
米国家安全保障局(NSA)は米国時間11月10日、ソフトウェアのメモリー安全性強化に向けたガイダンスを公開した。同機関はその中で開発者らに対して、ハッカーらによるリモートコード実行(RCE)をはじめとするさまざまな攻撃からコードを保護するために、C#やGo、Java、Ruby、Swift、Rustといったメモリー安全性の高い言語に移行するよう推奨している。
⇧ 移行コストを考えると、作り直しと変わらなくなる気が...
Spring Batch単独ではバッチの定期実行はできない
公式のドキュメントによりますと、
Spring Batch はスケジューリングフレームワークではありません。多くの優れたエンタープライズスケジューラ(Quartz、Tivoli、Control-M など)が有償およびオープンソースの両方のスペースで利用可能です。スケジューラを置き換えることではなく、スケジューラと連動することを目的としています。
⇧ とあり、Spring Batch自身はスケジュール機能を持っていないようです。つまり、Spring Batch単体ではバッチの定期実行はできないということかと。
Spring Batchでバッチの定期実行を行ってみる
Quartzなどライブラリを使わない場合は、
⇧ 上記サイト様によりますと、
- @EnableScheduling
- @Scheduled
の2つのアノテーションが必要になる模様。
あと、
⇧ jobParameterの値が一意でないとエラーが起こるらしい...
更に、何故かは分からないのだけど、@ScheduledでJobを実行すると、CSVファイルのデータを繰り返し書き込むという謎仕様...
stackoverflowの回答で、
A step will only stop when it reads null values in its ItemReader implementation.You need to make sure that the reader implementation reads and returns null at some point of time. Then the step will stop on its own.
https://stackoverflow.com/questions/15531147/cant-stop-spring-batch-step
⇧ とあるんだけど、そもそも、@Scheduledを付けないで実行してた時はCSVファイルのデータ分だけ処理できてたので謎過ぎる...
ブラックボックス部分が多くて辛い...
というわけで、Spring Batchの定期実行を試してみますが、CSVファイルのデータが繰り返しINSERTされる部分は解消できてません...
プロジェクトは、
⇧ 上記の記事のものを利用していきます。変更、追加したファイルのみ内容を記載。
■/mybatis-example/src/main/resources/application.properties
# データベース接続 spring.datasource.driver-class-name=org.postgresql.Driver spring.datasource.url=jdbc:postgresql://localhost:5434/test spring.datasource.username=postgres spring.datasource.password=postgres # MyBatisでEntityクラスのフィールド名とデータベースのテーブルのカラム名の対応 mybatis.configuration.map-underscore-to-camel-case=true # バッチ処理が自動で実行されないように設定 spring.batch.job.enabled=false
■/mybatis-example/src/main/java/com/example/demo/batch/user/UserReader.java
package com.example.demo.batch.user;
import java.io.FileReader;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.Arrays;
import java.util.Objects;
import org.springframework.batch.item.ReaderNotOpenException;
import org.springframework.batch.item.file.ResourceAwareItemReaderItemStream;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.DefaultFieldSet;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import org.springframework.validation.BindException;
import com.opencsv.CSVParserBuilder;
import com.opencsv.CSVReader;
import com.opencsv.CSVReaderBuilder;
import com.opencsv.exceptions.CsvValidationException;
import lombok.Setter;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Setter
public class UserReader<T> extends AbstractItemCountingItemStreamItemReader<T> implements ResourceAwareItemReaderItemStream<T>, InitializingBean {
public static final Charset DEFAULT_CHARSET = Charset.defaultCharset();
private Resource resource;
private boolean noInput = false;
private Charset charset = DEFAULT_CHARSET;
private int linesToSkip = 0;
private boolean strict = true;
private char delimiter = ',';
private char quotedChar = '"';
private char escapeChar = '"';
private String[] headers;
private FieldSetMapper<T> fieldSetMapper;
private CSVReader csvReader;
private Resource resourceToRead;
@Override
public void afterPropertiesSet() throws Exception {
Assert.notNull(this.headers, "header is required");
Assert.notNull(this.fieldSetMapper, "FieldSetMapper is required");
}
@Override
public void setResource(Resource resource) {
this.resourceToRead = resource;
}
@Override
protected T doRead() {
if (noInput) {
return null;
}
if (csvReader == null) {
throw new ReaderNotOpenException("CSVReader is not initialized");
}
String[] line;
T mapField = null;
try {
line = csvReader.readNext();
if (Objects.isNull(line) || Arrays.stream(line).allMatch(Objects::isNull)) {
return null;
}
FieldSet fs = new DefaultFieldSet(line, headers);
mapField = fieldSetMapper.mapFieldSet(fs);
} catch (CsvValidationException | IOException | BindException e) {
//
log.error("error", e);
}
return mapField;
}
@Override
protected void doOpen() throws Exception {
//Assert.notNull(resource, "Input resource must be set");
noInput = true;
if(Objects.nonNull(resource) && !resource.exists()){
if(strict) {
throw new IllegalStateException("Input resource must exist (reader is in 'strict' mode): " + resource);
}
log.warn("Input resource does not exist " + resource.getDescription());
return;
}
if(Objects.nonNull(resource) && !resource.isReadable()){
if(strict){
throw new IllegalStateException("Input resource must be readable (reader is in 'strict' mode): " + resource);
}
log.warn("Input resource is not readable " + resource.getDescription());
}
var csvParserBuilder = new CSVParserBuilder().withSeparator(delimiter)
.withQuoteChar(quotedChar)
.withStrictQuotes(true);
if (quotedChar != escapeChar) {
csvParserBuilder.withEscapeChar(escapeChar);
}
csvReader = new CSVReaderBuilder(new FileReader(resourceToRead.getFile(), charset))
.withCSVParser(csvParserBuilder.build())
.withSkipLines(linesToSkip)
.build();
noInput = false;
}
@Override
protected void doClose() throws Exception {
if (Objects.nonNull(csvReader)) {
csvReader.close();
}
}
}
■/mybatis-example/src/main/java/com/example/demo/batch/user/UserJobLauncher.java
package com.example.demo.batch.user;
import java.util.HashMap;
import java.util.Map;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameter;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import lombok.RequiredArgsConstructor;
@EnableScheduling
@Component
@RequiredArgsConstructor
public class UserJobLauncher {
private final JobLauncher jobLauncher;
private final Job userJob;
private JobParameters jobParameters;
@Scheduled(cron="* 00 14 * * *")
public void launchUserJob() throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException {
Map<String, JobParameter> confMap = new HashMap<>();
confMap.put("time", new JobParameter(System.currentTimeMillis()));
this. jobParameters = new JobParameters(confMap);
this.jobLauncher.run(this.userJob, this.jobParameters);
}
}
■/mybatis-example/src/main/java/com/example/demo/batch/user/UserBatchConfig.java
package com.example.demo.batch.user;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.flow.FlowExecutionStatus;
import org.springframework.batch.core.job.flow.JobExecutionDecider;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import com.example.demo.dto.CsvUser;
import com.example.demo.entity.ShikokuOhenroUser;
@Configuration
@EnableBatchProcessing
public class UserBatchConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
@StepScope
public Resource userCsvResource(@Value("#{jobParameters['filePath']}") String filePath) {
return new FileSystemResource(filePath);
}
@Bean
public UserReader<CsvUser> csvUserReader(CsvUserMapper csvUserMapper) throws IOException {
UserReader<CsvUser> reader = new UserReader<>();
reader.setCharset(StandardCharsets.UTF_8);
reader.setStrict(true);
reader.setResource(new ClassPathResource("userdata.csv"));
reader.setLinesToSkip(1);
reader.setHeaders(new String[] {"last_name", "first_name", "rome_last_name", "rome_first_name", "ohenro_ids"});
reader.setFieldSetMapper(csvUserMapper);
reader.setDelimiter(',');
reader.setQuotedChar('"');
reader.setName("csvReader");
return reader;
}
@Bean
public Step step1(UserReader<CsvUser> userReader, UserWriter userWriter, UserProcessor userProcessor) {
return stepBuilderFactory.get("csvItemReaderStep")
.<CsvUser, ShikokuOhenroUser> chunk(10)
.reader(userReader)
.processor(userProcessor)
.writer(userWriter)
.build();
}
// @Bean
// public Job importUserJob(Step step1) {
// return jobBuilderFactory.get("importUserJob")
// .incrementer(new RunIdIncrementer())
// .start(step1)
// .build();
// }
@Bean
public Job userJob(Step step1) {
return jobBuilderFactory.get("userJob")
.incrementer(new RunIdIncrementer())
.start(step1)
.next(decider())
.on("Success")
.end()
.build()
.build();
}
@Bean
public JobExecutionDecider decider() {
System.out.println("Made it to the decider");
return (jobExecution, stepExecution) -> new FlowExecutionStatus("Success");
}
}
実行すると、CSVファイルのデータが9件なのですが、同じデータが342件分繰り返しINSERTされてしまう...
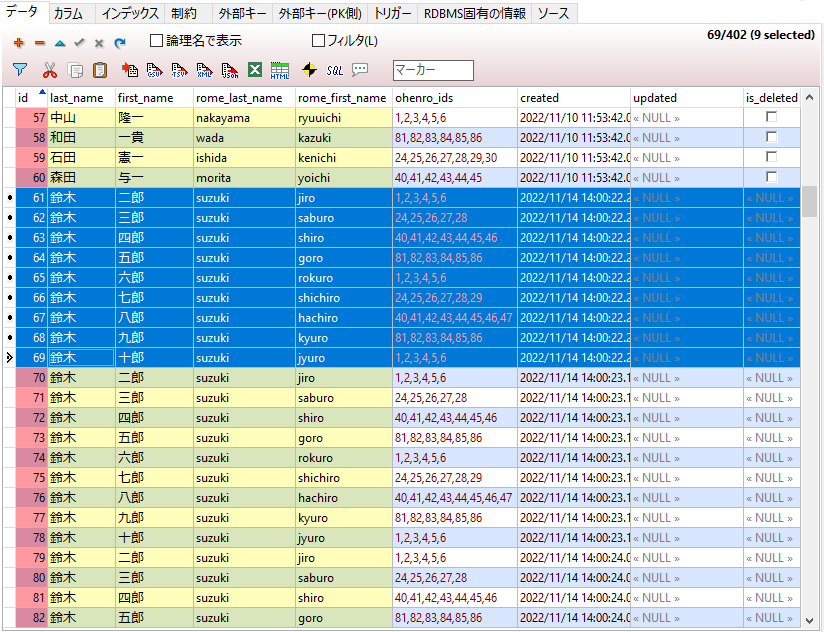
@Scheduledアノテーションで定期実行はできたっぽいけど、繰り返しINSERTされる理由が分からん...
制御できなさ過ぎて、実用に耐えない...
毎度モヤモヤ感が半端ない...
今回はこのへんで。