
IEEE(米国電気電子学会)の「IEEE Spectrum」誌は2021年8月24日(米国時間)、プログラミング言語の年次ランキングの最新版「Top Programming Languages 2021」を公開した。
IEEEがプログラミング言語の各種ランキングを発表、上位に並んだのは?:インタラクティブなランキングを表示できる - @IT
このランキングは55種類のプログラミング言語を、8つのソースに基づく11の指標について評価し、スコア化して集計したものだ。インタラクティブなアプリケーションとして公開されている。
IEEEがプログラミング言語の各種ランキングを発表、上位に並んだのは?:インタラクティブなランキングを表示できる - @IT
⇧ 上記によると、「IEEE Spectrum(一般的なIEEE会員の興味や関心を反映した総合ランキング)」では、2021年度の上位5つのプログラミング言語は、
って結果になったらしい。
Javaと言えば、
Oracleは2021年9月14日(米国時間)、プログラミング言語と開発プラットフォームである「Java」の最新版「Java 17」と、Java開発キット「Oracle JDK 17」の一般提供を開始した。
⇧ なかなか衝撃的ですな...
頑張って「Oracle JDK」から「Open JDK」とかに切り替えていたような開発現場では怒号が飛び交ってもおかしくないですな...
今回は、データベースで出てくる「複合インデックス」なんかについて調べてみました。
レッツトライ~。
複合インデックスって何なの?
Wikipediaさんに聞いてみる。
A database composite index or multi-column index is an index that is based on several columns.
⇧いくつかのカラムで構成された「索引(インデックス)」ってことで、「索引(インデックス)」を調べてみると、
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
⇧ まぁ、超ザックリ要約すると、「索引(インデックス)」を作っておくと、データを検索するときに処理が早くなりますと。
「RDBMS(Relational Database Management System)」の仕様で「検索」っていうと、大きく分けて、
- 表探索
いわゆる全件検索 - 索引探索
「索引(インデックス)」を使って検索
に分類できるみたい、って「独立行政法人情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」の「データベーススペシャリスト」の試験問題で言ってました。

「アクセスパス」については、
⇧ 上記サイト様がまとめてくださってます。
で、「表検索」と「索引検索」の話に戻りますと、
例えば、1,000,000,000,000,000,000()行ぐらいのデータがあったとして、「表検索」とかしちゃうと、とんでもなく時間がかかる場合があるけど、上手いこと「索引(インデックス)」を作って「索引検索」ができれば、検索時間を短縮できることもあるある、って考え方みたいね。
いわゆる「性能」を良くしていくことに繋がる可能性があるので「非機能要件」に関わってくることですかね。
脱線しましたが、改めて「複合インデックス」の仕様って?
⇧ なんか、「MySQL」のマニュアルを参照してくれとな...
MySQL cannot use the index to perform lookups if the columns do not form a leftmost prefix of the index. Suppose that you have the SELECT statements shown here:
SELECT * FROM tbl_name WHERE col1=val1;
SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
SELECT * FROM tbl_name WHERE col2=val2;
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;If an index exists on (col1, col2, col3), only the first two queries use the index. The third and fourth queries do involve indexed columns, but do not use an index to perform lookups because (col2) and (col2, col3) are not leftmost prefixes of (col1, col2, col3).
https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
⇧ で、「MySQL」のドキュメントを参照してみたところ、「MySQL」における「複合インデックス」には上記のような制約があるそうな。
つまり、「複合インデックス」は、
- 部分的に使用できる、ただし
- 必ず一番初めのインデックスから使用する
- 飛び飛びでインデックス使うのは駄目
ってことになるんかな?
ただ、「MySQL」以外の「RDBMS(Relational Database Management System)」についても同様のことが言えるのかは分からんです...
ここで問題になるのは複合インデクスの特徴の1つである、「キーとして構成されているカラムの全てが検索条件に指定されていなくても、キーの先頭から途中までのカラムが指定されていれば、インデクスが使われる」という点です。
テーブルデータを全件読み込むよりも、インデスクを使用した方が速いのではないかと誤解する方も多いのですが、テーブルの全件検査はブロック読み込みという方式で何件もまとまった単位で連続して読み込みますので、検査だけであればそれほど時間はかかりません。※1
※1)1レコードのデータ長が極端に大きいテーブルの場合は、テーブルスキャンに時間がかかることもあります。
結論としては、複合インデクスといえども「会社」のようなデータの散らばりの少ないカラムはインデクスに含めず、テーブルデータを検査することで判定するようにした方がよいということです。
同じ理由で、「性別」や「所属部門」、「職位」など(コードで定義できるような数が少ないもの)も複合インデクスに含めるべきではありません。
⇧ 上記サイト様の説明にもありますように、「索引(インデックス)」を付けるべきカラムを見極めないと、逆に「性能」が落ちるなんてこともあり得るわけですね...
データベーススペシャリストの問題の解釈が難しい...
「データベーススペシャリスト」の「令和2年度」の「午後Ⅱ」の「問1」の問題で、解説を読んでてもいまいちピンとこなかったのですが、「複合インデックス」の仕組みを調べてみた後に、ようやっと何となくですが理解できました...。
ちなみに、利用してる参考書は、

⇧ なんですが、何か情報が端折られてることが多いので、なかなかに読み解くのがしんどい...

⇧ という解説部分があるのですが、参考書とかで一切「複合インデックス」の話が出てこないので、混乱するんだけど、「複合インデックス」の仕組みを把握していないと理解するのが厳しい問題だと思うんよね、たぶん...
問題としては、
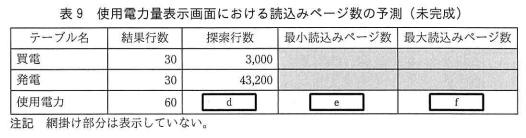
⇧ の値を求めるってことらしいんだけど、
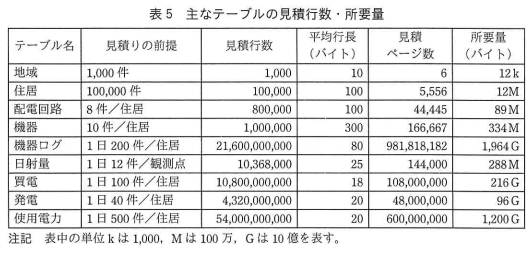
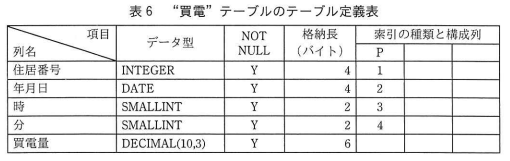

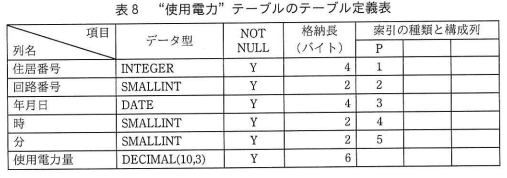
⇧ 上記のような情報が与えられていて、3つのテーブル定義書で、各々のテーブルに「複合インデックス」が作られていて、
| テーブル名 | index1 | index2 | index3 | index4 | index5 |
|---|---|---|---|---|---|
| 買電 | 住居番号 | 年月日 | 時 | 分 | |
| 発電 | 住居番号 | 回路番号 | 年月日 | 時 | 分 |
| 使用電力 | 住居番号 | 回路番号 | 年月日 | 時 | 分 |
⇧ ここで、「処理1」は、
- 指定された住居番号
- 年月日ごと
の「索引(インデックス)」でデータを検索しようとしていますと、つまり、「住居番号」と「年月日」の「複合インデックス」で検索したいんだと。
で、「複合インデックス」は、一番先頭の「索引(インデックス)」からであれば、部分的に利用できるんですと。(ただし、「索引(インデックス)」が順番に連続してる部分)
なので、「買電」「発電」「使用電力」の各々のテーブルで「処理1」を実施する場合、
- 買電テーブル
「住居番号」と「年月日」で「索引検索」 - 発電テーブル
「住居番号」で「索引検索」 - 使用電力テーブル
「住居番号」で「索引検索」
っていう検索のされ方になるということらしい。
「発電」テーブルと「使用電力」テーブルについては、「処理1」の検索だと「複合インデックス」を活かしきれてないってことになるのかね?
ただ、「買電」テーブルについても、4つのカラムで「複合インデックス」を構成しているので、「処理1」の検索だと、半分の「索引(インデックス)」しか活用できていないということになるんかな?
まぁ、何が言いたいかと言うと、一言、「複合インデックス」について言及してくれても良いんじゃないのかな、と思った情弱(情報弱者)な私です...
結局、「複合インデックス」について曖昧な情報しか調べられなかったけど...
今回はこのへんで。