
ディーン氏とゲマワット氏はDEC所属の頃から深い仲で、横に並んで共同でコードを書くことを好んだそうです。2人は停止したインデックスを詳しく調べ、いくつかの単語が抜けていること、順序が間違っていることなど、コードの欠陥を何日もかけて発見しましたが、明確なバグは見つけられませんでした。取り組み開始から5日目、2人は「問題はソフトウェアではなく、物理的なものではないか」と疑い始めます。そして、ごちゃごちゃと煩雑なインデックスファイルを2進数で表したバイナリコードに単純化することで、マシンが何を見ているのか知る試みをしました。
バイナリコードでは、モニターに1と0の列が表示されます。それぞれの列はインデックス内のデータを表していますが、あるときゲマワット氏は、「0であるべき数字が1になっている」と指摘。そこでディーン氏とゲマワット氏が誤表示される単語をすべてまとめると、一定のパターンが現れました。結果として、マシンのメモリチップが何らかの理由で破損していたことが判明しています。
Googleの設立は1998年で、トラブルが発生した1999年から2000年ごろは、まだスタートアップのように運営されていたとThe New Yorkerは指摘。実際に、マザーボードやハードドライブ、配線などさまざまな面で故障や不具合が発生しており、NASAや金融機関などは1ビットの「0」と「1」がハードウェアトラブルで反転しても全体に影響が生まれない特別なハードウェアを使用していましたが、Googleでは安価なコンピューターを使用しており、ハードウェア障害を回避することができませんでした。結果として、ディーン氏とゲマワット氏が問題のあるマシンを補うコードを書いたことで、新しいインデックスが完成し、対策会議は解散しました。
⇧ よく原因を特定できましたな。短期間でソフトウェア側ではなく、ハードウェア側の問題ではないかと推測できるのも驚きなんだが、対応力が高過ぎですな。
当時のGoogleは、マザーボードとハードドライブを組み合わせたデバイスを1500台積み上げていましたが、ハードウェアの不具合のため、機能したのはそのうち1200台程度でした。ハードウェアの不具合を原因とする障害はシステムを破壊し続けていたため、Googleはコンピューターを回復力のある全体に統合する必要がありました。
トラブルの再発を防ぐため、ディーン氏とゲマワット氏は1台のハードドライブが故障してもシステム全体がダウンしないようにコードを書きました。2005年にエンジニアリングチームの責任者に就任した計算機科学者のアラン・ユースタス氏は「逆説的ですが、大規模な問題を解決するには、細部まで知っておく必要があります。ディーン氏とゲマワット氏は、コンピューターをビットレベルで理解していました」と2人の能力を称賛しています。
⇧ まぁ、機械の処理は、
- 正常に実行された
- 正常に実行されなかった
のどちらかに大別されるのであって(勿論、各々について様々な処理のパターンはありますが)、
『概ね正しい内容なので、正常に実行される、ということにしておきますね』
のような忖度をしてくれるわけでは無いですし、何か1つでもミスがあれば破綻するのだから、細部まで把握していないと「正常に実行された」のかは知りようが無いとは思いますと。
とは言え、大規模な問題の全てを把握することは、現実的に難しい気がしますけど...
Rubyで「依存性注入(DI:Dependency Injection)」はどうする?
JavaのSpring Frameworkとかの「依存性注入(DI:Dependency Injection)」とかを利用していたので、Rubyでは「依存性注入(DI:Dependency Injection)」をどう実装するのか?と思って、ネットの情報を漁っていたのだけど、
⇧ 上記サイト様によりますと、Rubyでは「依存性注入(DI:Dependency Injection)」を導入することに対して乗り気ではないらしいように見えますと。
ただ、
⇧ Rubyでも「依存性注入(DI:Dependency Injection)」は実現できるらしい。
RubyでDRYの原則どうしてる?
で、仮に「依存性注入(DI:Dependency Injection)」を導入しないとなった場合に、「DRY(Don't Repeat Yourself)の原則」に対して、どう対処しているのか?
「DRY(Don't Repeat Yourself)の原則」はと言うと、
Don't repeat yourself(DRY)は、特にコンピューティングの領域で、重複を防ぐ考え方である。この哲学は、情報の重複は変更の困難さを増大し透明性を減少させ、不一致を生じる可能性につながるため、重複するべきでないことを強調する。
DRY は、Andy Hunt と Dave Thomas の著書 The Pragmatic Programmer (邦題:達人プログラマー) において中心となる原則である。 彼らはこの原則を、データベーススキーマ、テスト計画、ビルドシステムや、ドキュメンテーションにいたるまで非常に幅広く適用している。
DRY 原則がうまく適用されたとき、システムに対するいかなる要素の変更も、論理的に関連のない他の要素の変更にはつながらない。さらに、論理的に関連した要素は予測できる形で統一的に変更され、したがってそれらの変更は同期が取れたものとなる。
⇧ とあり、元々は同じ様な処理を至る所にコーディングしてしまうと、修正が必要になった場合に、正常に修正しきれないリスクがあるということで、重複を無くして再利用できる形にしましょう、ってことですかね。
「二重管理」とかになってしまうのも、「DRY(Don't Repeat Yourself)の原則」に違反してるってことになるんかね。
要は、可能な限り重複を無くして「変更容易性」が高くなるようにしましょう、ってことでしょうかね。
で、「依存性注入(DI:Dependency Injection)」を導入しないとなった場合、別のクラスの処理を実施したい場合、どう実現するのか?
例えば、「oxidized」というRuby製のツールがあるのですが、
⇧ 公式のドキュメントによると、
- Creating a new model
- Extending an existing model with a new command
とあって、「新規にモデル」「既存のモデルを改修」の2パターンで機能をカスタマイズできるとあるのですが、「oxidized」の文脈で言う「モデル」は必ず、
class モデル < Oxidized::Model using Refinements end
⇧ という形を取る必要がありますと。
で、普通に考えて、「2. Extending an existing model with a new command」、所謂「既存のモデルを改修」については、「デグレード(Degrade)」乃至は「リグレッション(Regression)」が起こるリスクがあるので、避けるのが一般的なのではないかと。
そうなると、必然的に、「1. Creating a new model」を選択せざるを得ないとなるのですが、そうなった場合に、例えば、既存のモデルの処理を利用したい場合、「依存性注入(DI:Dependency Injection)」するのが一般的なのかなと。
JavaのSpring Frameworkとかだと、@Autowiredアノテーションで別のクラスを利用することあるあるですと。
で、Rubyは、そのあたり、どうしているのか?
ネットの情報を見た感じでは、
⇧ 上記サイト様によりますと、
- コンストラクタ内で他クラスをインスタンス化してメソッド呼び出し
- 依存性注入(DI: Dependency Injection)後にメソッド呼び出し
- クラスメソッドとしてメソッド呼び出し
のいずれかを利用するしかない感じなんかな?
とは言え、「3. クラスメソッドとしてメソッド呼び出し」については、ライブラリ側でのクラスの実装に依存してしまうと思われるので、
- コンストラクタ内で他クラスをインスタンス化してメソッド呼び出し
- 依存性注入(DI: Dependency Injection)後にメソッド呼び出し
のどちらかを利用せざるを得なさそうなんだが、クラス内でインスタンスを利用できる形での「依存性注入(DI: Dependency Injection)」を実現するには、
⇧ 外部ライブラリを利用せざるを得ないらしいですと。所謂「依存性注入コンテナ(DIC:Dependency Injection Container)」にクラスのインスタンスを登録しておいて、利用したクラスで読み込めるようにしていると。
Rubyにおける「依存性注入コンテナ(DIC:Dependency Injection Container)」の話では無さそうなんだけど、
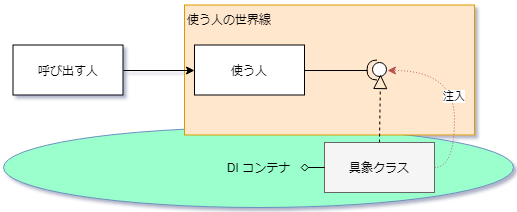
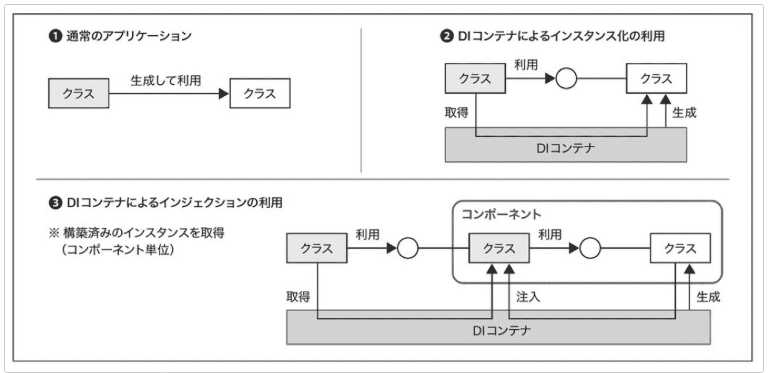
⇧ 上記サイト様の図がイメージし易いかと。
どのタイミングで登録しておいたクラスのインスタンス化が行われるかは分かりませんが、「依存性注入コンテナ(DIC:Dependency Injection Container)」を経由させて「依存性注入(DI:Dependency Injection)」が為されると。
つまり、クラス内で別クラスのインスタンスを利用できるようになると。
ただ、外部ライブラリを利用していない既存のRubyプロジェクトにおいて、外部ライブラリの追加とかの影響が分からないことを考えると、「1. コンストラクタ内で他クラスをインスタンス化してメソッド呼び出し」を採用せざるを得ないのかなぁ...
Rubyの知見が全くないからして、どうすべきなのかがサッパリ分からん...
とりあえず、再利用できる処理があるにも拘らず再利用することをせずに、何度も同じ処理内容を複製する形は避けたいのよね...
毎度モヤモヤ感が半端ない…
今回はこのへんで。