
OpenAIが一部のユーザーの名前やメールアドレス、位置情報などを含む個人情報が流出したことを発表しました。流出はOpenAIが使用していたデータ分析サービス「Mixpanel」のセキュリティインシデントが原因で、OpenAIのシステムそのものが攻撃されたわけではないとのことです。
OpenAIユーザーのメアドや位置情報が流出したことが判明、データ分析サービス経由でAPIユーザーの個人情報が流出 - GIGAZINE
Mixpanelはユーザーの製品使用状況を分析できるサービスで、OpenAIはAPI製品の使用状況分析にMixpanelを用いていました。このMixpanelが2025年11月9日に外部からの不正アクセスを受け、顧客識別情報や分析情報を含むデータセットが外部に流出したことが判明しました。OpenAIは2025年11月25日に影響を受けたデータの詳細をMixpanelと共有し、攻撃の事実を2025年11月26日に公表しました。
OpenAIユーザーのメアドや位置情報が流出したことが判明、データ分析サービス経由でAPIユーザーの個人情報が流出 - GIGAZINE
流出した可能性のあるデータは以下の通り。
・APIユーザーの名前
・APIユーザーのメールアドレス
・APIユーザーのブラウザから取得された位置情報(国・州・市など)
・APIユーザーが使っていたOSおよびブラウザ
・参照ウェブサイト
・APIアカウントに紐付けられていたユーザーIDもしくは組織ID
OpenAIユーザーのメアドや位置情報が流出したことが判明、データ分析サービス経由でAPIユーザーの個人情報が流出 - GIGAZINE
OpenAIは影響を受けた組織や個人に対する通知を進めています。また、Mixpanelの使用はすでに中止しており、その他の使用中の製品についても拡張的なセキュリティレビューを実施したとのこと。
OpenAIユーザーのメアドや位置情報が流出したことが判明、データ分析サービス経由でAPIユーザーの個人情報が流出 - GIGAZINE
⇧ 何と言うか、『OpenAIのシステムそのものが攻撃されたわけではない』と仰ってますが、「個人情報」が流出している時点で大問題な気がするのですが、海外だと「個人情報」流出は取るに足らない出来事になるのだろうか...
どうにも、「OpenAI」の他人事な感じが気になってしまいますな...
いまいち、影響範囲が不明瞭なのだが、「ログイン」したりしていなければ、問題なかったのかしら?
そもそも、「データ分析」に利用する「データ」の管理が杜撰過ぎるような気がしてしまいますが...
「マスク」処理とか施されていない無加工の生「データ」が流出したのだとしたら、誠に遺憾でありますな...
ChatGPTと壁打ち(PostgreSQLのストリーミングレプリケーション利用時の切り戻し)
とりあえず、
- 主系マシン
- 副系マシン
のような冗長構成で、「PostgreSQL」の「ストリーミングレプリケーション」を実現しているとする。
イメージとしては、
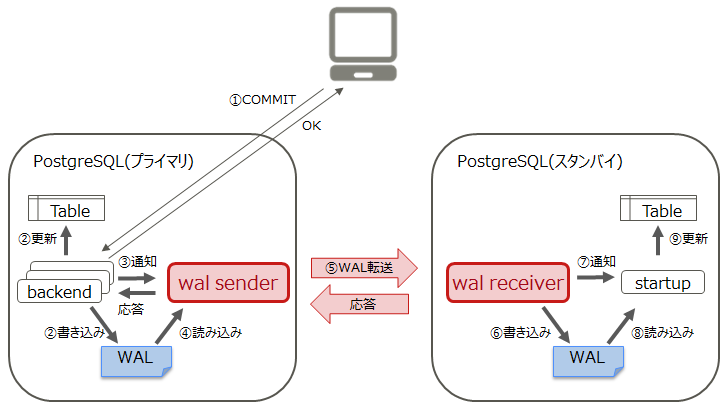
⇧ 上図のような構成であって、何某かの更新系の処理は「primary」側の「PostgreSQL」で実施され、「standby」側の「PostgreSQL」は、「primary」側の「PostgreSQL」から送られてくる「ログ先行書き込み(WAL:Write-Ahead Logging)」の内容を介して「データ」の同期を取っていますと。
公式のドキュメントによりますと、
max_wal_senders(integer)-
複数のスタンバイサーバあるいは、ストリーミングを使ったベースバックアップクライアントからの同時接続を受ける接続最大値を設定します(つまり、同時に稼動するWAL送信プロセスの最大値です)。 デフォルトは
10です。0ならば、レプリケーションは無効であるという意味になります。 ストリーミングクライアントの突然の切断により、タイムアウトになるまで親のない接続スロットが残ることがあります。 ですから、このパラメータは想定されるクライアント数の最大値よりも少し大きめにして、切断されたクライアントが直ちに再接続できるようにした方が良いでしょう。 このパラメータはサーバ起動時のみ設定可能です。 また、スタンバイサーバからの接続を許可するには、wal_levelをreplica以上に設定しておかなければなりません。
https://www.postgresql.jp/document/12/html/runtime-config-replication.html
⇧ 上記にある通り、「postgresql.conf」の「max_wal_senders」という設定項目の値を「0」にすれば、「ストリーミングレプリケーション」は無効になるということらしいですと。
公式のドキュメントの書きっぷりだと、「replica(standby)」側で「ポーリング」的なことをしているような感じなのかね?
いまいち、「PostgreSQL」の「機能」の「仕組み」が「ブラックボックス」化していることもあって、処理の「トリガー(起点)」が分かり辛いのよね...
「主系マシン」側の「pg_hba.conf」の設定で、「副系マシン」の「PostgreSQL」からの「レプリケーション」接続を許可するようにしておいてから、「副系マシン」で「pg_basebackup」を実行することによって、「副系マシン」に「主系マシン」の「バックアップ」が配置されるのだが、いざ、「切り戻し」をするとなった場合に、
- primary
- replica(standby)
の「切り替え」が必要になる時がありますと。
イメージとしては、
Azure Database for PostgreSQL の読み取りレプリカを昇格させる
昇格とは、レプリカがレプリカ モードを終了し、完全な読み取り/書き込み操作に移行するように命令されるプロセスを指します。
https://learn.microsoft.com/ja-jp/azure/postgresql/flexible-server/concepts-read-replicas-promote

プライマリ サーバーへの昇格
このアクションにより、レプリカがプライマリ サーバーのロールに昇格されます。 このプロセスでは、現在のプライマリ サーバーがレプリカ ロールに降格され、ロールが入れ替えられます。 昇格が成功するには、仮想エンドポイントが、現在のプライマリに対してライター エンドポイントとしてと、昇格の対象となるレプリカに対してリーダー エンドポイントとして、両方に構成されている必要があります。 昇格は、対象のレプリカがリーダー エンドポイント構成に含まれている場合にのみ成功します。
https://learn.microsoft.com/ja-jp/azure/postgresql/flexible-server/concepts-read-replicas-promote
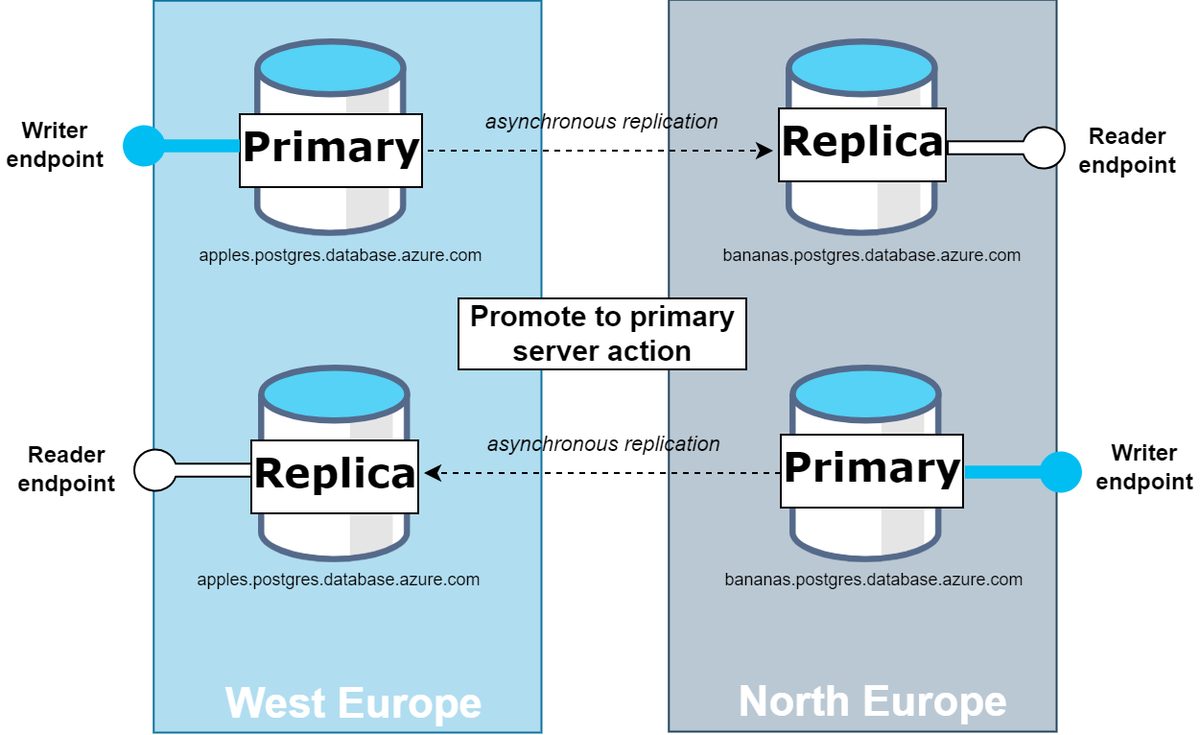
⇧ 上図のような感じのフローに、元の構成に戻す「切り替え」が追加で必要になるイメージ。
まぁ、具体的な方法については説明してくれていないのだが、
『昇格操作は自動ではありません。 プライマリ サーバーで障害が発生した場合、システムは読み取りレプリカへの切り替えを個別に行いません。 昇格操作には常にユーザー アクションが必要です。』
とあり、明示的な「切り替え」のための操作が必要とありますと。
と思ったら、別ページに「切り替え」の方法が説明されていた。
⇧ とりあえず、「Azure Portal」上の「Web画面」で実施する方法しか記載が無いのよ...
「Azure CLI」などによるコマンドで実現する方法も記載しておいて欲しいよね...
話が脱線しましたが、「PostgreSQL」の「ストリーミングレプリケーション」の「切り戻し」については、つまり、
| No | 状況 | 主系マシン | 副系マシン |
|---|---|---|---|
| 1 | 障害発生前/バックアップ取得時 | primary | replica(standby) |
| 2 | 障害発生/切り替え/バックアップから復元 | replica(standby) | primary |
| 3 | 元の構成に戻す | primary | replica(standby) |
のような流れになると。
「バックアップ」は「pg_baseback」コマンドによる「物理バックアップ」が「副系マシン」に配置されることから、
- primary
- replica(standby)
の「切り替え」が必要になって来るということですな。
シンプルなのは、
⇧ 上記サイト様にありますように、ファイル転送できるパターンなのだが、今の現場がファイル転送はNGということで、
- primary
- replica(standby)
を「切り替え」することで「切り戻し」する必要がありますと。
で、このあたりの話がネット上でほとんど語られていないのよな...
まぁ、
- フェイルオーバー(failover)
- 切り替え
- 復元
- フェイルバック(Failback)
- 切り戻し
あたりの用語の定義の範囲が曖昧なこともありますからな...
フェイルオーバー(英語: failover)は、現用系コンピュータサーバ/システム/ネットワークで異常事態が発生したとき、自動的に冗長な待機系コンピュータサーバ/システム/ネットワークに切り換える機能を意味する。
これに対して、何らかの異常を察知して、人間が手動で切り替えを行うことをスイッチオーバーという。
フェイルバック(英語: failback)または切り戻しとは、逆に、フェイルオーバーによって切り換えられたサーバ/システム/ネットワークを障害発生前の元の状態に戻す処理を意味する。
Failback
Failback is the process of restoring a system, component, or service previously in a state of failure back to its original, working state, and having the standby system go from functioning back to standby.
⇧ 上記の説明でも、「フェイルオーバー(failover)」は明確に「自動的」に「機能」するとあるのだが、「フェイルバック(Failback)」については「自動的」に「機能」するのか「手動」で「機能」させることになるのかがハッキリしないのよね...
まぁ、
- フェイルバック(Failback)
- 切り戻し
については、同じ意味として捉えることにするとして、「PostgreSQL」の「ストリーミングレプリケーション」において、
- 復元
- 切り戻し
の正確な手順が整理されていない感じなのよね...
致し方ないので、
- ChatGPT氏に質問する
- ChatGPT氏から回答が返って来る
- ネット上の情報を検索し「ファクトチェック」
- 1.に戻る
を繰り返す、所謂、「壁打ち」を行った。
まぁ、怒涛のような「幻覚(ハルシネーション)」によって不毛な時間を費やせざるを得ない状況を強制されることになるので、発狂しそうになるよね...
■列の説明
-
時間順 — 手順の通し番号または順序
-
主系マシン(作業) — そのタイミングで主に操作を加えるマシン
-
副系マシン(作業) — もう片方のマシンで操作があれば記載
-
主系マシン 役割 — primary or standby
-
主系マシン 稼働状況 — up / down
-
副系マシン 役割 — primary or standby
-
副系マシン 稼働状況 — up / down
-
事前確認/チェック内容 — 設定チェック、同期状態の確認、認証設定など
■切り戻しの作業フロー
| No. | 主系マシン(作業) | 副系マシン(作業) | 主系 役割 | 主系 状態 | 副系 役割 | 副系 状態 | 事前確認/チェック内容 |
|---|---|---|---|---|---|---|---|
| 1 | — | pg_basebackup によるバックアップ取得 |
primary | up | standby | up | 副系側が base backup を取得可能か確認(pg_hba.conf, REPLICATION ユーザ, 接続設定, WAL 設定など) |
| 2 | 主系: 停止 (pg_ctl stop) |
— | primary → (なし) | down | standby | up | — |
| 3 | 主系: 必要に応じて max_wal_senders=0 設定 + 再起動 |
— | (none) → standby?/無し | down → up/down | standby | up | 設定反映確認 (max_wal_senders=0) + WAL‑sender プロセスが立ち上がっていないか OSレベル確認 |
| 4 | — | 副系でバックアップ展開/ new_primary 用構築準備 | none | down | standby | up (構築中) | data ディレクトリ構成、設定ファイル (postgresql.conf, pg_hba.conf 等) の準備・確認 |
| 5 | — | 副系側で設定ファイル調整 (postgresql.conf, pg_hba.conf など) | none | down | standby | up (構築済) | 副系用設定の整合性確認(認証設定、接続設定、listen_addresses 等) |
| 6 | — | 昇格前チェック: pg_hba.conf 等接続設定確認 + reload/restart | none | down | standby | up | replication 接続許可があるか、認証/認可情報の整合性確認 |
| 7 | — | pg_ctl promote による昇格 |
none | down | standby → primary | up | 昇格後 SELECT pg_is_in_recovery(); → false を確認 |
| 8 | 主系側: data 削除 + pg_basebackup による再同期 |
副系 (現 primary) 側は稼働中 | standby | down → up/down? | primary | up | base backup の成功確認、エラーなしを確認 |
| 9 | 主系側起動 | 副系側 継続稼働 | standby | up | primary | up | 副系側で pg_stat_replication に standby 接続ありか確認 主系側で WAL 受信/再生追従状況確認 |
| 10 | — | 副系 (旧 standby) を停止 + 必要なら max_wal_senders=0 設定 + 再起動 |
standby | down | primary → none | down | 接続設定 (pg_hba.conf 等) が維持されているか確認 |
| 11 | 主系 側 (復帰先): 接続設定確認 + 必要あれば設定追加 + reload/restart | — | standby → none? | up → down? | — | down | pg_hba.conf に replication 接続許可あり、認証設定整合性、listen_addresses 等確認 |
| 12 | 主系側: pg_ctl promote による再昇格 (フェイルバック) |
— | none → primary | up | standby | down | 昇格後 SELECT pg_is_in_recovery(); → false を確認 |
| 13 | 設定復元 + 再起動 (必要であれば) | — | primary | up | standby | down | 設定値・接続設定の整合性チェック |
| 14 | — | — | primary (old-primary) | up | standby (old‑standby) | up | 主系側で pg_stat_replication に standby 接続確認 副系側で pg_is_in_recovery() → true & WAL 受信/再生正常か確認 |
🔎 コメント・補足事項
-
“主系/副系” の「役割 (primary/standby)」と「稼働状態 (up/down)」を分離することで、サーバが停止しているかどうかを明示でき、安全な手順管理につながります。
-
障害対応や復旧手順中は、サーバが “停止/構築中/再同期中” など「役割以外の状態」を持つことがあるため、この2軸管理は現実の運用に即しています。
-
各ステップで 設定チェック (pg_hba.conf, postgresql.conf 等)、同期状況の確認、認証設定の再確認 を明示することで、「設定ミス」「認証漏れ」「同期漏れ」の可能性を減らします。
-
昇格/再同期/フェイルバックなど、複数段階にわたる手順では、「チェック漏れ」「状態キャプチャ漏れ」 が問題になるため、この構造は監査・レビューにも使いやすい。
まぁ、結局のところ、公式のドキュメントで正しい一連の手順を説明してくれているわけでもないので、正しい手順が分からないのよな...
故に、作業する際には「心理的安全性」の欠片も無いので、ストレスが蓄積されていくだけでしか無いのが誠に遺憾であるのだよな...
検証するにしても、どうなればOKと言えるのかが、ファジー過ぎるんよな...
気持ち悪さの原因は、
- 正常に動作している状態
- フェイルオーバー(failover)によって正常に動作している状態
- フェイルバック(Failback)によって正常に動作している状態
- 障害対応を経て正常に動作している状態
- etc...
の「状態」の区別を付けるための確認方法と、どう「状態遷移」させれば良いかがハッキリしないところなのかしらね...
「プログラミング」の世界だと、
- イミュータブル(immutable)
- ミュータブル(mutable)
の内、「イミュータブル(immutable)」が好まれるのは、「状態」を持たせたくないということだと思いますが、「保守・運用」系の作業は「状態」によって手順が変わる以上、「状態」を避けて通れないのよな...
コンピュータプログラミングにおいて、イミュータブル (英: immutable) なオブジェクトとは、作成後にその状態を変えることのできないオブジェクトのことである。対義語はミュータブル (英: mutable) なオブジェクトで、作成後も状態を変えることができる。mutableは「変更可能な」、immutableは「変更不可能な、不変の」という意味を持つ形容詞である。
イミュータブルなオブジェクトを使うと、複製や比較のための操作を省けるため、コードが単純になり、また性能の改善にもつながる。しかしオブジェクトが変更可能なデータを多く持つ場合には、イミュータブル化は不適切となることが多い。このため、多くのプログラミング言語ではイミュータブルかミュータブルか選択できるようにしている。
⇧ まぁ、「ミュータブル(mutable)」だと、「ソースコード」の読解の負担が跳ね上がりますからな...
どこで変更されているか確認するために、関連する全ての処理を初めから最後まで注意深く読解せねばならなくなるので、非常にストレスになるのよね...
分かり易い弊害としては、「影響範囲」の調査とかが、地獄の作業になるのよね...
所謂、「変更容易性」の著しく低い「ソースコード」になってしまうリスクは高くなる傾向にあると思われますと。
毎度モヤモヤ感が半端ない…
今回はこのへんで。