
スーパーコンピューターの計算速度の世界ランキング「TOP(トップ)500」が発表され、米ローレンスリバモア国立研究所の「エルキャピタン」が前回6月に続きトップとなり、3連覇した。毎秒100京回(京は1兆の1万倍)を意味する「エクサ級」のスパコンは、整備を完了したドイツの1台が加わり、集計上4台となった。理化学研究所の「富岳(ふがく)」は7位を維持。理研は後継機を2030年頃に稼働する計画だ。
スパコン速度、米「エルキャピタン」が3連覇 「富岳」は7位維持 | Science Portal - 科学技術の最新情報サイト「サイエンスポータル」
上位500台の内訳は米国が最多の172台。日本は43台でこれに続き、前回4位から浮上した。以下、ドイツ40台、中国39台、フランス22台が続いた。一方、中国は近年、TOP500への参加に対し消極姿勢に転じており、既に複数のエクサ級スパコンを開発済みとされる。
スパコン速度、米「エルキャピタン」が3連覇 「富岳」は7位維持 | Science Portal - 科学技術の最新情報サイト「サイエンスポータル」
TOP500のランキング上位は次の通り(名称、設置組織、国、毎秒の計算速度)。
1位 エルキャピタン ローレンスリバモア国立研究所(米国)180京9000兆回
2位 フロンティア オークリッジ国立研究所(米国)135京3000兆回
3位 オーロラ アルゴンヌ国立研究所(米国)101京2000兆回
4位 ジュピターブースター ユーリッヒ研究センター(ドイツ)100京回
5位 イーグル マイクロソフト社(米国)56京1200兆回
スパコン速度、米「エルキャピタン」が3連覇 「富岳」は7位維持 | Science Portal - 科学技術の最新情報サイト「サイエンスポータル」
⇧「毎秒の計算速度」だけで見た場合、4位の「ドイツ」が、3位の「アメリカ」に近づいて来ていると。
相変わらず、「アメリカ」が、ランキング上位の「1位(金)」「2位(銀)」「3位(銅)」を独占しているようですが、「欧州」勢が台頭して来るのかしら?
と言うか、ランキングに参加していなくて性能の良い「スーパーコンピューター」が存在するかもしれない可能性もあると。
「中国」の「スーパーコンピューター」が突出している可能性もあるような話が出てますが、事実かどうかは分からずという状態みたいね...
PostgreSQLのストリーミングレプリケーション機能とは
公式のドキュメントを確認した限り、
■PostgreSQL 12のドキュメント
19.6. レプリケーション
これらの設定は組み込みのストリーミングレプリケーション機能の動作を制御します(26.2.5を参照ください)。 サーバ群のサーバはマスターかスタンバイのいずれかです。マスターはデータを送出する一方、複数のスタンバイは複製されたデータを常に受け取ります。カスケードレプリケーション(26.2.7を参照)が使用されている場合、スタンバイサーバ群は受け取り手でもあり、送り手でもあります。 パラメータは主として送出サーバとスタンバイサーバ用ですが、いくつかのパラメータはマスターサーバのみに効力を発します。 必要とあればクラスタに渡って問題なく設定を変化させることができます。
https://www.postgresql.jp/document/12/html/different-replication-solutions.html
■PostgreSQL 17のドキュメント
19.6. レプリケーション
これらの設定は、組み込みストリーミングレプリケーション機能(26.2.5参照)および組み込み論理レプリケーション機能(第29章を参照)の動作を制御します。 26.2.5
ストリーミングレプリケーションでは、サーバ群のサーバはプライマリかスタンバイのいずれかです。 プライマリはデータを送出する一方、複数のスタンバイは複製されたデータを常に受け取ります。 カスケードレプリケーション(26.2.7を参照)が使用されている場合、スタンバイサーバ群は受け取り手でもあり、送り手でもあります。 パラメータは主として送出サーバとスタンバイサーバ用ですが、いくつかのパラメータはプライマリサーバのみに効力を発します。 必要とあればクラスタに渡って問題なく設定を変化させることができます。
論理レプリケーションの場合、パブリッシャー(CREATE PUBLICATIONを実行するサーバ)は、データをサブスクライバー(CREATE SUBSCRIPTIONを実行するサーバ)に複製します。 サーバは、パブリッシャーとサブスクライバーを同時に兼ねることもできます。 以降の節でパブリッシャーを「送信者」と呼ぶことに注意してください。 論理レプリケーション設定設定の詳細は、29.11を参照してください。
https://www.postgresql.jp/document/17/html/runtime-config-replication.html
⇧ バージョンによって説明が異なるのだが、
| No | レプリケーションの種類 | ドキュメントのバージョン |
|---|---|---|
| 1 | ストリーミングレプリケーション (built-in streaming replication) |
PostgreSQL 9.1.5文書時点で記載在り |
| 2 | カスケードレプリケーション (cascading replication) |
PostgreSQL 9.2.4文書から記載在り |
| 3 | 論理レプリケーション (built-in logical replication) |
PostgreSQL 16.4文書から記載在り |
といった状態であり、「PostgreSQL」が提供している「レプリケーション」の機能の内の1つが、「ストリーミングレプリケーション」ということみたい。
一応、「ストリーミングレプリケーション」は、
表26.1 高可用性、負荷分散およびレプリケーションの特徴
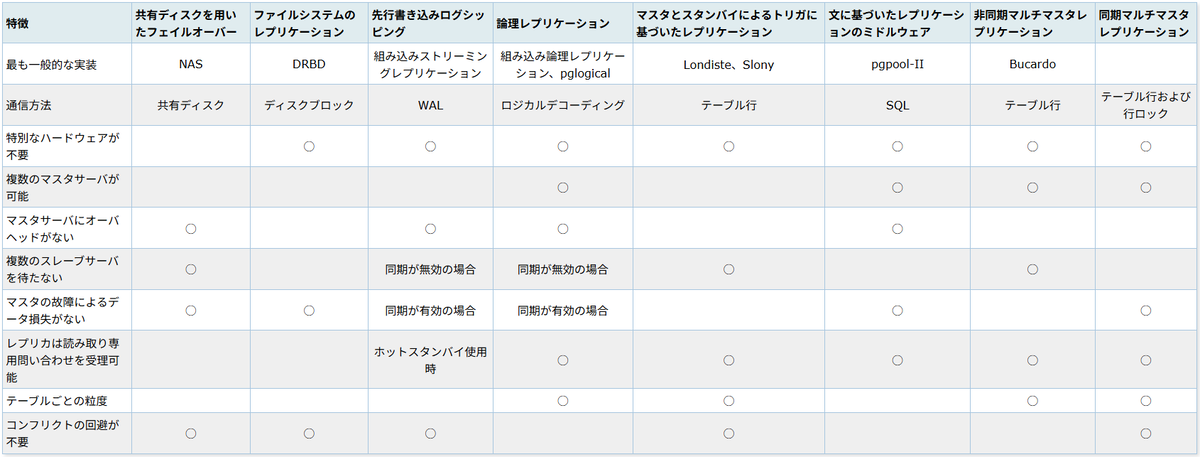
https://www.postgresql.jp/document/12/html/different-replication-solutions.html
⇧「最も一般的な手法」として挙げられている。
仕組みとしては、
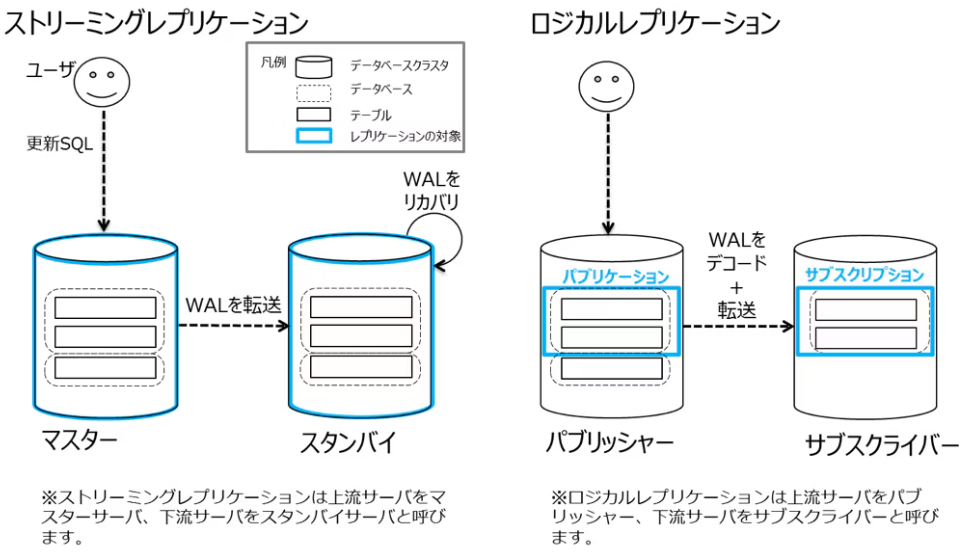
⇧ 上記サイト様で解説されているように、「PostgreSQL」の「データベースクラスタ」が対象ということらしい。
ストリーミングレプリケーションは、マスター側から全てのトランザクションログ(WAL)を転送し、スタンバイ側はWALを適用(リカバリ)します。WALにはデータベースの全ての変更情報が物理的なレベルで記載されています。このWALを適用することで、データベースクラスタの完全なコピーが作成できます。
そのため、ストリーミングレプリケーションは負荷分散や、PacemakerなどのHAソフトと組み合わせて可用性を高めるために利用されています。ただし、WALをそのままリカバリするためPostgreSQLのメジャーバージョンや、OSのアーキテクチャが異なる場合は、実施不可となります。
⇧「マスター」側の「PostgreSQL」の変更内容が、「ログ先行書き込み(WAL:Write-Ahead Logging)」によって「スタンバイ」側の「PostgreSQL」に反映されて「データ」の整合性などが同期される仕組みらしい。
とりあえず、
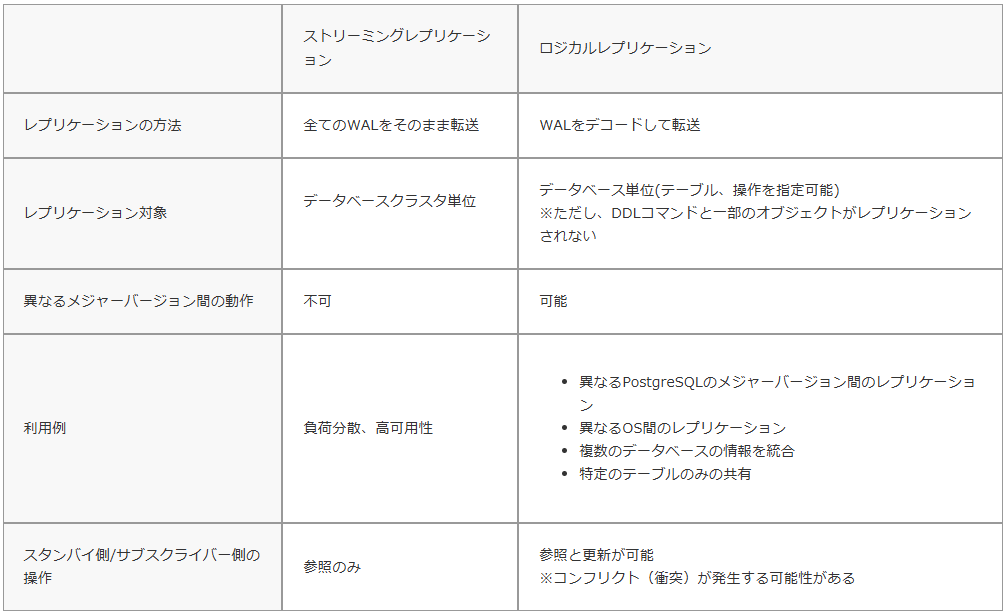
⇧「スタンバイ」側での操作は「参照系」に限られるらしいので、「マスター」側が何某かの障害でシステムが機能しなくなった場合、「スタンバイ」側に「ログ先行書き込み(WAL:Write-Ahead Logging)」が送られなくなると、「スタンバイ」側の「データ」は更新されなくなるということかと。
PostgreSQL 12でストリーミングレプリケーションの機能を利用できる環境にしてみる
前回、
⇧ 上記の記事の時に、「Vagrant」と「VirtualBox」で「Almalinux 8.10」の仮想マシンに「PostgreSQL 12.7」をビルドしてインストールし、サービスとして起動させるところまで完了しました。
⇧ 上記サイト様を参考に、「PostgreSQL」の「ストリーミングレプリケーション」の機能を利用できるようにしていきたいと思います。
ちなみに、「レプリケーションスロット」が無い場合でも「ストリーミングレプリケーション」の機能は利用できるらしいのだが、「ChatGPT」氏によると、以下の理由から「レプリケーションスロット」は利用した方が良い模様。
🧩 レプリケーションスロットの役割(使うと何が起きるか)
レプリケーションスロットを作成すると:
-
WAL がレプリカに送られるまで削除されない
-
レプリカが遅れても 追いつけなくなることがなくなる
-
一時的なネットワーク断でも確実に同期が継続できる
つまり、レプリケーションの安定性が大幅に上がる。
❗ ただしスロットのデメリット(注意点)
スロットを使うと:
● レプリカが長時間ダウンすると…
WAL が溜まり続ける
→ ディスク満杯(ストレージ枯渇)のリスク
対策:
-
max_slot_wal_keep_sizeを設定する(自動削除を許す) -
監視を入れる
✅ PostgreSQL 12 でのスロット運用の場合
-
WAL が溜まりすぎないように制御する設定はない
→ スロットがある限り、スタンバイが長時間停止すると WAL がどんどん溜まる -
ディスク満杯になる可能性があるので、運用での注意が必要
■PostgreSQL のバージョンによる対応の差異
| PostgreSQL バージョン | max_slot_wal_keep_size の可否 |
|---|---|
| 12 | ❌ なし → 自分で監視が必要 |
| 13 以上 | ✅ あり → 自動制御可能 |
✅ 結論まとめ
| 項目 | スロットなし | スロットあり |
|---|---|---|
| 必要か? | 不要 | 不要(任意) |
| 安定性 | 低い(追いつけなくなる可能性) | 高い |
| WAL削除リスク | あり | レプリカに送られるまで削除されない |
| デメリット | とくになし | WAL が溜まりすぎる可能性 |
➡ 大規模・本番運用:スロット使用推奨
➡ テスト・小規模:スロットなしでもOK
というわけで、「ChatGPT」氏に、
- マスター(primary)
- スタンバイ(replica)
の各々で必要な作業について整理してもらった。
■ストリーミングレプリケーション(レプリケーションスロット導入版)の構築の作業概要
■■マスター(primary)での作業概要
postgresql.conf編集するpg_hba.confでレプリケーション接続許可の設定を追加する- PostgreSQL サーバーのサービスを再起動し設定変更を反映する
- PostgreSQLでクエリ実行する
■■スタンバイ(replica)での作業概要
- データディレクトリ初期化
pg_basebackup -Rでベースバックアップ取得(スロット付き)- ⚠️
-Rでstandby.signalとprimary_conninfoが自動生成されます - ⚠️ ただし、slot 名(primary_slot_name)は自動で入らない
- ⚠️
- primary_slot_name を自動設定ファイルに追記(重要)
- スタンバイ(replica)起動
■動作確認の作業概要
■■マスター(primary)での作業概要
- Primary 側(スロット確認)
- Primary 側(レプリケーション状態)の確認
■■スタンバイ(replica)での作業概要
- Standby 側(追従状況)
といった作業フローになるようだ。
「ChatGPT」氏の作業手順通りに進めてみる。
作業手順の実施は、各々の環境へログインして行うものとする。
■ストリーミングレプリケーション(レプリケーションスロット導入版)の構築の作業詳細
■■マスター(primary)での作業詳細
1.postgresql.conf 編集
マスター(primary)側のpostgresql.conf に以下の設定を行う。
# 全てのIPから接続可能にする listen_addresses = '*' # PostgreSQL のデフォルトポートを利用しているのであれば、コメントアウトしたままでもOKっぽい port = 5432 wal_level = replica max_wal_senders = 10 max_replication_slots = 10 # スロットによる WAL の溜まりすぎ防止(MB) # ※ PostgreSQL 13から導入された設定項目 #max_slot_wal_keep_size = 2048 # 念のため WAL の最低保持 # ※ PostgreSQL 13から導入された設定項目 #wal_keep_size = 1024 # 512MB保持(1セグメント16 MiB) wal_keep_segments = 32
2.pg_hba.conf でレプリケーション接続許可の設定を追加する
スタンバイ(replica)側からの通信を許可する設定を追加する。
host replication replica_user 172.25.50.12/24 md5
3.PostgreSQL サーバーのサービスを再起動し設定変更を反映する
sudo systemctl restart postgresql-12
PostgreSQLサーバーのサービスの状態を確認する
sudo systemctl status postgresql-12
4.PostgreSQLでクエリ実行する
4-1. レプリケーションユーザを作成する
PostgreSQLサーバーにログインする
psql -U postgres
レプリケーションユーザを作成する。PostgreSQLサーバーからログアウトする
CREATE ROLE replica_user WITH REPLICATION LOGIN ENCRYPTED PASSWORD 'replica_pass'; \q
4-2. レプリケーションスロットを作成する
ユーザーpostgresに切り替え
sudo su - postgres
psql -c "SELECT pg_create_physical_replication_slot('standby_slot');"
レプリケーションスロットが作成されたか確認する
psql -c "SELECT slot_name, active, restart_lsn FROM pg_replication_slots;"
■■スタンバイ(replica)での作業詳細
1.データディレクトリ初期化
PostgreSQLサーバーのサービスを停止する
sudo systemctl stop postgresql-12
PostgreSQLサーバーのサービスの状態を確認する
sudo systemctl status postgresql-12
データディレクトリをリネームする
※ データディレクトリを退避していることになる。ディスク容量的に厳しい場合は削除する感じになるかと。
sudo mv /usr/local/pgsql12/data /usr/local/pgsql12/data_`date '+%Y-%m-%d'`
データディレクトリを作成する
sudo mkdir -p /usr/local/pgsql12/data
データディレクトリの所有者をpostgres:psotgresにする
sudo chown postgres:postgres /usr/local/pgsql12/data
データディレクトリの権限を変更する
sudo chmod 700 /usr/local/pgsql12/data
2.pg_basebackup -R でベースバックアップ取得(スロット付き)
マスター(primary)のバックアップを取得する
※ パスワードを求めらた場合は、PostgreSQL のロールreplica_userのパスワードを入力する。
sudo -iu postgres /usr/local/pgsql12/bin/pg_basebackup \ -h 172.25.50.11 \ -U replica_user \ -D /usr/local/pgsql12/data \ -Fp -Xs -P -R \ --slot=standby_slot
ポイント:
-
-R→ standby.signal + primary_conninfo を自動生成 -
--slot=standby_slot→ スロットから WAL を取る
※ しかし primary_slot_name は設定されないので後で追加する
standby.signalが生成されているか確認する
ls -la /usr/local/pgsql12/data
3.primary_slot_name を自動設定ファイルに追記(重要)
echo "primary_slot_name = 'standby_slot'" >> /usr/local/pgsql12/data/postgresql.auto.conf
ユーザーpostgresからログアウトする
exit
スタンバイ(replica)起動
停止していたスタンバイ(replica)側のPostgreSQL サーバーのサービスを起動する
sudo systemctl start postgresql-12
スタンバイ(replica)側のPostgreSQL サーバーのサービスの状態を確認する
sudo systemctl status postgresql-12
■動作確認の作業詳細
■■マスター(primary)での作業詳細
1.Primary 側(スロット確認)
sudo su - postgres
psql -c "SELECT slot_name, active, restart_lsn FROM pg_replication_slots;"
2.Primary 側(レプリケーション状態)の確認
psql -c "SELECT pid, state, sync_state, write_lsn, flush_lsn, replay_lsn FROM pg_stat_replication;"
■■スタンバイ(replica)での作業詳細
1.Standby 側(追従状況)
sudo su - postgres
psql -c "SELECT pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();"
⇧ で、ストリーミングレプリケーションの機能 + レプリケーションスロットの利用ができる状態になるっぽい。
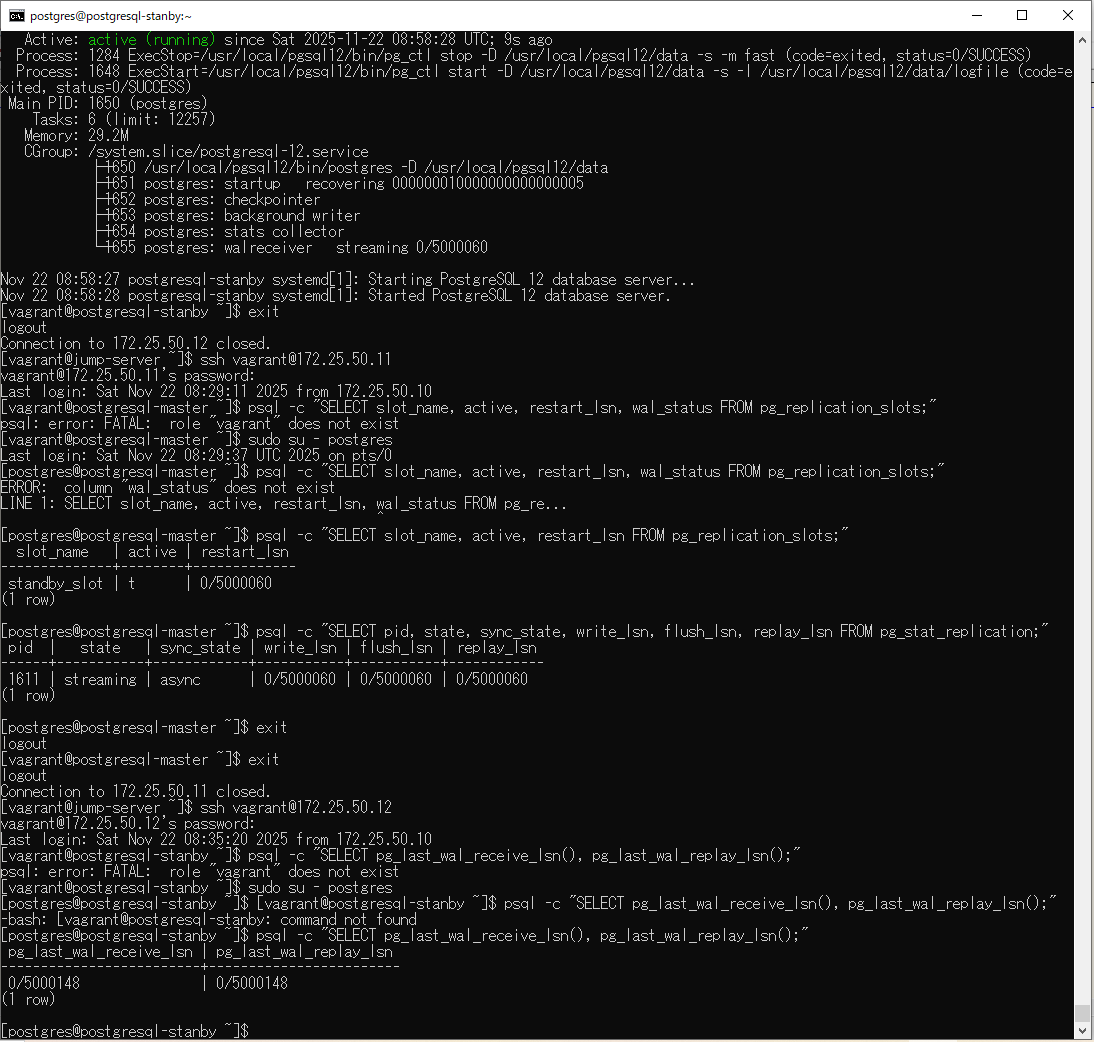
あとは、「マスター(primary)」側のPostgreSQLサーバーのデータベースで更新系の処理が実施されると、「スタンバイ(replica)」側のPostgreSQLサーバーに「ログ先行書き込み(WAL:Write-Ahead Logging)」が転送されてきたものを適用することで、「データ」の同期が取れるというっことみたいね。
「ChatGPT」氏に、同期されるタイミングについて質問してみたところ、以下のような回答が返ってきた。
💡 ポイント
-
WAL は変更ログ
-
INSERT / UPDATE / DELETE / CREATE / ALTER など データベースを変更する操作 を記録
-
SELECT のような読み取りだけでは WAL はほとんど増えません
-
-
レプリケーションへの転送
-
スタンバイはマスターの WAL を受け取って適用します
-
もしマスターで更新が発生しなければ、スタンバイには転送する WAL が無い状態になります
-
-
影響
-
スタンバイは「ほぼ同期状態」ですが、WAL が無ければ遅延も発生しません
-
定期的に WAL を送るわけではなく、変更があるときだけ送る仕組み です
-
なるほど、「マスター側(primary)」が更新系の処理が実行されない限り、「ログ先行書き込み(WAL:Write-Ahead Logging)」が転送されてくることはほぼ無いと。
一応、「PostgreSQL」の「バージョン」毎の設定の差異とかについても、「ChatGPT」氏に質問してみたところ、以下のような回答が返ってきた。
■PostgreSQLのバージョン毎の設定の差異
| 設定項目 | 説明 | 9.6 | 10 | 11 | 12 | 13 | 14+ | 設定可能ファイル/方法 | 備考 |
|---|---|---|---|---|---|---|---|---|---|
| wal_level | WAL の生成レベル | ○ | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| max_wal_senders | 同時に送信できる WAL プロセス数 | ○ | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| wal_keep_segments | 古い WAL を保持するセグメント数 | ○ | ○ | ○ | ○ | 非推奨 | 非推奨 | postgresql.conf / auto.conf | 代わりに wal_keep_size を推奨 |
| wal_keep_size | 古い WAL を保持するサイズ(MB) | - | - | - | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| hot_standby | スタンバイで読み取り可能にする | ○ | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| recovery_min_apply_delay | WAL 適用の遅延時間 | - | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| synchronous_standby_names | 同期レプリケーション対象スタンバイ名 | ○ | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| primary_conninfo | スタンバイ側接続情報 | recovery.conf | recovery.conf | recovery.conf | standby.signal + postgresql.conf | standby.signal + postgresql.conf | standby.signal + postgresql.conf | recovery.conf / standby.signal | postgresql.conf に直接書くのは不可 |
| wal_receiver_status_interval | WAL レシーバのマスターへの報告間隔(秒) | ○ | ○ | ○ | ○ | ○ | ○ | postgresql.conf / auto.conf | |
| max_slot_wal_keep_size | レプリケーションスロットで保持する WAL サイズ | - | - | - | - | ○ | ○ | postgresql.conf / auto.conf | |
| postgresql.auto.conf | ALTER SYSTEM で変更した設定の保存先 | - | - | - | ○ | ○ | ○ | ALTER SYSTEM で設定可能、自動保存 |
2025年11月24日(月)追記:↓ ここから
いまいち、「ストリーミングレプリケーション」の「機能」を利用した時に採用できる「スタンバイ」の方式についてハッキリしないのだが、
- 先行書き込みログシッピング
-
ウォームスタンバイおよびホットスタンバイサーバは、ログ先行書き込み(WAL)のレコードを解読して最新の状態を保持できます。 プライマリサーバが故障したとき、スタンバイサーバがプライマリサーバのほぼすべてのデータを保存して、速やかに新しい主データベースを稼動できます。 本解法は同期、非同期で行うことができ、データベース全体だけを範囲として処理できます。
スタンバイサーバは、ファイル単位のログシッピング(26.2参照)またはストリーミングレプリケーション(26.2.5参照)または両者の併用を使用して実装できます。 ホットスタンバイの情報は 26.5 を参照してください。
https://www.postgresql.jp/document/12/html/different-replication-solutions.html
⇧ 公式のドキュメントを見た感じでは、
- ホットスタンバイ(Hot Standby)
- ウォームスタンバイ(Warm Standby)
のどちらかになるようだ。
「ChatGPT」氏に質問してみたところ、以下のような回答が返ってきた。
✅ PostgreSQL メジャーバージョン別 × スタンバイ種類 × SR同期/非同期 × 停止時間 × 設定方式
| PostgreSQL バージョン | スタンバイ種類 | SR同期 | SR非同期 | 読み取り可否 | 停止時間 | 現行設定(postgresql.conf + signal) | 廃止設定(recovery.conf) |
|---|---|---|---|---|---|---|---|
| 9.x | Hot Standby | ◯ | – | ◯ | ★ 数秒以内 | postgresql.conf + standby.signal:・ hot_standby=on・ primary_conninfo='...'・ synchronous_standby_names='...' |
recovery.conf:・ standby_mode=on・ primary_conninfo='...'・ hot_standby=on・ synchronous_standby_names='...' |
| 9.x | Warm Standby | ◯ | – | × | ☆ 数秒〜十数秒 | postgresql.conf + standby.signal:・ hot_standby=off・ primary_conninfo='...'・ synchronous_standby_names='...' |
recovery.conf:・ standby_mode=on・ primary_conninfo='...'・ hot_standby=off・ synchronous_standby_names='...' |
| 9.x | Hot Standby | – | ◯ | ◯ | ★ 数秒以内 | postgresql.conf + standby.signal:・ hot_standby=on・ primary_conninfo='...' |
recovery.conf:・ standby_mode=on・ primary_conninfo='...'・ hot_standby=on |
| 9.x | Warm Standby | – | ◯ | × | ☆ 数秒〜十数秒 | postgresql.conf + standby.signal:・ hot_standby=off・ primary_conninfo='...' |
recovery.conf:・ standby_mode=on・ primary_conninfo='...'・ hot_standby=off |
| 9.x | Cold Standby | × | × | × | △ 数十秒〜数分 | postgresql.conf + recovery.signal:・ restore_command='...'・ recovery_target_time='...' |
recovery.conf:・ restore_command='...'・ recovery_target_time='...' |
| 10.x | Hot Standby | ◯ | – | ◯ | ★ 数秒以内 | 同上 | 同上 |
| 10.x | Warm Standby | ◯ | – | × | ☆ 数秒〜十数秒 | 同上 | 同上 |
| 10.x | Hot Standby | – | ◯ | ◯ | ★ 数秒以内 | 同上 | 同上 |
| 10.x | Warm Standby | – | ◯ | × | ☆ 数秒〜十数秒 | 同上 | 同上 |
| 10.x | Cold Standby | × | × | × | △ 数十秒〜数分 | 同上 | 同上 |
| 11.x | Hot Standby | ◯ | – | ◯ | ★ 数秒以内 | 同上 | 同上 |
| 11.x | Warm Standby | ◯ | – | × | ☆ 数秒〜十数秒 | 同上 | 同上 |
| 11.x | Hot Standby | – | ◯ | ◯ | ★ 数秒以内 | 同上 | 同上 |
| 11.x | Warm Standby | – | ◯ | × | ☆ 数秒〜十数秒 | 同上 | 同上 |
| 11.x | Cold Standby | × | × | × | △ 数十秒〜数分 | 同上 | 同上 |
| 12.x | Hot Standby | ◯ | – | ◯ | ★ 数秒以内 | postgresql.conf + standby.signal:・ hot_standby=on・ primary_conninfo='...'・ synchronous_standby_names='...' |
– |
| 12.x | Warm Standby | ◯ | – | × | ☆ 数秒〜十数秒 | postgresql.conf + standby.signal:・ hot_standby=off・ primary_conninfo='...'・ synchronous_standby_names='...' |
– |
| 12.x | Hot Standby | – | ◯ | ◯ | ★ 数秒以内 | postgresql.conf + standby.signal:・ hot_standby=on・ primary_conninfo='...' |
– |
| 12.x | Warm Standby | – | ◯ | × | ☆ 数秒〜十数秒 | postgresql.conf + standby.signal:・ hot_standby=off・ primary_conninfo='...' |
– |
| 12.x | Cold Standby | × | × | × | △ 数十秒〜数分 | postgresql.conf + recovery.signal:・ restore_command='...'・ recovery_target_time='...' |
– |
| 13.x | … | … | … | … | … | 同上 | – |
| 14.x | … | … | … | … | … | 同上 | – |
| 15.x | … | … | … | … | … | 同上 | – |
| 16.x | … | … | … | … | … | 同上 | – |
| 17.x | … | … | … | … | … | 同上 | – |
とりあえず、「PostgreSQL」の公式のドキュメントは、情報の整理をもう少し頑張って欲しいお気持ち...
まぁ、「ファインダビリティ(Findability)」が酷いの一言よね...
2025年11月24日(月)追記:↑ ここまで
あと、「PostgreSQL」のバージョン毎で利用できる「レプリケーション」の方式を「ChatGPT」氏に質問してみたところ、以下のような回答が返ってきた。
📊 PostgreSQL バージョン別レプリケーション方式
| バージョン | ストリーミング(物理) | 同期レプリケーション | カスケードレプリケーション | ロジカルレプリケーション | Replication Slot | 備考 |
|---|---|---|---|---|---|---|
| 8.4 以前 | ❌ | ❌ | ❌ | ❌ | ❌ | WAL Shipping のみ |
| 9.0 | ✅ 導入 | ❌ | ❌ | ❌ | ❌ | 物理レプリケーション初登場 |
| 9.1 | ✅ | ✅ 導入 | ❌ | ❌ | ❌ | 同期レプリケーション導入 |
| 9.2 | ✅ | ✅ | ✅ 導入 | ❌ | ❌ | カスケードレプリケーション追加 |
| 9.3 | ✅ | ✅ | ✅ | ❌ | ❌ | 改良版タイムライン管理 |
| 9.4 | ✅ | ✅ | ✅ | (Logical Decoding) | ✅ Slot 導入 | ロジカルデコード追加 |
| 9.5 | ✅ | ✅ | ✅ | ❌(正式は10〜) | ✅ | レプリケーション改善 |
| 9.6 | ✅ | ✅ | ✅ | ❌ | ✅ | remote_apply サポート |
| 10 | ✅ | ✅ | ✅ | ✅ 正式導入 | ✅ | Logical Pub/Sub |
| 11 | ✅ | ✅ | ✅ | ✅ | ✅ | TRUNCATE など対応 |
| 12 | ✅ | ✅ | ✅ | ✅ | ✅ | 物理・ロジカルの安定化 |
| 13 | ✅ | ✅ | ✅ | ✅ | ✅ | DDL レプリケーション拡張 |
| 14 | ✅ | ✅ | ✅ | ✅ | ✅ | ロジカル性能向上 |
| 15 | ✅ | ✅ | ✅ | ✅ | ✅ | フィルタリング強化 |
| 16 | ✅ | ✅ | ✅ | ✅ | ✅ | 双方向レプリケーション強化 |
| 17(最新) | ✅ | ✅ | ✅ | ✅ | ✅ | ロジカル全面拡張 |
📝 補足:主要レプリケーション方式の導入バージョンまとめ
-
ストリーミングレプリケーション → 9.0
-
同期レプリケーション → 9.1
-
カスケードレプリケーション → 9.2
-
Replication Slot → 9.4
-
Logical Decoding(ロジカル前段) → 9.4
-
ロジカルレプリケーション(正式) → 10
とりあえず、「PostgreSQL 12」からはバージョンアップしたいところですな...
公式のドキュメントを見た限り、「PostgreSQL 13」まで「サポート終了」しているっぽいですし、「ソースコード」からビルドするのは辛過ぎるのよ...
毎度モヤモヤ感が半端ない…
今回はこのへんで。