
突然ですが、人の体の中で1番硬いのはどこの部位だと思いますか?
なんとなく骨が1番硬そうな気もしますが、実は歯の表面のエナメル質が1番硬いのです。硬さの指標であるモース硬度は7と言われており、これは水晶と同じぐらいの硬さになります。
≪モース硬度とは≫
硬さの指標となる単位で、10段階に分類されます。
モース硬度1:チョーク、滑石
モース硬度2:岩塩、石膏
モース硬度3:サンゴ
モース硬度4:鉄、パール、蛍石
モース硬度5:骨、ガラス
モース硬度6:正長石、オパール
モース硬度7:エナメル質、水晶、石英
モース硬度8:エメラルド
モース硬度9:ルビー、サファイア
モース硬度10:ダイヤモンド
⇧ という衝撃の結果を、最近知りました、どうもボクです。
謎に満ち満ちた人体ですが、
自らの拳足(主に手足)がいかに鍛えられたか、また自身の膂力を試すために様々な素材のものを突き技、蹴り技、打ち技、受け技などで割る事をいう。試割りで使用される素材は、板(杉板)、瓦、氷柱、バット、角材、ビール瓶、コンクリートブロック、自然石などがある。また、自らの身体全体で三尺か4尺棒を直接打ち込ませ、棒を折る演武もある。
⇧ 鍛錬の成果を確認する方法の1つとして「試割り」が行われることが多いですね、とにかく物体を割る、つまり「分割」するんだと。
そんなわけで、今回は、「n-gram」についてです。レッツトライ~。
n-gramって何ぞ?
事の発端は、
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,”I am an NLPer”という文から単語bi-gram,文字bi-gramを得よ.
⇧ 上記サイト様の問題の意味が全く意味が分からんってなったんですよ。唐突に「n-gram」を作る関数を作成せよ、って言われたんで、「What's?」ってなったんですよ。
「n-gram」って何なのよ、って思ってたら、
自然言語処理100本ノックをやるに当たって、N-gramの壁にぶち当たる人もいるかと思うので、簡単にまとめます。
⇧ 上記サイト様で説明してくれていました。
任意の文字列や文書を連続したn個の文字で分割するテキスト分割方法.特に,nが1の場合をユニグラム(uni-gram),2の場合をバイグラム(bi-gram),3の場合をトライグラム(tri-gram)と呼ぶ.
⇧ 要するに「テキスト分割方法」のことらしい。
Wikipediaさんによりますと、
In the fields of computational linguistics and probability, an n-gram is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. The n-grams typically are collected from a text or speech corpus. When the items are words, n-grams may also be called shingles[clarification needed].
Using Latin numerical prefixes, an n-gram of size 1 is referred to as a "unigram"; size 2 is a "bigram" (or, less commonly, a "digram"); size 3 is a "trigram". English cardinal numbers are sometimes used, e.g., "four-gram", "five-gram", and so on. In computational biology, a polymer or oligomer of a known size is called a k-mer instead of an n-gram, with specific names using Greek numerical prefixes such as "monomer", "dimer", "trimer", "tetramer", "pentamer", etc., or English cardinal numbers, "one-mer", "two-mer", "three-mer", etc.
⇧ってな感じで、テキストを分割する方法って認識で良さ気ですかね。
「文字の単位」で「3-gram」で分割する例が以下で、
For sequences of characters, the 3-grams (sometimes referred to as "trigrams") that can be generated from "good morning" are "goo", "ood", "od ", "d m", " mo", "mor" and so forth, counting the space character as a gram (sometimes the beginning and end of a text are modeled explicitly, adding "_ _g", "_go", "ng_", and "g_ _").
「単語の単位」で「3-gram」で分割する例が以下ですかね。
sFor sequences of words, the trigrams (shingles) that can be generated from "the dog smelled like a skunk" are "# the dog", "the dog smelled", "dog smelled like", "smelled like a", "like a skunk" and "a skunk #".
テキストを分割する単位としては、「音素」「音節」「文字」「単語」「塩基対」があるみたいですね。
実際に分割してみる
⇧ 上記サイト様を参考にさせていただきました。
で、実際に分割してみた。Javaで実施してみたら、むちゃくちゃ面倒くさい感じになりました...
やっぱり、「自然言語処理」とかは、Pythonが向いてるんですかね?
まぁ、単純に、Javaでの上手い書きっぷりが思いつかなかっただけなんだが...
package one_hundred_nock.first.five;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Ngram {
public static void main(String[] args) {
String targetStr = "I am an NLPer"; // 文字単位での分割用
String[] targetStrArr = targetStr.split(" "); // 単語単位での分割用
// 文字の単位で分割した結果(1~3まで)
System.out.println(nGram(targetStr, 1));
System.out.println(nGram(targetStr, 2));
System.out.println(nGram(targetStr, 3));
// 単語の単位で分割した結果(1~3まで)
StringBuilder sb = new StringBuilder();
nGram(targetStrArr, 1).forEach((key, value) ->{
sb.append(key).append("=").append(value);
});
System.out.println(sb.toString());
sb.setLength(0);
nGram(targetStrArr, 2).forEach((key, value) ->{
sb.append(key).append("=").append(value);
});
System.out.println(sb.toString());
sb.setLength(0);
nGram(targetStrArr, 3).forEach((key, value) ->{
sb.append(key).append("=").append(value);
});
System.out.println(sb.toString());
}
// 単語の単位での分割
public static Map<Integer, List<String>> nGram(String[] strArr, int nGram) {
List<String> elementList = Arrays.asList(strArr);
Map<Integer, List<String>> map = new HashMap<>();
for (int index = 0; index < elementList.size(); index++) {
if (index+nGram <= elementList.size()) {
map.put(index, elementList.subList(index, index+nGram));
}
}
return map;
}
// 文字の単位での分割
public static Map<Integer, String> nGram(String str, int nGram) {
Map<Integer, String> map = new HashMap<>();
for (int index = 0; index < str.length(); index++) {
if (index+nGram <= str.length()) {
map.put(index, str.substring(index, index+nGram));
}
}
return map;
}
}
で、実施してみた。
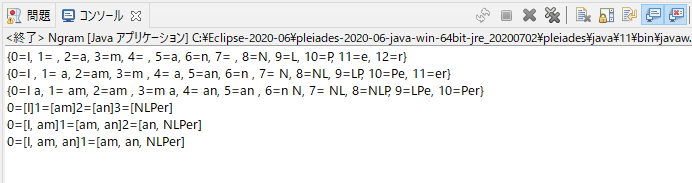
一応、結果は、参考サイト様と同じ様に値を「n-gram」で分割できてはいるようです。
参考サイト様に比べて、コーディング量がむちゃくちゃ多くなってるんで、もっとスマートな書き方ができれば良いんですけどね...
またしても、モヤモヤ感が半端ないところではありますが...
今回はこのへんで。