
「GAFA」は「GAMA」に? Facebookの新社名「Meta」で大喜利状態 「MAMAA」なども登場 - ITmedia NEWS
⇧「メメタァ~!(『ジョジョの奇妙な冒険:第一部』)」じゃないけど、なかなか思い切りが良いですね。
というわけで、「SchemaSpy」というツールを試してみました。
レッツトライ~。
一般的にテーブル設計の進め方って?
「エンタープライズ系」の開発の話になりますが、「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」が公開している資料によりますと、

⇧ 上記のページの「要件定義」のリンクをクリックで遷移する先のページの、

⇧「機能要件の合意形成技法」のリンクをクリックで遷移する先のページの、

⇧「機能要件の合意形成ガイド」のリンクをクリックして遷移する先のページの、

⇧「4.データモデル編」のリンクをクリックして参照できるPDFの、

⇧ 5ページ目に、「外部設計」の工程で作成すべき成果物の中の一部として「データモデル編」が位置付けられてることが確認でき、


⇧ 工程の順番的には、
- ER図
- エンティティ一覧
- エンティティ定義
- CRUD図
の流れで作成された成果物を元に、実際に「データベース」に「テーブル」を作成するための「SQL」を作ったりするのがスタンダードではあるっぽい。
ただ、昨今、「NoSQL」とか「NewSQL」とか「GQL(Graph Query Language)」とか、標準的な「SQL」とは毛色の違う存在もあるので、何とも言えないけど。
そして、システムにどんなデータ項目が必要かの全量の洗い出しとかは、「要求定義」や「要件定義」の段階でヒアリングしておく必要はあるっぽいんですかね。
なんか、「要件定義」で「ER図」とかも決めるみたいな話も出てて、情報に統一感が無いというね...

⇧ 上記ページの「サンプル」をダウンロードして中身を見てみたところ、
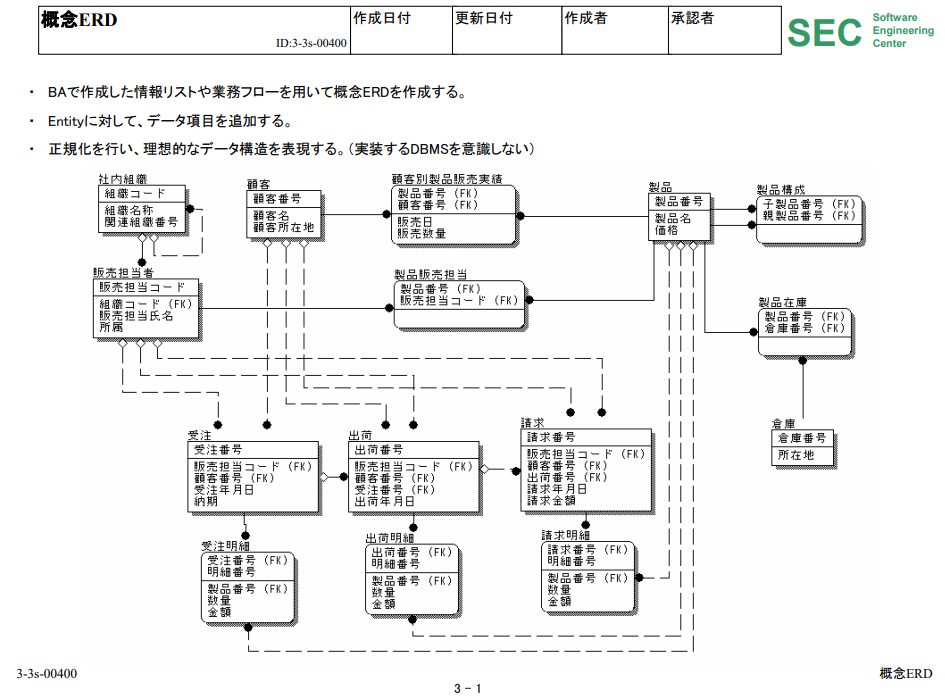
■000004942.zip\概念ERD.pdf
■000004948.zip/データ項目定義.pdf

⇧ とかが決まったら、
■000004985.zip/論理ERD.pdf
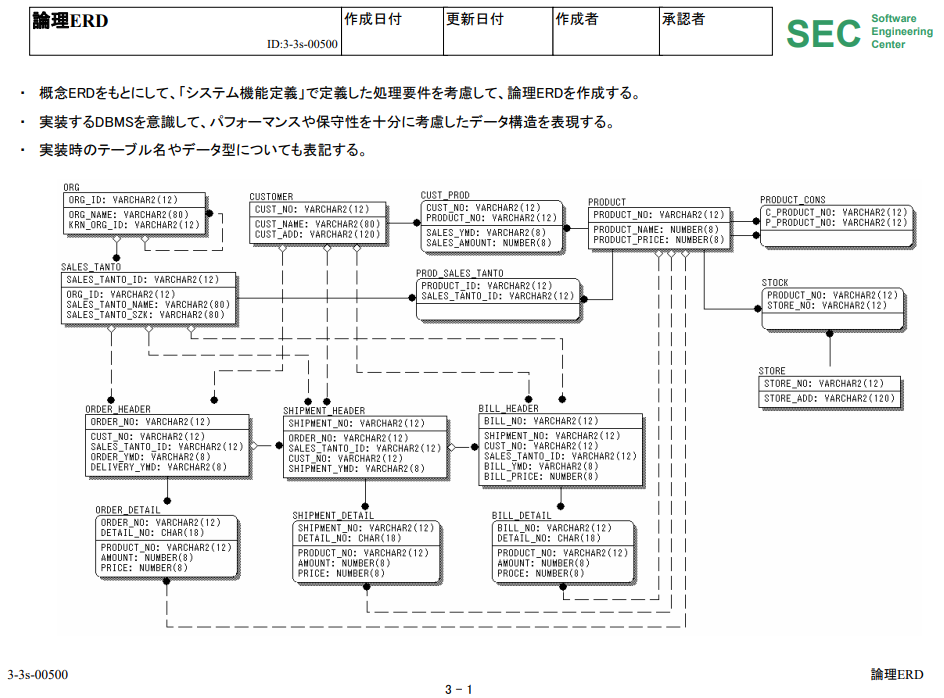
⇧「論理ER図(Logical Entity-Relationship Diagram)」で、具体的に決めていく流れということみたいですね。
「概念ER図(Conceptual Entity-Relationship Diagram)」でしか「外部キー(FK:Foreign Key)」は読み取れないっぽいですね。
「外部設計」の工程で作成するって言ってた説のほうでは、

⇧ おそらく、「テーブル」の「カラム名」になるであろうと思われる「属性名」で「外部キー(FK:Foreign Key)」が分かるようにしてるっぽいのだけど、普通に考えて、「主キー(PK:Primary Key)」とかみたいに、定義書に枠を作って整理したほうが良いような気がするんだけど...
そもそも、結局のところ、「要件定義」と「外部設計」のどっちの工程で「データモデル」に関わる作業をしていくのが正なのか、「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」内でも揺蕩っている状況だから、実際の開発現場が混沌とするのは致し方ないですかね...
ちなみに、「特許庁」が公開してる資料によると、


⇧「別紙2(特許庁システム開発(システム刷新&新規システム構築編)のシステム開発手順における入力/出力成果物関係図)(PDF:195KB)」を確認してみたところ、

⇧ 上図によりますと、
| 工程 | プロセス | 成果物 | |
|---|---|---|---|
| 入力成果物 | 出力成果物 | ||
| 基本設計 (外部設計) |
ソフトウェア 要件定義プロセス |
||
| ■システム要件定義書 ■システム方式設計書 |
■概念データモデル定義書 | ||
となっていって、「特許庁」の公開してる資料が正しいと仮定して矛盾しない場合、「工程」と「プロセス」のどっちでも「要件定義」が出てくるみたいなので、「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」で「要件定義」と言っていたのは、「ソフトウェア要件定義プロセス」のことを言っていたということですかね、いやはや、ミスリードを招きかねない資料ですな...
まぁ、そもそも「特許庁」の資料を標準として考えて良いのかも分からないので何とも言えませんが...
「特許庁」の資料「別紙3(特許庁システム開発(システム刷新&新規システム構築編)のシステム開発における出力成果物概要説明)(PDF:136KB)」のほうが「工程」「プロセス」「成果物」の関係一覧が把握しやすいですかね。
「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」には、頑張って情報の整理をしてもらいたいところですかね...
リバースエンジニアリングとは?
Wikipediaさんに聞いてみる。
Reverse engineering (also known as backwards engineering or back engineering) is a process or method through the application of which one attempts to understand through deductive reasoning how a device, process, system, or piece of software accomplishes a task with very little (if any) insight into exactly how it does so.
⇧ 演繹的推論を通じて理解する試みとあり、「Software」の分野だと、
Software
In 1990, the Institute of Electrical and Electronics Engineers (IEEE) defined (software) reverse engineering (SRE) as "the process of analyzing a subject system to identify the system's components and their interrelationships and to create representations of the system in another form or at a higher level of abstraction" in which the "subject system" is the end product of software development.
Reverse engineering is a process of examination only, and the software system under consideration is not modified, which would otherwise be re-engineering or restructuring. Reverse engineering can be performed from any stage of the product cycle, not necessarily from the functional end product.
There are two components in reverse engineering: redocumentation and design recovery. Redocumentation is the creation of new representation of the computer code so that it is easier to understand. Meanwhile, design recovery is the use of deduction or reasoning from general knowledge or personal experience of the product to understand the product's functionality fully.
It can also be seen as "going backwards through the development cycle.
⇧ みたいな感じで、開発の工程で成果物が抜け落ちてる状況でシステム開発が進んでしまった場合に対する処置として行うことが多そうですと。
ちなみに「リファクタリング(Refactoring)」はと言うと、
"Refactor" redirects here.
In computer programming and software design, code refactoring is the process of restructuring existing computer code—changing the factoring—without changing its external behavior. Refactoring is intended to improve the design, structure, and/or implementation of the software (its non-functional attributes), while preserving its functionality.
⇧ 英語版のWikipediaによると、『"Refactor" redirects here.』とページ冒頭で説明があって、ページ上で右クリックして「日本語に翻訳」したところ『「リファクタリング」はここにリダイレクトします。』と訳されたことから、「Refactoring」というと「Code Reafctoring」を意味するってことなんですかね?
「Reverse Engineering」と「Refactoring」の違いってのは、「Refactoring」は完全に「code」ベースで考えていくってことになるんかね?
このあたりの、違いなんかについても、「喧々囂々(けんけんごうごう)」と「侃々諤々(かんかんがくがく)」じゃないですけど、説明してくれてる人は多いのですが、根拠としたドキュメントとかが不明瞭なので、判断がつきませんな...
データベースにおけるリバースエンジニアリング
改めて、「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」の情報によると、「データベース」の「テーブル」とかを作るための「データモデリング」に関する設計の一般的な工程の流れは、
- ER図
- エンティティ一覧
- エンティティ定義
- CRUD図
となるのが望ましいようですが、「ER図(Entity-Relationship Diagram)」を作らないまま開発が進んでしまうことは、あるあるらしいですと。
「RDBMS(Relational Database Management System)」以外だと、「ER図(Entity-Relationship Diagram)」とか考えなくて良いのかも知らんけど。
そんな「データベース」の「テーブル」同士の関係ってどうなってるんだっけ?ってのを表現してる「ER図(Entity-Relationship Diagram)」が存在しないので俯瞰して全体見れないんだが、そもそも「テーブル」の数が10000ぐらいある場合でも「ER図(Entity-Relationship Diagram)」って考えなきゃいけないのって考えると恐怖しかないんだが、でも「テーブル」は用意できてるんで...って時に「リバースエンジニアリング」すれば良いんやな!...っていう状況になった時に、使えるツールってどんなのがあるんだっけ?
⇧ 結構いろいろありますと。
で、よく分からんけど、「SchemaSpy」ってのを推してる人が結構多いように見受けられたので、今回は「SchemaSpy」を使ってみることに。
まずは、テーブル定義書を用意
「リバースエンジニアリング」するということで、「ER図(Entity-Relationship Diagram)」を作る前に「データベース」に「テーブル」が作成されている状況を用意したいので、「テーブル」を作成していくことに。
実際の現場だと、どういう方法がスタンダードなのか分からんのですが、Excelとかで「テーブル定義書」を作ってから、実際にSQL文とかでデータベースにテーブルを作成していく流れが、なんとなく一般的なんではなかろうかという独断と偏見で、まずは「テーブル定義書」を作成することに。
で、残念ながら、Microsoft Excelがパソコンに入っていないので、Libre Office Calcを使うことにします。
その前に、「エンティティ定義書」と「テーブル定義書」の関係について「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」は何も説明してくれていないのですが、「エンティティ定義書 テーブル定義書 違い」とかでGoogle検索しても芳しい情報が少ないというね...
また、「特許庁」の資料を参考にしてみると、

⇧「詳細設計」の「工程」の「ソフトウェア方式設計プロセス」の「プロセス」で、「テーブル設計書(詳細設計工程)」が出てきて、これは「論理データモデル設計書」が「出力成果物」になりますと。

⇧「プログラム設計・製造・単体テスト」の「工程」の「ソフトウェア詳細設計プロセス」の「プロセス」で、「テーブル設計書(プログラム設計工程)」が出てきて、これは「物理データモデル設計書」が「出力成果物」になりますと。
「論理設計」と「物理設計」の違いなんかについては、
⇧ 上記サイト様の説明が参考になるかと。
なので、「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」の資料と「特許庁」の資料を合わせて考えると、
■概念データモデル定義書
を元に、「テーブル設計書(詳細設計工程)」、つまり開発現場とかで出てくる「テーブル定義書」が作成されて、「テーブル定義書」を元に「データベース」に「テーブル」を作成するための「SQL」文を作成していく感じでしょうかね。
まぁ、「俺たちは雰囲気でデータベースをやっている」と言いたくなるような、定義の曖昧さが満ち溢れているがために、認識齟齬の雨霰となるのがIT業界ということなんですかね...
というわけで、本来の「工程」順をガン無視して、「テーブル定義書」を作成します。
最終的に「ER図(Entity-Relationship Diagram)」を確認したいので、「テーブル」は3つぐらい作成すれば良いということにして、「テーブル定義書」は3シート作るという事で。
ただ、残念ながら、「テーブル定義書」のフォーマットについては、統一された規格とか無いみたいなので、各々の開発現場に合わせるしかないっぽいですかね。
だとしても、ネットの情報で「外部キー(FK:Foreign Key)」とか考慮してない「テーブル定義書」が多過ぎるのが謎なんだけど...
唯一、「A5:SQL Mk-2」っていうSQLクライアントソフトが、「外部キー(FK:Foreign Key)」も考慮した「テーブル定義書」になってますかね。

⇧「複合主キー(composite primary key)」には対応してない「テーブル定義書」かもですが...
とりあえず、Wikipediaさんの「データモデリング」のページにある「ER図(Entity-Relationship Diagram)」を元に「テーブル定義書」を作成します。

⇧ 上図の通りの「ER図(Entity-Relationship Diagram)」があれば、「テーブル定義書」で作成した「テーブル」から自動で「ER図(Entity-Relationship Diagram)」が作成できたかどうかの答え合わせもできますし。
というわけで、当初、3つの「テーブル」を作ると言ってましたが、5つに変更で。
「テーブル定義書」から「データ定義言語(DDL:Deta Definition Lanugage)」を作成する
今回は、「RDBMS(Relational Database Management System)」の1つであるPostgreSQLを使っていこうとかと。
「テーブル定義書」から「SQL」文を作っていきますが、
データベース言語(データベースげんご、英: database language)は、コンピュータのデータベースを扱うためのコンピュータ言語である。 データベース言語を使うことにより、データベース利用者やアプリケーションソフトウェアは、データベースにアクセスすることができる。 データベースを扱う機能のうち検索 (問い合わせ) が重要であるため、通例は (データベース) 問い合わせ言語とも呼ばれる。 ただしデータベース言語と問い合わせ言語は、概念的に重なる部分もあるが、同義ではない (後述) 。
データベース言語の種類
一般に行われているデータベース言語もしくはデータベース言語要素の分類は、データ操作言語 (DML) 、データ定義言語 (DDL) 、データ制御言語 (DCL) 、である。
- データ操作言語 (DML; Data Manipulation Language)
- 対象データの検索、新規登録、更新、削除のための言語もしくは言語要素
- データ定義言語 (DDL; Data Definition Language)
- データ構造の生成、更新、削除のための言語もしくは言語要素
- データ制御言語 (DCL; Data Control Language)
- アクセス制御のための言語もしくは言語要素
普及しているデータベース言語であるSQLでは、その言語に上記のすべての言語要素が、さまざまな命令文が一つにまとめられた言語体系として、存在している。
⇧ とあるように、「SQL」を使う場合、「データベース」の「テーブル」作成には、「データ定義言語(DDL:Deta Definition Lanugage)」を実現する「SQL」文を用意すれば良いですと。
で、このあたりの自動化について、
⇧ 上記サイト様がコードを公開してくれているので、流用させていただきましょう。
現在インストールされてるPythonを確認するには、
Python の公式パッケージが 1つでもインストールされていれば、py コマンドを利用できます。
現在インストールされているバージョンとパスの一覧は py -0p で確認できます。
⇧ 上記サイト様で紹介されてるように確認できる模様。

バージョンが旧くなってきてる感があるので、前にインストールしていたパッケージ管理ツール「winget」で、インストールできるPythonを確認。


⇧ というか、公式のPythonがどれなのかが非常に分かり辛い...
そして、悲報...

⇧ wingetでインストールする場合、インストール先は指定できない模様...
インストール先として作成したフォルダは空っぽ、私の心も空っぽ...

致し方ないので、Python 3.10のインストール先用のフォルダとして作成しておいたフォルダは削除します。

「py.exe」で使用されるPythonは、インストールされてるPythonの中で一番最新のものに自動で切り替えられちゃうみたいですね。
というか、
⇧ まさかの手動で設定ファイルを作成して対処する必要があるという衝撃の事実に震えますね...
で、さらに、環境変数のパスに追加されてはいるものの、

システム環境変数で、追加されてるPython 2系が有効になっちゃうのか分からんのだけれど、

バージョン確認しても、Python 2系のバージョンしか確認できない始末...

⇧ というか、「Microsoft Store」が出てくる意味が分からんのだが...
⇧ っていうか、どっちも導線を省略し過ぎやろ、そもそも「スタート」に「 [Manage app execution aliases] (アプリ実行エイリアスの管理) 」が見当たらんから...
「設定」>「アプリ」>「アプリ実行エイリアス」で辿り着けますかね。




とりあえず、「オフ」にしてみた。

今度はパスが...
どっちにしろ、実行ファイル(pyhton.exe)の配置されてるディレクトリまで移動するか、実行ファイルまでの絶対パスでコマンドを実行しないと駄目なのね...

⇧ とりあえず、Winodws本体の方に複数のPythonをインストールしてる場合は、「py -0p」でインストールされてるPython一覧がインストール先を含めて確認できるので、そのパスまで移動するか、絶対パスでpython.exeを実行する感じになるんかな...面倒くさ過ぎる...
長々と脱線しましたが、Pythonプロジェクト用のフォルダを作成して、Python仮想環境を作ります。
まず、フォルダを作成しておき、

作成したディレクトリまで移動して、Python仮想環境の作成で。

Python仮想環境ができました。

続きは、「VS Code(Visual Studio Code)」で続けます。


そしたら、Python仮想環境のフォルダ内で、新しいファイルを作成。


そしたらば、Python仮想環境に、ライブラリを追加したいので、「表示(v)」>「ターミナル」を選択。

「ターミナル」が表示されると、自動で、Python仮想環境にログインするためのスクリプトファイルが実行されるようになったみたいです。
そしたらば、まずは、pipをバージョンアップしておきます。

はい、エラー...

何か、「winget」でPythonインストールしたのが良くなかったんかな...
「管理者権限」で「VS Code(Visual Studio Code)」を起動し直します。

今度は、Python仮想環境にログインするスクリプトファイルが自動で実行されなかったので、自分で実行してます。
で、再度、pipのバージョンアップ。

既に、バージョンアップされてるということらしい。pipで「xlrd」ってライブラリをインストールします。


インストールできた模様。
ただ、「xlrd」が脆弱性の問題で、「.xlsx」のサポートができなくなったらしく、
⇧「.xlsx」を使う場合は、「openpyxl」を使う感じになるらしい。
今回は、時間の都合上、「.xls」に拡張子を変更して対応することにしました。以下のような感じで、5シート作ってます。(「テーブル」1つにつき、1シート)

で、Pythonのコーディングは以下のようになりました。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import xlrd
import sys
import types
import os.path
from operator import itemgetter
type2line = {
'char': "\t{colnames} char({sizes})",
'datetime':"\t{colnames} datetime",
'decimal': "\t{colnames} decimal({sizes})",
'integer': "\t{colnames} integer",
'varchar': "\t{colnames} varchar({sizes})",
'bytea': "\t{colnames} bytea",
'text': "\t{colnames} text",
'bigint': "\t{colnames} int8",
'smallint': "\t{colnames} int2",
'real': "\t{colnames} real"
}
def readxlsx(args):
# コマンドラインの引数から (1)スキーマ名 (2)出力先ディレクトリ (3)excelファイル名を受け取る
schema = "public" #args[1] # (1)スキーマ名
outputfolder = "output" #args[2] # (2)出力先ディレクトリ
filepath = "C:/Users/Toshinobu/Desktop/soft_work/python_work/tableAutomate/myenv/tablesample.xls" #args[3] # (3)excelファイル名
try:
wb = xlrd.open_workbook(filepath)
#print(wb)
except Exception as e:
print(e)
return
# 各シートに対して実行
for tablesheet in wb.sheets():
# テーブル名とカラム定義を読み込む
try:
# (5,3)なのでD6からテーブル名を取得
tablename = tablesheet.cell_value(5, 3)
colnames = [x for x in tablesheet.col_values(5)[9:]]
types = [x for x in tablesheet.col_values(10)[9:]]
sizes = [x for x in tablesheet.col_values(12)[9:]]
keys_pk = [x for x in tablesheet.col_values(13)[9:]]
keys_uk = [x for x in tablesheet.col_values(14)[9:]]
keys_fk = [x for x in tablesheet.col_values(15)[9:]]
notnull = [x for x in tablesheet.col_values(16)[9:]]
comments = [x for x in tablesheet.col_values(18)[9:]]
except Exception as e:
print(e)
continue
#finally:
#print('finally clause')
# 出力ファイル名の作成
outputpath = ["C:\\", "Users", "Toshinobu", "Desktop", "soft_work", "python_work", "tableAutomate", "myenv", outputfolder, f"{schema}_{tablename}.sql"]
outputfile = os.path.join(*outputpath)
with open(outputfile, 'wt') as file:
# 読み込んだテーブル名とカラム定義からCREATE TABLE文作成
file.write(f'CREATE TABLE {schema}.{tablename}\n(\n')
# 各カラムの記述を一旦リストへ
fieldlist = list()
for i in range(0, len(colnames)):
coltype = types[i].strip()
s = type2line[coltype]
print(s)
fieldlist.append(s.format(colnames=colnames[i], sizes=sizes[i] if len(sizes)>i else None))
# カラム間をカンマと改行で埋める
file.write(',\n'.join(fieldlist))
if not all('' == k for k in keys_pk):
# PKの定義があればPKの設定も行う
pk = ','.join(list(map(lambda x:x[0], sorted(filter(lambda x: x[1] != '', zip(colnames, keys_pk)), key=itemgetter(1)))))
file.write(f",\n\tCONSTRAINT pk_{tablename} PRIMARY KEY({pk})")
if not all('' == k for k in keys_uk):
# UKの定義があればUKの設定も行う
uk = ','.join(list(map(lambda x:x[0], sorted(filter(lambda x: x[1] != '', zip(colnames, keys_uk)), key=itemgetter(1)))))
file.write(f",\n\tCONSTRAINT uk_{tablename} UNIKE KEY({uk})")
#if not all('' == k for k in keys_fk):
# # FKの定義があればFKの設定も行う
# fk = ','.join(list(map(lambda x:x[0], sorted(filter(lambda x: x[1] != '', zip(colnames, keys_fk)), key=itemgetter(1)))))
# file.write(f",\n\tCONSTRAINT fk_{tablename} FOREIGN KEY({fk})")
if not all('' == k for k in notnull):
# NOT NULLの定義があればFKの設定も行う
fk = ','.join(list(map(lambda x:x[0], sorted(filter(lambda x: x[1] != '', zip(colnames, notnull)), key=itemgetter(1)))))
file.write(f",\n\tNOT NULL")
file.write('\n);\n')
# コメント登録のSQLも作る
for i in range(0, min(len(colnames),len(comments))):
file.write(f"COMMENT ON COLUMN {schema}.{tablename}.{colnames[i]} IS '{comments[i]}';\n")
argvs = sys.argv
readxlsx(argvs)
⇧ ってな感じで、保存。
テーブル定義書の作りによって、Pythonのコーディングの中で、列と行の数字が変わってくると思うので、各々のテーブル定義書の作りに合わせてください、ファイルのパスなんかも。
今回「外部キー(FK:Foreign Key)」をPythonで付与するのは難しそうだと判断して、テーブル作成後に手動で設定していくことに。参考サイト様のコードでも「外部キー(FK:Foreign Key)」について触れてなかったですし。
あと、Windows特有のパスの問題もあったので、コマンドライン引数は使わない方向で、べた書きでコーディングしてます、いや、コマンドライン引数を上手いこと処理すれば良いのですが、やり方を調べる時間が無かったこともあり...。
「外部キー(FK:Foreign Key)」とかについては、Excelとかであれば「VBA(Visual Basic for Applications)」とかで上手いこといけるんですかね?
「createTableAll.sql」は後述するところで必要になるので、現状、必要ないのですが、「tablesample.xls」が「テーブル定義書」で、それがあれば大丈夫かな。

で、実行すると、


⇧ 出力先に指定した場所に「SQL」ファイルが作成できています。
最近、PostgreSQLの新しいバージョンが出ていることもあり、PostgreSQLをインストールしていこうと思いますが、自分の環境では、以前にPostgreSQLをインストールしてるため、「タスク マネージャー」で「PID」を確認して、

コマンドプロンプトを管理者権限で起ち上げて、以下のコマンドで、「PID」と「ポート番号」が確認できるようなのですが、
netstat -naob

⇧ 出力された結果を、「postgres.exe」で抜粋してみたところ、
プロトコル ローカル アドレス 外部アドレス 状態 PID TCP [::]:5432 [::]:0 LISTENING 6660 [postgres.exe] TCP [::]:5433 [::]:0 LISTENING 6628 [postgres.exe] UDP [::1]:65003 *:* 6660 [postgres.exe] UDP [::1]:65004 *:* 6628 [postgres.exe]
⇧ という感じで「タスク マネージャー」だと14個の「postgres.exe」の「プロセス」があったんですが、「netstat -naob」で表示された結果だと4個の「postgres.exe」の「プロセス」しか確認できないというね...
というか、Microsoftさんのドキュメントを見た感じだと、
適用対象: Windows Server 2022、Windows Server 2019、Windows Server 2016、Windows Server 2012 R2、Windows Server 2012
https://docs.microsoft.com/ja-jp/windows-server/administration/windows-commands/netstat
⇧ オプションの「b」って、Windows Serverのみでしか使っちゃいけないとかなんですかね?
そして、肝心の「postgres.exe」の「PID」と「Postgres Server」の「サービス」の「PID」との関係が分からん...

「タスク マネージャー」の「パフォーマンス」タブの中の「リソースモニターを開く」より、

「リソースモニター」の「ネットワーク」の「リッスン ポート」でも見当たらないですと...

stackoverflowによると、
The -b switch mentioned in most answers requires you to have administrative privileges on the machine. You don't really need elevated rights to get the process name!
Find the pid of the process running in the port number (e.g., 8080)
netstat -ano | findStr "8080"
Find the process name by pid
tasklist /fi "pid eq 2216"⇧ とあるので、「PID」から確認。

「pg_ctl.exe」って?
pg_ctlはPostgreSQLデータベースクラスタの初期化、PostgreSQLのデータベースサーバ(postgres)を起動、停止、再起動する、あるいは稼働中のサーバの状態を表示するためのユーティリティです。 サーバは手動で起動することも可能ですが、pg_ctlは、ログ出力のリダイレクトや、端末とプロセスグループの適切な分離などの作業を隠蔽してくれます。 さらにシャットダウン制御のための便利なオプションも提供します。
⇧ ということらしい。
なので、Windows環境でPostgreSQLが複数インストールされてる場合、どのバージョンのPostgreSQLがどのポート番号を使用しているかは、「PID」から判断できないので、各PostgreSQLの「pg_ctl.exe」を実行して調べるしか無さそう...
PostgreSQLがどこにインストールされてるかは、「サービス」で「プロパティ(R)」を確認すればOK。


で、PostgreSQLをインストールしてる場所にもよると思うけど、コマンドプロンプトを「管理者権限」で起動して、コマンド実行しないと「Postgres Server」が起動してても起動してません的なメッセージが表示されるという超不親切な結果が表示されるので、要注意です。
■「通常」モードで起動時のコマンドプロンプトでの実行結果

■「管理者権限」モードで起動時のコマンドプロンプトでの実行結果

⇧「通常」モードで起動時のコマンドプロンプトでの実行結果に騙されて、再起動しちゃったので、「PID」が変わってしまっているのだけども、問題はそんなところではなく、ポート番号が表示されとらんやん...。

⇧ ま~た、Windowsは除け者ですか...
何だろう、Windowsで仮に100台とかPostgreSQLをインストールしてた場合、「ポート番号」はExcelとかで管理しとかないと駄目ってことかね...
まぁ、今回は、たまたま、2台しかPostgreSQLインストールされてなかったから良いものの、実際の開発現場とかでWindows環境の場合どうしてるんでしょうね?
というわけで、自分の環境では、ポート番号「5432」「5433」が既に使用されてるので、「5434」で新しいPostgreSQLをインストールしていくことに。
現状の「winget」だと、「ポート番号」指定してのインストールとか無理そうなので、公式のインストーラーをダウンロードしてインストールしていくことにします。
「Download」を選択。

「Windows」を選択。

「Download the Installer」を選択。

今回は、せっかくなので、最新版を「Download」で。


インストーラーがダウンロードできたら、インストーラーを実行で。

デフォルトのままで「Next>」にしてます。

デフォルトのままで「Next>」にしてます。

デフォルトのままで「Next>」にしてます。

適当にパスワードを設定して「Next>」にしてます。パスワードはPostgreSQL に接続する際に必要なので、どっかにメモしておきましょう。

ポート番号は、PostgreSQLのインストーラーが空気を読んでくれるじゃないですが、「5432」が空いてない場合は、候補を上げてくれるみたいでした。「Next>」で。

デフォルトのままで「Next>」にしてます。

問題なければ「Next>」で。

問題なければ「Next>」で。

インストールが開始されるので、しばし待ちで。

「Finish」で。

「スタックビルダ」は無くても大丈夫みたいなので、「キャンセル(C)」を選択しました。


インストーラーからPostgreSQLをインストールした場合は、「Postgres Server」が起動した状態になってる模様。

一応、「Postgres Server」に接続もできるようになってました。

そして、
⇧ 上記サイト様を参考に、複数sqlファイルを一括で実行していきます。
ハマりどころは、
⇧ 上記サイト様が説明してくれていますが、Windows特有のパスの問題とかですかね。
で、作成されたsqlファイルを一括実行するためのsqlファイルを作って保存して、


PostgreSQL に接続して、実行します。


⇧「テーブル」が作成されました、「外部キー(FK:Foreign Key)」が設定できていないので、リレーションが全く張れてないですが...。
SchemaSpyを使ってみる
で、ようやっと本題。
「データベース」に作成されてる「テーブル」から「ER図」を作成してくれるツールで、「SchemaSpy」ってのが良さ気らしい。
Requirements
Before you can use SchemaSpy you must have the following requirements available on your local system.
https://github.com/schemaspy/schemaspy/blob/master/docs/source/installation.rst
⇧「SchemaSpy」を使うには、上記が必要になるらしい。詳細は、上記のページを参考ください。
で、「SchemaSpy」は結構バージョンによって動かないことが多いらしく、

⇧ 自分の環境では、「schemaspy@latest」ってリンク先でダウンロードするJARファイルを使わないとエラーが出てしまった。
というか、「Maven Repository」とかで公開されてる「SchemaSpy」はバージョンが更新されてないっぽいので、上記のGitHubから最新版を取得する感じになるのかな。
しかも、PostgreSQLを使う場合で、PostgreSQLのバージョンが11以上の場合は、「SchemaSpy」を実行する際のオプションの指定も注意が必要らしい。
用意するファイルは3つと、java.exeが使えればOK。自分は、java.exeについては、Eclipseに同梱されてるものを利用しています。

「schemaspy.properties」は以下のような感じに。
# type of database. Run with -dbhelp for details schemaspy.t=[データベースのタイプ] # optional path to alternative jdbc drivers. schemaspy.dp=[データベースに接続するためのドライバー] # database properties: host, port number, name user, password schemaspy.host=[ホスト、もしくはIPアドレス] schemaspy.port=[データベースのポート番号] schemaspy.db=[データベース] schemaspy.u=[データベースのユーザー] schemaspy.p=[データベースのパスワード] # output dir to save generated files schemaspy.o=[schemaspy実行結果の出力先] # db scheme for which generate diagrams schemaspy.s=[データベースのスキーマ]

そしたらば、schemaspyを実行で。
[java.exe] -jar schemaspy-6.1.1-SNAPSHOT.jar -vizjs

で、出力先として指定したフォルダに作成された「index.html」をダブルクリックすると、

ブラウザでローカルファイルが確認でき、

画面の下の方にスクロールすると、「テーブル」があるので、試しに、「page」テーブルをクリックしてみると、

詳細ページになるので、画面の下の方にスクロールすると、

「Relationships」があるのだけど、「外部キー(FK:Foreign Key)」が設定できてないので、単体でしか表示されないというね...

「Orphan Tables」タブのページで全体を俯瞰できる模様、ただし、「テーブル」に「外部キー(FK:Foreign Key)」を設定していないので、リレーションは張れていない。

⇧ なんか、PostgreSQL のデータ型についても勉強せねばですね...
「Relationships」については、当然ながら、何もないよ!って言われてますね、だって「テーブル」に「外部キー(FK:Foreign Key)」を設定できてないものね...。

ちょっと、時間の都合上、「外部キー(FK:Foreign Key)」を設定できてなかったので、「ER図(Entity-Relationship Diagram)」が残念な感じになってますが、時間ある時に、「外部キー(FK:Foreign Key)」を設定して試してみようかと。
Pyhtonやってる場合じゃなかったんだけどな...
今回はこのへんで。