
ソフトウェアにおいて、システムの安全性が保てなくなるような設計ミスなどのことを脆弱性と言います。ソフトウェア開発にはバグがつきもので、毎月のように多数の脆弱性が発見されているため、全ての脆弱性に対応するのは難しいもの。そうした状況において、脆弱性対応の優先順位付けする方法として考案されたのが「EPSSモデル」です。
「どの脆弱性を優先して対応するべきか」をスコア化してくれる「EPSSモデル」とはいったいどんな仕組みなのか - GIGAZINE
⇧ こういう膨大な作業が要求される対応こそ、AIで良しなに自動化対応してくれるようにして欲しい気はする...
Linuxでawkを使って既存CSVファイルの重複行を除外して新規CSVファイルを作成する
前回、
⇧ Linux環境で既存のCSVファイルから行や列を指定して抽出した内容で新規CSVファイルを作成するってことを試してみました。
で、考えてみると、
のようなデータのCSVファイルの場合、特定の列については値が重複することもありますと。
みたいなデータとかですかね。
イメージとしては、
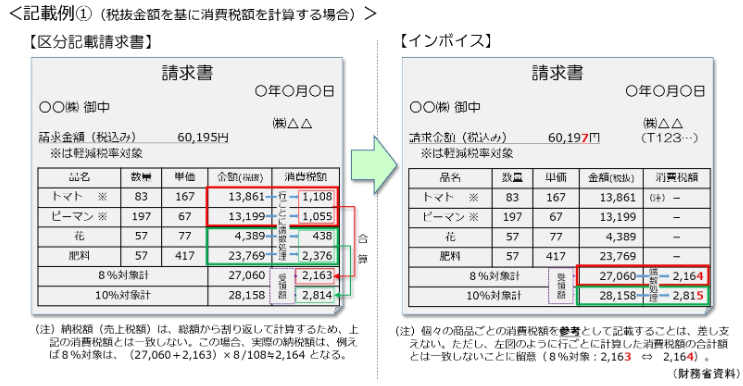
⇧ みたいな請求書があったとして、

⇧ 黄色く囲んだ部分を「請求明細」とすると、1つの「請求」に対して「請求明細」は複数行ありますと。
で、複数の「取引先」の「請求」があった場合に、「取引先」の数がどれくらいあるかを「請求」のデータから算出したいとなった場合に、「重複」を除外する必要が出てきますと。
例えば、
取引先ID,取引先名,請求日,請求金額(税込み),品名,数量,単価,金額(税抜),消費税額 1,大泉農園, 2023-09-17,60195,トマト,83, 167, 13861, 1108 1,大泉農園, 2023-09-17,60195,ピーマン,197, 67, 13199, 1055 1,大泉農園, 2023-09-17,60195,花,57, 77, 4389, 438 1,大泉農園, 2023-09-17,60195,肥料,57, 417, 23769, 2376 2,新座農園, 2023-09-17,30565,キャベツ,53, 207, 12068, 1097 2,新座農園, 2023-09-17,30565,ねぎ,300, 53, 15900, 1500 3,練馬農園, 2023-09-17,7480,大根,68, 100, 6800, 680 4,保谷農園, 2023-09-17,7963,人参,127, 57, 7239, 724
⇧ のようなCSVファイルで、取引先の数は、
- 大泉農園
- 新座農園
- 練馬農園
- 保谷農園
のように、4社になるので、重複行を除外したいみたいなケースですね。
⇧ 上記サイト様を参考に、既存CSVファイルの重複行を除外した結果の内容で新規CSVファイルの作成を試してみます。
前回の記事と同様の環境(「WSL 2(Windows Subsystem for Linux 2)」のUbuntu)で動作確認してみます。
「WSL 2(Windows Subsystem for Linux 2)」のUbuntuを起動。
WinSCPなどで、重複行のあるCSVファイルを配置します。
新しく、別にコマンドプロンプトを起動し、UbuntuへSSHログイン。
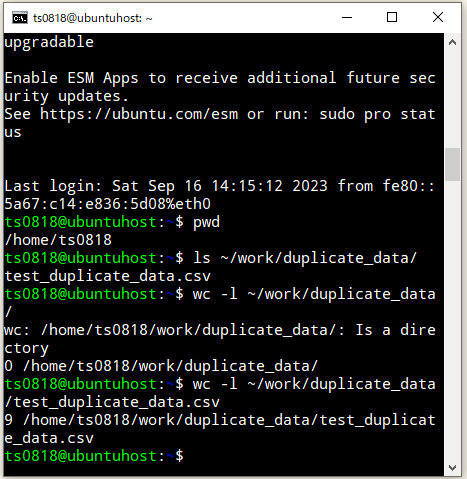
では、CSVファイルの1列目に対しての重複行を除外した結果の内容で、新規CSVファイルを作成。
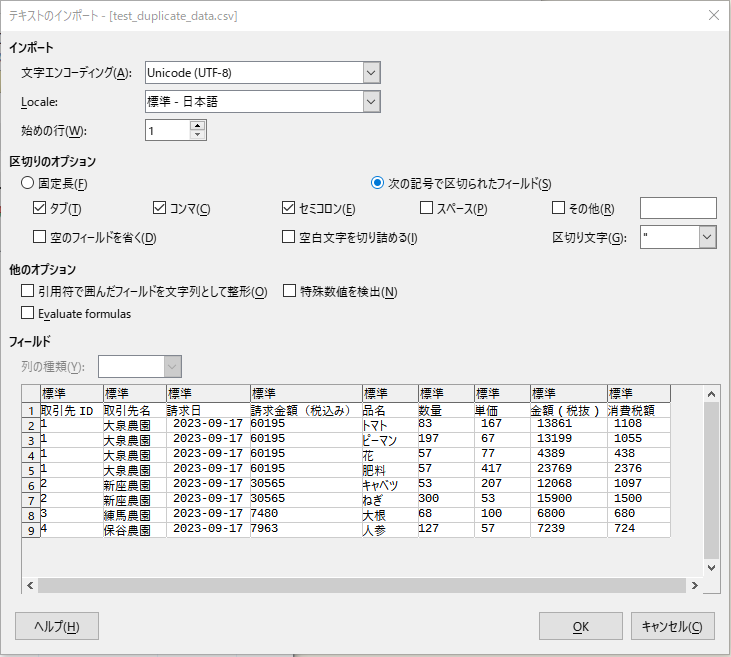
cat ~/work/duplicate_data/test_duplicate_data.csv | awk -F, '!a[$1]++' > ~/work/duplicate_data/test_uniq.csv
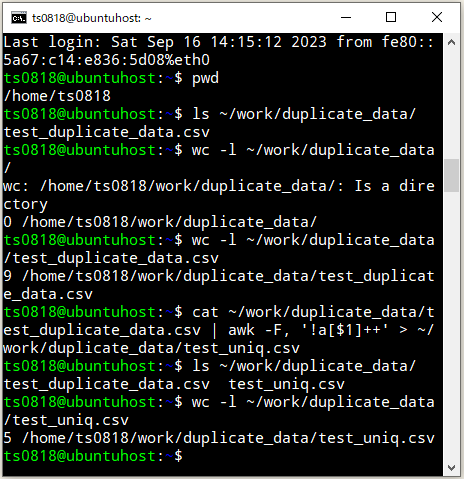
既存CSVファイルの1行目のヘッダ行を除外した内容で新規CSVファイルを作成するケースも試してみます。
awk 'NR>=2' ~/work/duplicate_data/test_duplicate_data.csv | awk -F, '!a[$1]++' > ~/work/duplicate_data/test_headerless_uniq.csv
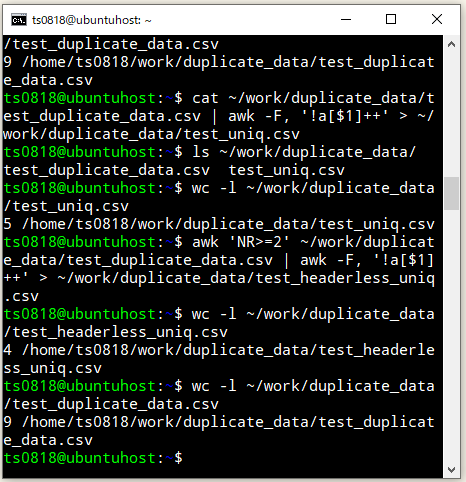
重複行を除外した内容で新規CSVファイルの作成ができているようです。
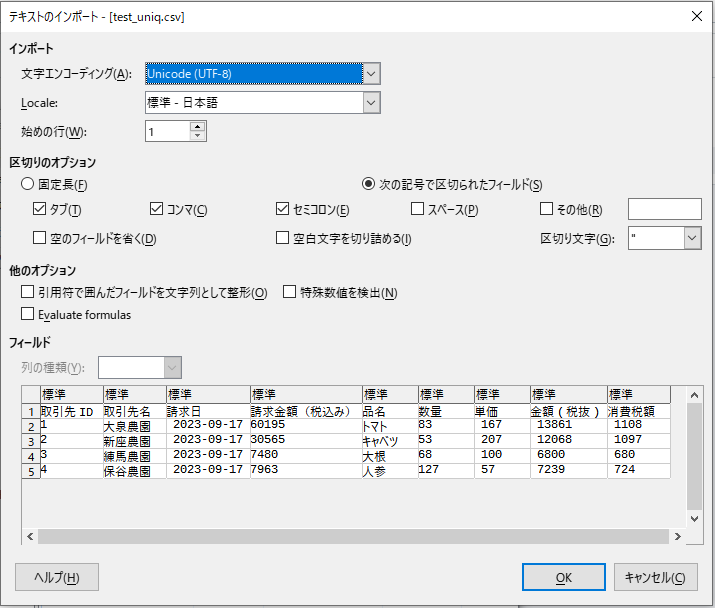
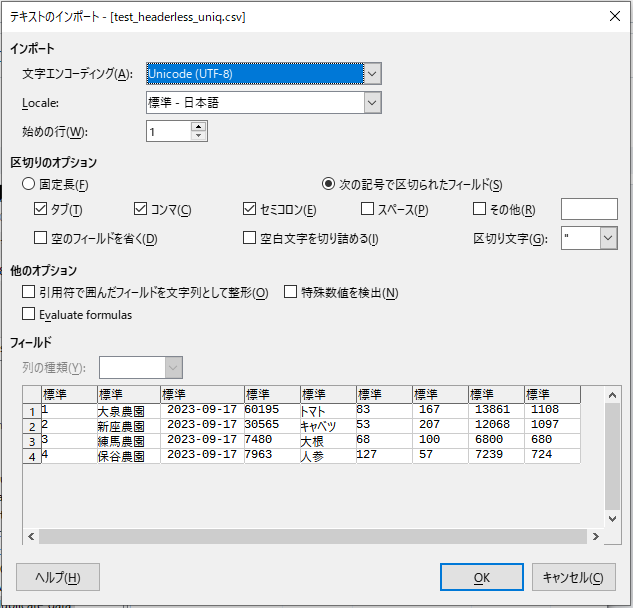
既存のCSVファイルは元の状態から変わっていないことを確認。
既存のCSVファイルの重複行を除外し、且つ、2列目のみ抽出した内容で、新規CSVファイルを作成するのも実施してみる。
awk -F, 'NR>=2 && !a[$1]++ {print $2}' ~/work/duplicate_data/test_duplicate_data.csv > ~/work/duplicate_data/test_col.csv
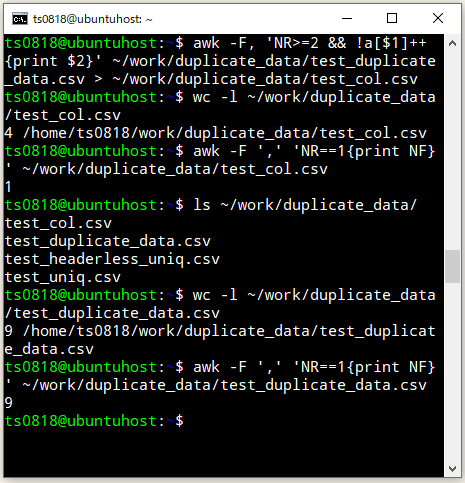
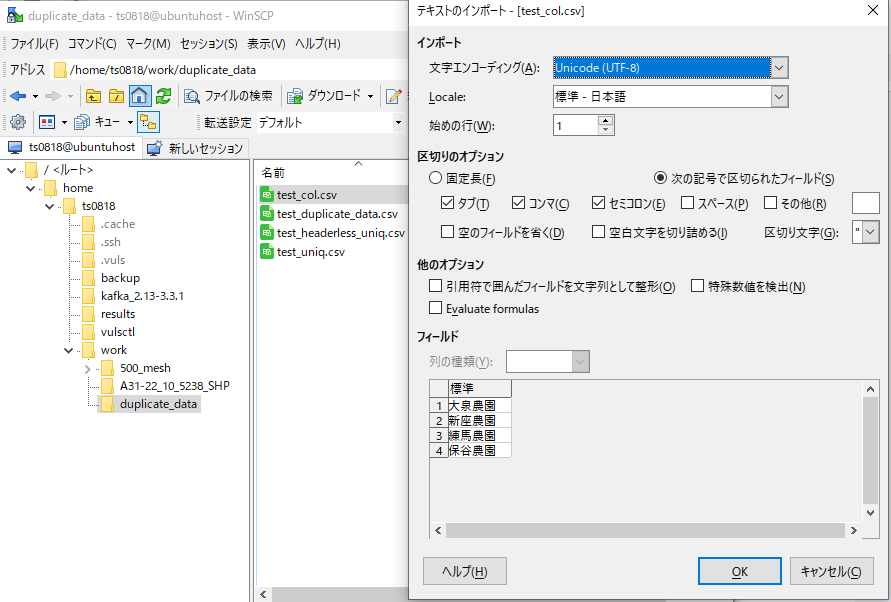
⇧ 実現できたようです。
コマンド便利かもしれんけど、実現したいことに対して、どういうコマンドの書き方をすれば良いかが分からんと調べるのが辛いですな...
毎度モヤモヤ感が半端ない...
今回はこのへんで。