 | ◎ | ○ | ◎ | ◎ | ◎ |
| 検索機能 | ○ | ◎ | △ | ○ | ○ |
| セキュリティ | ◎ | ○ | ◎ | ◎ | △ |
| スケーラビリティ | ◎ | ○ | ◎ | ◎ | ○ |
| 実装複雑度 | 高 | 中 | 高 | 中 | 低 |
何となく、旧い「システム」が「XML(Extensible Markup Language)」を利用しているような感じなんかな?
ただ、「XML(Extensible Markup Language)」を除いて、
⇧ 普通に利用していれば「BOM(Byte Order Mark)」が入り込む余地は無さそうではあるが...
LinuxのdiffコマンドはBOM(Byte Order Mark)を無視するオプションが無いのだが...
なのだが、「Linux」環境で、
- BOM(Byte Order Mark)が付与されている
- 改行コードがCRLFである
という状態の「CSV(Comma Separated Values)」ファイルに遭遇してしまったのだが、困ったことに、「Linux」の標準的なコマンドである「diff」では「1. BOM(Byte Order Mark)が付与されている」を無視して比較するオプションが用意されていないようなのだ。
で、ネットの情報を漁っていたところ、

⇧ 上記サイト様によりますと、「vi」で「テキストファイル」から「BOM(Byte Order Mark)」を付与したり、取り除いたりできるらしい。
ちなみに、「diff」コマンドのオプション「--strip-trailing-cr」については、
『strip trailing carriage return on input』
という説明になっており、翻訳にかけたところ、
『入力時に末尾のキャリッジリターンを削除する』
という挙動をするらしいので、「テキストファイル」の内容を比較する際に「CR」を無いものとするらしい。
なので、「改行コード」が「CR」の「テキストファイル」の場合は、上手くいかない気がする...
ちなみに、Wikipediaの「改行コード」のページの説明によると、
改行コード(かいぎょうコード)とは、ワードプロセッサ(ワープロ専用機)やコンピュータなどで、改行を表す制御文字である。日本では「改行コード」と総称する事が一般的なため、本項目では、キャリッジリターン (CR) とラインフィード (LF) の両方について記載する。
概要
改行コード(広義)は以下の2種類であり、システム(ソフトウェア)により片方または両方が使用される。
- キャリッジリターン(英: carriage return、CR、復帰)
- ラインフィード(英: line feed、LF、狭義の改行)またはニューライン(newline、line break または end-of-line、EOL)
これらの用語はタイプライターが由来である。
改行の数値表現
多くのシステムでは、改行コードを1つまたは連続する2つの特殊文字で表している。
⇧ 上記のような説明となっている。
話が脱線しましたが、
| No | ファイル名 | 改行コード | BOM(Byte Order Mark) |
|---|---|---|---|
| 1 | ansible_network_modules.csv | CRLF | あり |
| 2 | tmp_ansible_network_modules.csv | LF | なし |
の「テキストファイル」の内容の比較を「diff」コマンドで行います。
■オプション「--strip-trailing-cr」を利用して、diff コマンドを実行する
diff --strip-trailing-cr ansible_network_modules.csv tmp_ansible_network_modules.csv
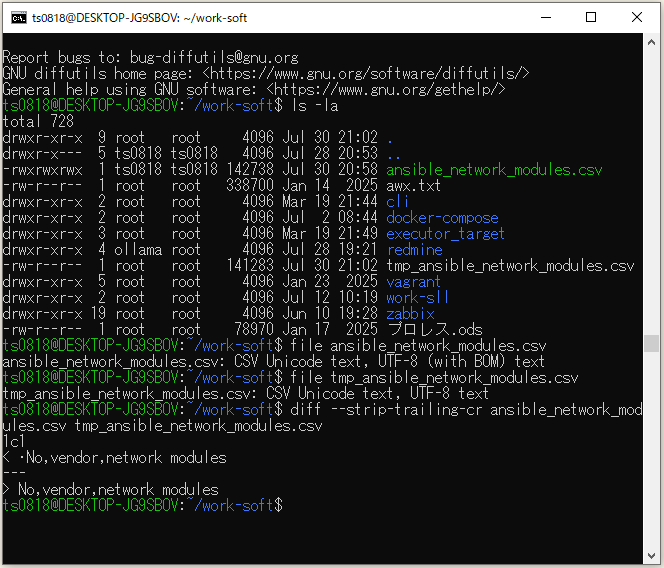
⇧ 上記のキャプチャ画像からも分かるように「BOM(Byte Order Mark)」のあるなしの差分が出力されてしまう...
■「CSV(Comma Separated Values)」ファイルに「BOM(Byte Order Mark)」を付与する
sudo vi -c 'set bomb' -c ':wq!' tmp_ansible_network_modules.csv
■オプション「--strip-trailing-cr」を利用して、diff コマンドを実行する
diff --strip-trailing-cr ansible_network_modules.csv tmp_ansible_network_modules.csv

差分が無くなりました。
元の状態に戻しておきます。
■切り戻し(「CSV(Comma Separated Values)」ファイルに「BOM(Byte Order Mark)」を取り除く)
sudo vi -c 'set nobomb' -c ':wq!' tmp_ansible_network_modules.csv

とりあえず、「Linux」環境であれば、「XML(Extensible Markup Language)」を除く「テキストファイル」については、
- BOM(Byte Order Mark)が付与されていない
- 改行コードがLFである
という状態が自然な気がしますかね。
何某かの意図があって、
- BOM(Byte Order Mark)が付与されている
- 改行コードがCRLFである
としている場合は、ドキュメントに残しておいて欲しいお気持ち...
毎度モヤモヤ感が半端ない…
今回はこのへんで。