
パラレルワールド(parallel world)とは、ある世界(時空)から分岐し、それに並行して存在する別の世界(時空)を指す。並行世界、並行宇宙、並行時空とも言われている。 そして、「異世界(異界)」、「魔界」、「四次元世界」などとは違い、パラレルワールドは我々の宇宙と同一の次元を持つ。SFの世界の中だけに存在するのではなく、理論物理学の世界でもその存在の可能性について語られている。
理論的根拠を超弦理論の複数あるヴァージョンの一つ一つに求める考え方も生まれてきている。
⇧ いやはや、どうなる、パラレルワールド!
ちなみに、「超弦理論」は、
超弦理論には5つのバージョンがあり、それぞれタイプI、IIA、IIB、ヘテロSO(32)、ヘテロE8×E8と呼ばれる。この5つの超弦理論は理論の整合性のため10次元時空が必要である。空間の3次元に時間を加えた4次元が、我々の認識する次元数である。我々が認識できない残りの6次元は、カラビ・ヤウ多様体により量子レベルでコンパクト化され、小さなエネルギーでは観測できないとされる。
⇧ なんか、我々の存在する世界というのは、
- 認識できる4次元
- 認識できない6次元
- M理論では、プラス1次元
の11次元で成り立っているのだよ、という理論があるんだね...
まぁ、脱線しましたが、「深層強化学習(Deep Reinforcement Learning)」 について調べてみました。
レッツトライ~。
機械学習(Machine Learning)について、今一度整理してみる
いつもながら、Wikipediaさんに聞いてみる。
機械学習という名前は1959年にアーサー・サミュエルによって造語された。
⇧ と説明されていて、
機械学習タスクの種類
機械学習のタスクは、以下の代表的な3種類のカテゴリーに分けられる。ただしこれらの3つで機械学習で扱う全てのタスクをカバーしているわけではないし、複数のカテゴリーに属するタスクや、どのカテゴリーに属するのか曖昧なタスクもある。
入力とそれに対応すべき出力を写像する関数を生成する。例えば、分類問題では入力ベクトルと出力に対応する分類で示される例を与えられ、それらを写像する関数を近似的に求める。
入力のみ(ラベルなしの例)からモデルを構築する。データマイニングも参照。
周囲の環境を観測することでどう行動すべきかを学習する。行動によって必ず環境に影響を及ぼし、環境から報酬という形でフィードバックを得ることで学習アルゴリズムのガイドとする。例えばQ学習がある。
⇧ はい、出ました、カテゴリーの全量が曖昧ですって...
MECE(Mutually Exclusive, Collectively Exhaustive)ができてないんじゃないの~
まぁ、でも、総務省が公開している資料によると、

⇧ 機械学習の分類としては、
- 教師あり学習(Supervised Learning)
- 教師なし学習(Unsupervised Learning)
- 強化学習(Reinforcement Learning)
の3つが全量っぽい書きっぷりなんですよね、まさに『異論は認めない』的な潔さを感じますね。
国が嘘を付くなどということはあってはならないことなので、「機械学習」は大きく分けて、「教師あり学習」「教師なし学習」「強化学習」の3つに分類できるって前提で話を進めていくことにしますか。
で、総務省さん曰く、
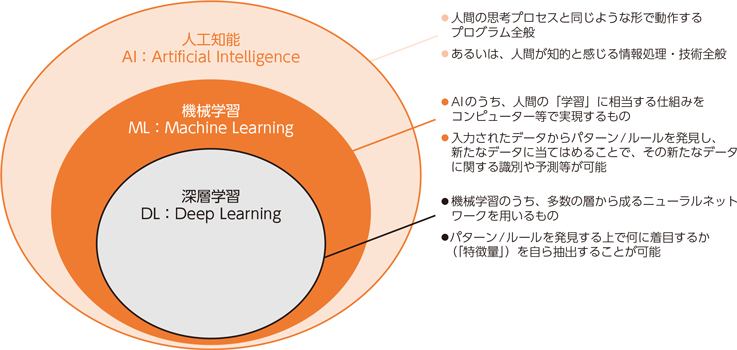
⇧ 「深層学習(Deep Learning)」っていうのは、「機械学習(Machine Learning)」の中の1手法ってことで、さらに、

⇧ どうやら、「深層学習(Deep Learning)」は、
- 教師あり学習(Supervised Learning)
- 教師なし学習(Unsupervised Learning)
- 強化学習(Reinforcement Learning)
の全てで活用されているようです。
つまり、 2021年7月17日(土)現在、

⇧ 上記サイト様のようなカテゴリー分けになっているんだということですかね。
強化学習(Reinforcement Learning)とは?
今回は、「深層強化学習(Deep Reinforcement Learning)」についての調査なので、まずは、「強化学習(Reinforcement Learning)」についてを調べてみますか。
Wikipediaさんによりますと、
強化学習(きょうかがくしゅう、英: reinforcement learning)とは、ある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する問題を扱う機械学習の一種。エージェントは行動を選択することで環境から報酬を得る。強化学習は一連の行動を通じて報酬が最も多く得られるような方策(policy)を学習する。環境はマルコフ決定過程として定式化される。代表的な手法としてTD学習やQ学習が知られている。
⇧ とあるんだけど、どうも日本語版のWikipediaと英語版のWikipediaで情報量が違い過ぎるというね...
英語版のWikipediaによると、
Reinforcement learning differs from supervised learning in not needing labelled input/output pairs be presented, and in not needing sub-optimal actions to be explicitly corrected. Instead the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
⇧ という記載が見られますと。
翻訳してみたところ、
- ラベル付きの入力/出力ペアを提示する必要がない
- 次善のアクションを明示的に修正する必要がない
ってな点についてが、「教師あり学習(Supervised Learning)」との違いらしく、その代わりに「強化学習(Reinforcement Learning)」では、
- (未知の領域の)探査
- (現在の知識の)活用
って2つをバランス良く選択していくってことをしないといけないらしい。
例えるならば、ごく平凡なサラリーマンが、
- 「ある日突然クロコダイル・ダンディー的なワイルドなファッションをする」
- (未知の領域の)探査
- 「いつもの無難なこれぞ日本のサラリーマン的なファッションをする」
- (現在の知識の)活用
ってな感じで、「攻める勇気」にあたるのが「(未知の領域の)探査」 で、「守る勇気」にあたるのが「(現在の知識の)活用」ってことで、
- (未知の領域の)探査
- (現在の知識の)活用
の2つはお互いがトレードオフの関係にあるらしい。
どちらを選択するにしろ、「強化学習(Reinforcement Learning)」が目指していることは、良い「報酬」を獲得するってことなんだと。
まぁ、何が言いたいかというと、『「強化学習」を知れば「恋愛成就」は不可避!全人類がLove&Peaceに包まれる優しい世界が待ってるじゃん!』ってことですかね。
はい、脱線しました。
なんか、
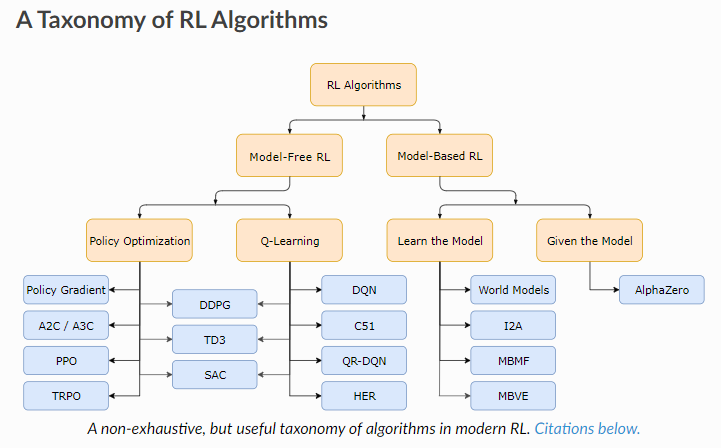
⇧「OpenAI」を知るための学習サイトっぽいとこの説明によると、「深層学習(Reinforcement Learning)」のアルゴリズムについては、大まかに、
- Model-Base RL
- Model-Free RL
にカテゴリ分けされるってことらしく、さらに、そこからカテゴリ分けがされていくようなのですが、
⇧ 上記サイト様によりますと、「モデルフリー」については、
- オンポリシー
- オフポリシー
に分けられると言ってますと。
「Machine Learning Applications for Sensor Taskingwith Non-Linear Filtering」っていう海外の論文とかの説明を見ると、
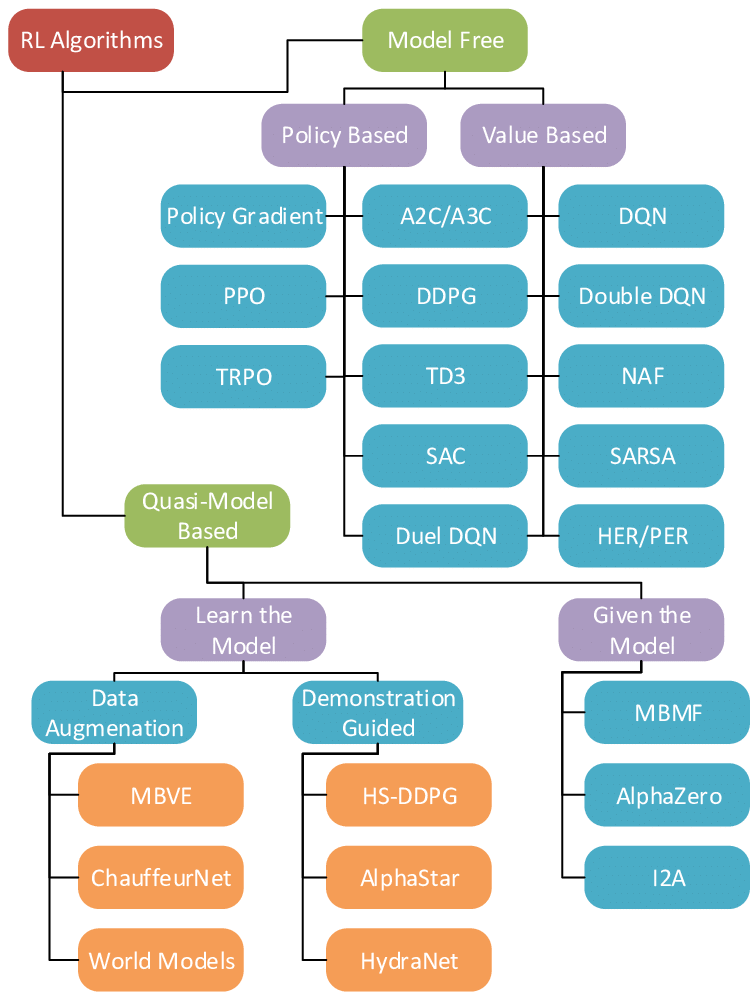
⇧ 若干、見解が異なるのか「モデルフリー」については、
- Policy Based
- Value Based
に分けられると言ってますと。
アルゴリズムが増えていくと、また変わってくるんだと思うけど、2021年7月16日(金)現在は、大まかに「モデルベース」「モデルフリー」の2タイプにカテゴリ分けされるって認識で良いんかな?
何て言うか、このあたり、統一したツリー図を管理するようにして欲しいよね...
だが、しかし!
いま絶賛学習中の

最短突破 ディープラーニングG検定(ジェネラリスト) 問題集
⇧ 上記の本によると、
『強化学習の手法は、大きく分けるとモデルフリー、モデルベースの2種類に分けられます。さらにそれぞれが価値ベース、方策ベースの手法に分かれます。』
って書いてるんよね...
最早、どの情報を信じて良いのか分からん...
で、本当は駄目なんだが、技術評論社に問い合わせさせていただいたところ、著者の株式会社AVILENから回答いただけました、本当に感謝しかない。
こちらですが、モデルベースの手法にも価値ベースや方策ベースといった分類が可能です。
価値反復法などはモデルベースで価値ベースの手法であり、モデルベースで方策ベースの手法も存在いたします。
よって、それぞれに価値ベース、方策ベースが存在するという記述には誤りはございません。
強化学習の手法の分類は研究者によっても意見が多少食い違うところもあり、非常に難しいところですので、もし詳しく知りたければ、
「強化学習 (機械学習プロフェッショナルシリーズ) 」森村哲郎著、講談社
などの本がおススメです。
試験勉強応援しております。
株式会社AVILEN様からの回答
⇧ 親切過ぎませんか~、感動しかない。
ちなみに、株式会社AVILENさんは、
⇧「G検定」「E資格」 などのデータサイエンティスト系の資格取得のための講座も実施していて、難関と言われる「E資格」の合格率94%らしいっす、恐るべし...
「G検定」の講座については、受講して合格できなかったら、全額返金保証らしいという大盤振る舞い!
脱線しましたが、「強化学習」の大まかな分類は、
- モデルフリー
- 価値ベース
- 方策ベース
- モデルベース
- 価値ベース
- 方策ベース
ってな感じになるんですかね?
このあたりは、

⇧ を読んで、整理できたら追記していこうかと。
ちなみに、「深層強化学習(Deep Reinforcement Learning)」の英語版のWikipediaの説明によると、
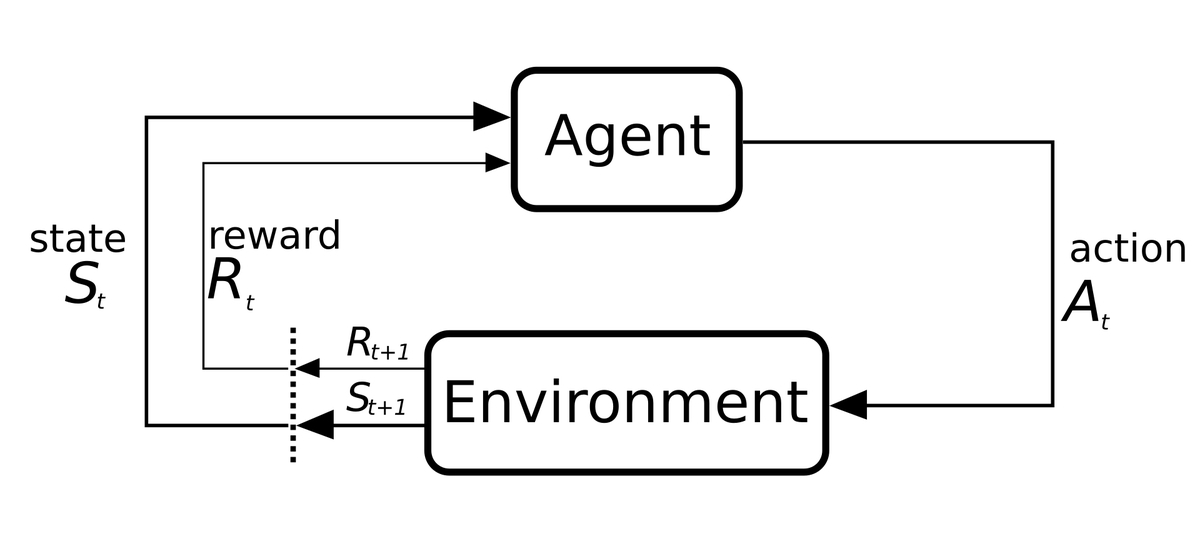
Diagram of the loop recurring in reinforcement learning algorithms
⇧ 上図が一般的な「強化学習(Reinforcement Learning)」の挙動ってことになるらしい。用語的には、
- Agent:エージェント
- StateとRewardを受け取って、Actionを決定する
- ポリシー(方策)を考慮する感じなんかな?
- Action:行動
- 以下のどっちかの振る舞いをEnvironmentに対して実施する
- exploration (of uncharted territory):(未知の領域の)探査
- exploitation (of current knowledge):(現在の知識の)活用
- 以下のどっちかの振る舞いをEnvironmentに対して実施する
- Environment:環境
- Actionの結果、新たなStateとRewardをAgentに送る
- State:状態
- Environmentが更新し、Agentに連携される
- Reward:報酬
- Environmentが更新し、Agentに連携される
ってことなんかな。
「強化学習(Reinforcement Learning)」の最終的な目的はと言うと、
A basic reinforcement learning agent AI interacts with its environment in discrete time steps. At each time t, the agent receives the current state and reward . It then chooses an action from the set of available actions, which is subsequently sent to the environment. The environment moves to a new state and the reward associated with the transition is determined.






The goal of a reinforcement learning agent is to learn a policy: , which maximizes the expected cumulative reward.
![{\displaystyle \pi :A\times S\rightarrow [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53cdefaaea162af26e217b740b90f8f8c692a641)

⇧「累積報酬」が最大となるようにするってことで、Agentは「累積報酬」が最大となるような「ポリシー(方策)」を学習するってことなんかな?
「オンポリシー」と「オフポリシー」の振る舞いなんかは、
■on-policy
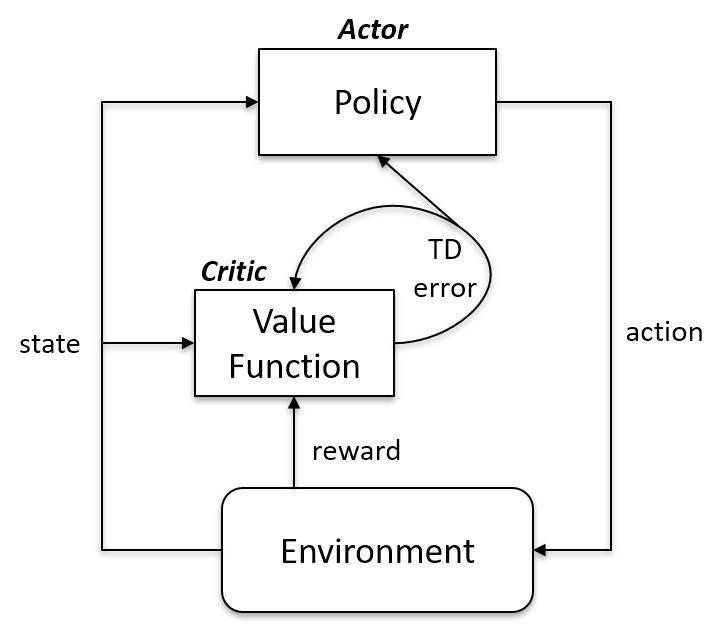
■off-policy
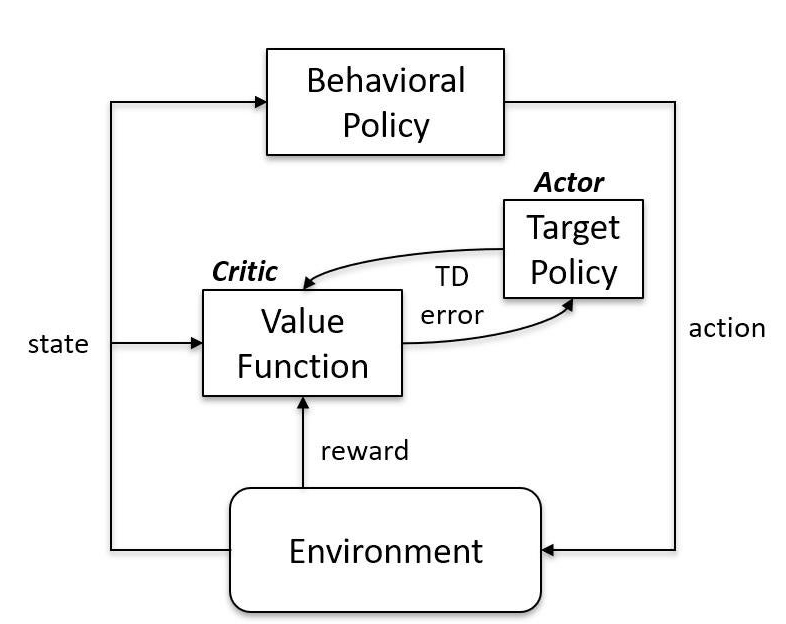
⇧ って感じになるっぽい。「Agent」の中身の構造が変わってくる感じなんかな。
違いは、 「ポリシー」を直に更新するかどうかってことなんすかね?
深層強化学習(Deep Reinforcement Learning)って?
Wikipediaさんによりますと、
Deep reinforcement learning (deep RL) is a subfield of machine learning that combines reinforcement learning (RL) and deep learning.
RL considers the problem of a computational agent learning to make decisions by trial and error. Deep RL incorporates deep learning into the solution, allowing agents to make decisions from unstructured input data without manual engineering of the state space. Deep RL algorithms are able to take in very large inputs (e.g. every pixel rendered to the screen in a video game) and decide what actions to perform to optimize an objective (eg. maximizing the game score). Deep reinforcement learning has been used for a diverse set of applications including but not limited to robotics, video games, natural language processing, computer vision, education, transportation, finance and healthcare.
⇧「深層強化学習(Deep Reinforcement Learning)」ってのは、「強化学習(Reinforcement Learning)」と「深層学習(Deep Learning)」をがっちゃんこした「機械学習(Machine Learning)」の一部ってことですと。
In many practical decision making problems, the states of the MDP are high-dimensional (eg. images from a camera or the raw sensor stream from a robot) and cannot be solved by traditional RL algorithms. Deep reinforcement learning algorithms incorporate deep learning to solve such MDPs, often representing the policy or other learned functions as a neural network, and developing specialized algorithms that perform well in this setting.


⇧ 一般的に、データが高次元の場合に、通常の「強化学習(Reinforcement Learning)」だと対処できないから、「深層学習(Deep Learning)」を盛り込んだってことらしい。
総務省が公開してる「ディープラーニングの進展と人づくり 東京大学 松尾 豊」ってPDFによると、
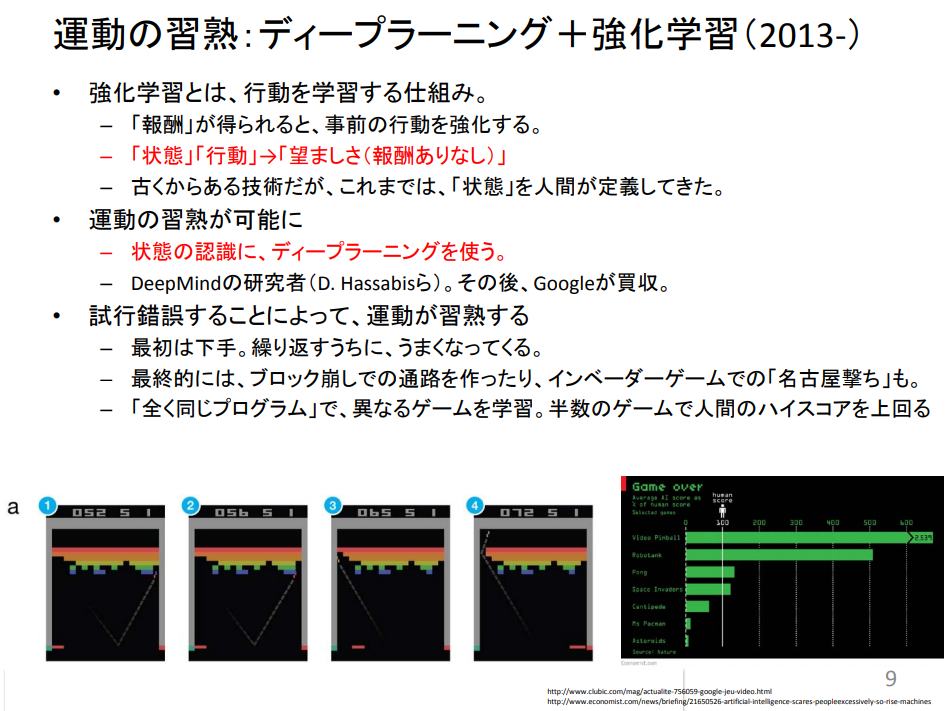

⇧「State:状態」の認識に「深層学習(Deep Learning)」を使った「強化学習(Reinforcement Learning)」、それが、「深層強化学習(Deep Reinforcement Learning)」ってことらしい。
イメージ的には、
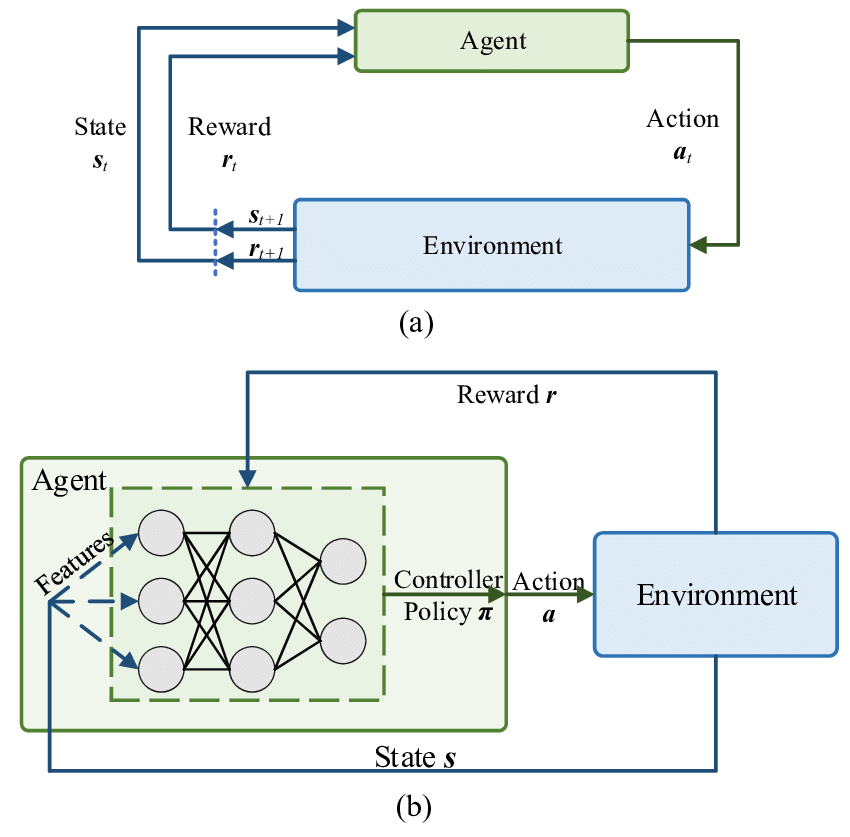
⇧ このあたりや、
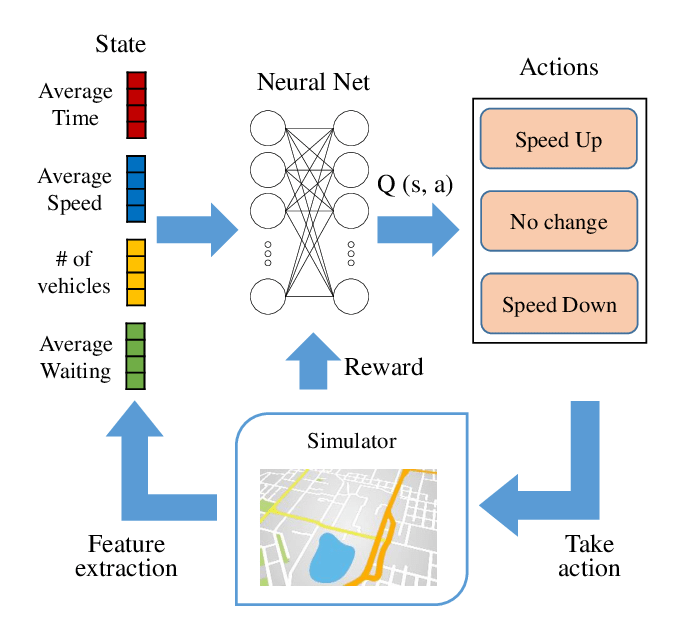
⇧ このあたりのイメージ図にあるような感じで、「State:状態」に対して「深層学習(Deep Learning)」による「特徴表現学習」を実施するってことなんかな?
というわけで、ちょっと、ネットに出回ってる情報が錯綜し過ぎな感が否めないので、整理していきたいところですね。
それにしても、研究者によって解釈がまちまちなのは、我々一般ピープルにとっては、どうして良いのか分からなくなるので何とかして欲しいよね...
モヤモヤ感が半端ないな...
何が言いたいかと言うと、
⇧ むちゃくちゃ時間をかけて調べて、スタートラインにも立ててないっちゅうことが分かったのかな(涙)。
こりゃ、やる気が出ないわ...
今回はこのへんで。