
⇧「推定」という「プロセス」を人間はいつ頃から行ってきたのか気になる年頃を迎えてますね、どうもボクです。
というわけで、「最尤推定」について調べてみました。
レッツトライ~。
最尤推定とは?
Wikipediaさん頼みますぜ。
最尤推定(さいゆうすいてい、英: maximum likelihood estimationという)や最尤法(さいゆうほう、英: method of maximum likelihood)とは、統計学において、与えられたデータからそれが従う確率分布の母数を点推定する方法である。

この方法はロナルド・フィッシャーが1912年から1922年にかけて開発した。
⇧ え、え~っと...
つまり、「標本(サンプル)」から「標本(サンプル)」 の従う「確率分布」の「母数」を「点推定」するってことらしいんですが、「母数」って?


⇧ ってな感じで「確率分布」毎に異なるものですと。
あと、「点推定」って?
点推定(てんすいてい、英: point estimation)とは、推計統計学において観測データに基づいて未知量に対する良好な推定(推定量)と見なせる値(統計量)を計算する手法とその結果を言う。平均値・中央値・最頻値などが用いられる。尤度関数の最頻値で推定する場合、事前分布がない場合を最尤推定、事前分布がある場合を最大事後確率推定という。
通常、推定値は記号の上に「^」をつける。
⇧ ってな感じで、『「観測データ」に基づいて「未知量」に対する良好な「推定(推定量)」と見なせる値(統計量)を計算する手法とその結果』ってあるんだけど、「平均値」「中央値」「最頻値」なんかを求めるってことになるらしい。
なので、
- 点推定
- 事前分布なしの場合
最尤推定 - 事前分布ありの場合
最大事後確率推定
- 事前分布なしの場合
ってことみたいね。
で、「最尤推定」は「事前分布」がないということですが、 「与えられたデータからそれが従う確率分布の母数を点推定する方法」なので、仮で「確率分布」を決めてあげる必要があり、この仮の「確率分布」を「論理分布」とか言ったりもするそうな。
「論理分布」としては、
とかが有名らしいですね。
最尤推定は具体的にどんなことをする?
「論理分布」を決めてあげて、その「論理分布」の「母数」を見つけてあげるってことらしいんだけど、具体的にどんなことすりゃ良いのよ?
ここで、「論理分布」っていうのは、「確率分布」であるので、
⇧ ってな感じで、「離散確率分布」であれ「連続確率分布」であれ、「関数」を持ってるわけですと。
ここで、「尤度関数」なるもののの説明を見てみると、
尤度関数(ゆうどかんすう、英: likelihood function)とは統計学において、ある前提条件に従って結果が出現する場合に、逆に観察結果からみて前提条件が「何々であった」と推測する尤もらしさ(もっともらしさ)を表す数値を、「何々」を変数とする関数として捉えたものである。また単に尤度ともいう。
⇧「最尤法」で用いられれますと。で、「最尤法」と「最尤推定」が同じリンク先になってることから、「最尤推定」でも「尤度関数」なるものが使われるのであろうと。
ここで、更に、「尤度方程式」というものの説明を見てみると、
尤度方程式(ゆうどほうていしき、英: likelihood equation)とは、統計学において、対数尤度関数の極値条件を与える方程式の事。統計的推定法の一つである最尤法において、尤度関数を最大化する最尤推定値を求める際に用いられる。
⇧『「尤度関数」を最大化する「最尤推定値」を求める際に用いられる』とあり、
X1, …, Xnを同一の確率分布に従う独立な確率変数とし、x=(x1,…, xn)Tをその観測値とする。ここで確率分布は確率密度関数f(x| θ)をもつ連続分布とする。但し、θ=(θ1, .., θp)Tはp個の分布のパラメータを表すものとし、パラメータ空間Θ ⊂ Rpに値を持つものとする。このとき、尤度関数L(θ,x)と対数尤度関数l(θ,x)は以下で定義される。


⇧「尤度関数」「対数尤度関数」というのは、「確率分布」の内の「連続確率分布」が持つ「確率密度関数」 を使って表すことができるらしいです。
2021年3月12日(金)追記:↓ ここから
「尤度関数」が何故に「総乗」の形になるのか?って同僚の方の疑問を聞いて、確かに何でなんだろう?って思ったので、調べてみる。
「連続確率分布」で考えた場合、「尤度関数」は「確率密度関数」で表せるっぽいって話だったので、まずは「確率密度関数」を調べてみますか。

![{\displaystyle \operatorname {E} [X]=\int _{-\infty }^{\infty }x\,f(x)\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/91e3fa656d4fd0a4c5b754f25203e105efd15ef9)
⇧ ってなっており、「期待値」はというと、
確率論において、確率変数の期待値(きたいち、英: expected value)とは、確率変数のすべての値に確率の重みをつけた加重平均である。確率分布に対して定義する場合は「平均」と呼ばれることが多い。
⇧ ってなっており、「加重平均」はというと、
データの値それぞれに不均等な重みがある場合は、単に相加平均をとるのでなく重みを考慮した平均をとるべきである。各値 xi に、重み wi がついているときの加重平均(重み付き平均)は

と定義される。
⇧ う~ん...何か「総乗」の形に繋がる気がしないな~...
ここで、「尤度関数」の説明に戻ってみると、

ここで x が確率変数、 θ が母数である。尤度関数は

ここで x は実験の観察値である。θ を定数として、 f(x | θ) を x の関数として見たときには、これは確率密度関数であり、逆に x を定数として θ の関数として見たときには、尤度関数である。
⇧ とありますと。つまり、「尤度関数」ってのは、「」の関数として考えなきゃならんのだと。
ここで、また「確率密度関数」に話を戻すと、
![{\displaystyle f(x;\mu ,\sigma ^{2})={\frac {1}{\sigma {\sqrt {2\pi }}}}\exp {\biggl [}-{\frac {1}{2}}\left({\frac {x-\mu }{\sigma }}\right)^{2}{\biggr ]}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95e4f8bda207562f7c90ef2f31b9e7dbf0bebdb1)
⇧ ってな感じで、「母数」で表現する方法がありますと。
更に、「尤度方程式 - Wikipedia」の説明の中での「尤度関数」は、「X1, …, Xnを同一の確率分布に従う独立な確率変数」で考えていたようなので、
多変量に関する確率密度関数
n個の連続型確率変数 X1, …, Xn について、同時確率密度関数と呼ばれる確率密度関数を定義することができる。この確率密度関数は n次元空間の定義域 D 中の n 個の変数 X1, …, Xn を用いて、下記のように書くことができる。

⇧ 上記の場合についての「尤度関数」を考えているのではないかと。
上記の数式が分かり辛いんですが、
個の確率変数
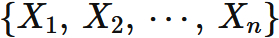
が互いに独立であり、 同一の期待値 と標準偏差 を持つ正規分布に従うと仮定する。 このとき、
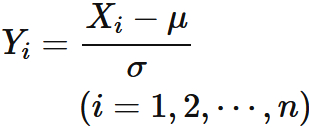
によって定義される 個の確率変数 は、 いずれも期待値が 、 標準偏差が の正規分布に従う (証明は「標準正規分布」を参考 )。
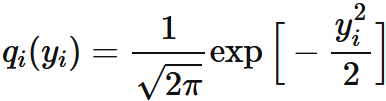
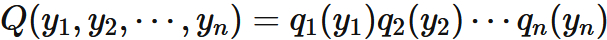
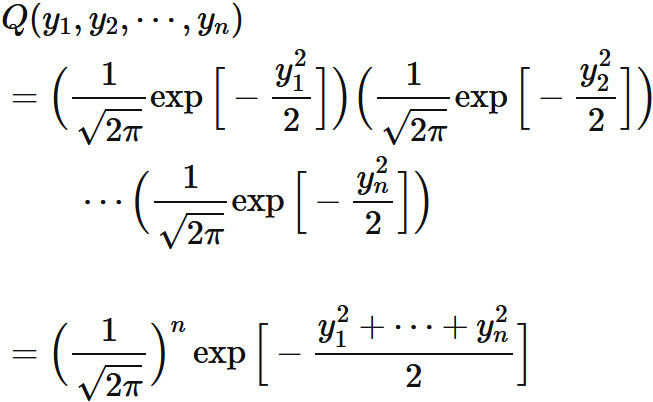
⇧ 上記サイト様の説明を見た感じ、「同時確率密度関数」の式が「総乗」の形で表せそうなので、「尤度関数」は「総乗」の形になるってことですかね。n回の「掛け算」をしてる形になってますしね。
2021年3月12日(金)追記:↑ ここまで
上記の式からも分かるように、
- 尤度関数
総乗の形 - 対数尤度関数
総和の形
ってことになるみたいですね。
⇧ すべての要素を「掛け算」するのが「総乗」で、すべての要素を「足し算」するのが「総和」ってことみたいですね。
一般的には、「総乗」の形は計算がしにくいから、「総乗」の形になってる式の「対数」を取って、「総和」の形の式にして計算するアプローチを取るらしい。
2021年3月12日(金)追記:↓ ここから
有識者の方にお聞きすることができ、「対数」をとって「総和」の形の式にしてアプローチすべき理由を教えていただきました。
ズバリ、「総乗」でアプローチする場合、「小数点」のような小さな値を何度も「掛け算」すると、コンピューターが扱えない桁数とかになってしまうということが発生しがちということのようです、なるほどですね。
勿論、「整数」とかでも同じく、何度も「掛け算」されると同様の問題が起こりがちってことかと。
演算結果の桁数がそれより多い場合、誤差が生じる。例えば、非常に大きな数に非常に小さな数(ゼロに近い数)を加算すると、有効数字の桁の範囲が違いすぎるため元の大きな数が得られる場合がある。
また、二進の浮動小数点表現の問題として、人類が多用する十進の小数表現でいわゆる「きりが良い」数との相性が悪い場合の存在がある。すなわち、0.75 のような十進でも二進でも有限小数で表せる数なら何の問題もない。しかし、例えば 0.1 という十進の小数は、二進では 0.000110011... というように無限小数になる。
⇧ 大きな値を扱う際は、いろいろ問題があるあるですかね...
2021年3月12日(金)追記:↑ ここまで
で、「尤度方程式」の説明の続きを見ていくと、


⇧「尤度関数」の「対数」を取った「対数尤度関数」を「最大化」する「θ」が「最尤推定値」ということになるのですと。
ただ、「離散確率分布」についての場合は?
を離散確率分布関数でなく確率密度関数として考えれば、上の定義は連続確率分布にも当てはまる。

⇧「最尤推定」の説明では、「離散確率分布関数」の例を上げてるようなので、「最尤推定」は、「論理分布」が
- 離散確率分布
- 連続確率分布
のどちらでも使えますよということみたいですね。
とはいえ、イメージ湧かないっす...
まぁ、「論理分布」を決めて、「確率分布」を変形して「尤度関数」を作って、「尤度関数」の「対数」をとって「対数尤度関数」を作って、「対数尤度関数」が最大となるというのは「最尤推定値」が最大になる「θ」(「分布」の「パラメータ」のことなので「母数」)を見つけるということで、最大となる「最尤推定値」を求めることで「θ」(「分布」の「パラメータ」のことなので「母数」)が判明するってこと、それが「最尤推定」ってことなのは分かったんだけども、いまいち、どうすることで「θ」が決まるのよ?ってなりますと。
そこで、
⇧ 上記サイト様が分かりやすいです。
ここで、「確率分布」ってのは「パラメータ」の値によって形が変わるわけなんですが、「パラメータ」ってのは「確率分布」によって異なりますと。
上記サイト様の例では、「論理分布」として「正規分布」である場合の「最尤推定」を説明してくださってますが、「σ(標準偏差)」を固定してるとあるので、「μ(平均値)」を求める「母数」としてますと。(「正規分布」の「母数」は、「σ(標準偏差)」と「μ(平均値)」になるので)
「正規分布」で「最尤推定」で「μ(平均値)」を求める場合は、

⇧ 上記サイト様にありますように、「論理分布(今回だと「正規分布」)」の山(「対数尤度関数」の値が最大になる)が最大になる部分を探せば良いのですと。
なので、「総当たり」的に「μ(平均値)」の値を変更していって、「対数尤度関数」の値の候補を得て、各「μ(平均値)」の時の「対数尤度関数」の値(「最尤推定値」)を相対的に比較して「最尤推定値」が最大となる時の「母数(今回だと『論理分布』として『正規分布』を選択して、『σ(標準偏差)』が固定値なので、『μ(平均値)』が求めるべき『母数』)」を見つけるってことですかね。
実際に試してみる
というわけで、「論理分布」が「正規分布」として「σ(標準偏差)」が固定されてる場合に、「最尤推定」を実施してみようかと。
⇧ 上記サイト様の丸パクリなのですが、「RStudio」で試してみました。 (事前に「R」もインストール済みです。)
「RStudio」を起動して、 「File」>「New File」>「R Script」を選択。

今回、事前に分かってる情報から、「標本」の「平均値」が「5.418」だったので、以下のようにコーディングしてみました。(「μ(平均値)」を、0.5刻みで「5.5」までの「最尤推定値」をそれぞれザックリ算出)
# 画像保存先
setwd("C:/Users/Toshinobu/Desktop/soft_work")
# パラメータ
dSd <- 2.0 # 標準偏差
dN <- 10 # 標本サイズ
# 標本データ
dVal <- c(5.52, 4.79, 4.26, 5.74, 5.49, 6.67, 5.28, 5.37, 5.32, 5.74)
# グラフの横軸は、-5~15
# グラフの縦軸は、0.1刻み
x <- seq(-5, 15, by=0.1)
# 確率密度関数・標本と尤度の関係をグラフ化して画像として出力
for(m in 1:11){
dMu_i <- m*0.5
dSd_i <- dSd
png(sprintf("01_尤度_m%0.2d-s%0.2d.png", dMu_i*10, dSd_i*10), height=320, width=640, res=96)
par(mar=c(3, 3, 1, 1)) #余白設定
par(mgp=c(2, 0.7, 0)) #グラフ枠と軸との間隔設定
par(xaxs = "i") #データ範囲とグラフの範囲(X軸)
y <- dnorm(x, dMu_i, dSd_i)
plot(x, y, lty=1, type="l", lwd=2, ylim=c(0, 0.4), xlab="x", ylab="Probability density")
dmy <- sapply(dVal, function(x){lines(c(x, x), c(0, dnorm(x, dMu_i, dSd_i)), col=gray(0.6))})
points(dVal, rep(0:0, length=length(dVal)), col="red", pch=16)
dLH <- prod(dnorm(dVal, dMu_i, dSd_i))
legend("topleft", sprintf("L(%0.1f,%0.1f)=%0.2e", dMu_i, dSd_i, dLH), lty=0)
dev.off()
}
⇧ コードを実行していきます。(「RStudio」の「Code」>「Run Region」>「Run All」で一括実行できるっぽいです)
指定した「ディレクトリ」に「グラフ(今回は『正規分布』)」の「画像」が出力されてます。

画像を確認してみると、
「論理分布」として「正規分布」で考えているので、「μ」は「平均」の値、「σ」は「標準偏差」の値です。
■L(μ=0.5, σ=2.0)、 最尤推定値=4.74e-21

■L(μ=1.0, σ=2.0)、 最尤推定値=1.62e-18

■L(μ=1.5, σ=2.0)、 最尤推定値=2.97e-16

■L(μ=2.0, σ=2.0)、 最尤推定値=2.91e-14

■L(μ=2.5, σ=2.0)、 最尤推定値=1.53e-12

■L(μ=3.0, σ=2.0)、 最尤推定値=4.28e-11

■L(μ=3.5, σ=2.0)、 最尤推定値=6.44e-10

■L(μ=4.0, σ=2.0)、 最尤推定値=5.18e-09

■L(μ=4.5, σ=2.0)、 最尤推定値=2.23e-08

■L(μ=5.0, σ=2.0)、 最尤推定値=5.14e-08

■L(μ=5.5, σ=2.0)、 最尤推定値=6.34e-08

⇧ というわけで、「母数」が変わることで、「確率分布(今回は『正規分布』)」が変わっていく様子が分かりましたと。(「σ(標準偏差)」が固定なので、「 (分散)」が変わらないので「正規分布」の横幅は変わらないし、「標本サイズ」も固定なので、「正規分布」の山の高さとかも変わらないかと。「正規分布」が形を変えずに左から右へ流れていくかのように見えますね)
今回は「グラフ(今回は『正規分布』)」で「μ(平均値)」と「最尤推定値」の関係を見たかったので、大雑把な「μ(平均値)」の刻みで実施しておるため、正確ではないものの結果から、「μ(平均値)」が「5.5」の時が一番「最尤推定値」の値が大きそうであるので、おそらく「標本」の「平均値」の値「5.418」が、「母集団」の「μ(平均値)」としても妥当ではないかと推測できそうですかね。
というわけで、今度は「グラフ(今回は『正規分布』)」を出力しない代わりに、「μ(平均値)」の刻みを細かくしてみました。(どれぐらい値を細かく見るのか基準は分からないので適当になってます...有識者の方が身近におられる場合は有識者の方に確認しましょう)
# 画像保存先
# setwd("C:/Users/Toshinobu/Desktop/soft_work")
# パラメータ
dSd <- 2.0 # 標準偏差
# 標本データ
dVal <- c(5.52, 4.79, 4.26, 5.74, 5.49, 6.67, 5.28, 5.37, 5.32, 5.74)
dN <- length(dVal) # 標本サイズ
# グラフの横軸は、-5~15
# グラフの縦軸は、0.1刻み
x <- seq(-5, 15, by=0.1)
# 確率密度関数・標本と尤度の関係をリスト化
y_list <- c() # 確率密度関数の値を格納用のベクトル
dLH_list <- c() # 最尤推定値を格納用のベクトル
dMu_list <- c() # μ(平均値)を格納用のベクトル
m <- min(dVal)
# μ(平均値)を0.01ずつ確認
while(m <= max(dVal)){
m <- m + 0.01
dMu_i <- m # μ(平均値)
dSd_i <- dSd # 標準偏差
# 確率密度関数
y <- dnorm(x, dMu_i, dSd_i)
# 尤度関数に変換して、最尤推定値を取得
dLH <- prod(dnorm(dVal, dMu_i, dSd_i))
# それぞれの結果をベクトルに格納
dMu_list <- c(dMu_list, dMu_i)
y_list <- c(y_list, y)
dLH_list <- c(dLH_list, dLH)
}
# key、valueの形のリストで、データを保持
dMu_dLH_list <- setNames(dLH_list, dMu_list)
# 確率密度関数の値の最大値を確認
print(max(y_list))
# 最尤推定値の値の最大値を確認
print(max(dLH_list))
# 最も大きい最尤推定値の際のμ(平均値)を確認
print(names(dMu_dLH_list)[dMu_dLH_list == max(dLH_list)])
⇧ 上記のようなコーディングになりました。

⇧ 上記の資料によりますと、「prod()」関数は、「総乗」ということらしいので、今回のコーディングでは「尤度関数」で最大となる「最尤推定値」を求めて、その際の「母数(今回は『正規分布』でトライしてて、且つ、『σ(標準偏差)』が固定なので、『μ(平均値)』が求める『母数』)」を求めるってことをしてますと。
そしたらば、「RStudio」で変更を保存して、「Code」>「Run Region」>「Run All」を選択で、一括でコードが実行できるっぽいです。

実行結果が「RStudio」の「Console」に表示されます。

⇧ 見た感じ「最尤推定値」が一番大きくなる「μ(平均値)」は「5.41999999999998」ということみたいなので、「標本(コード上では『標本データ』のこと)」の「平均値」である「5.418」とほぼ近似してるという感じでしょうか。
「対数尤度関数」でアプローチすると、
# 画像保存先
# setwd("C:/Users/Toshinobu/Desktop/soft_work")
# パラメータ
dSd <- 2.0 # 標準偏差
# 標本データ
dVal <- c(5.52, 4.79, 4.26, 5.74, 5.49, 6.67, 5.28, 5.37, 5.32, 5.74)
dN <- length(dVal) # 標本サイズ
# グラフの横軸は、-5~15
# グラフの縦軸は、0.1刻み
x <- seq(-5, 15, by=0.1)
# 確率密度関数・標本と尤度の関係をリスト化
y_list <- c() # 確率密度関数の値を格納用のベクトル
dLH_list <- c() # 最尤推定値を格納用のベクトル
dMu_list <- c() # μ(平均値)を格納用のベクトル
m <- min(dVal)
# μ(平均値)を0.01ずつ確認
while(m <= max(dVal)){
m <- m + 0.01
dMu_i <- m # μ(平均値)
dSd_i <- dSd # 標準偏差
# 確率密度関数
y <- dnorm(x, dMu_i, dSd_i)
# 対数尤度関数に変換して、最尤推定値を取得
dLH <- sum(log(dnorm(dVal, dMu_i, dSd_i)))
# それぞれの結果をベクトルに格納
dMu_list <- c(dMu_list, dMu_i)
y_list <- c(y_list, y)
dLH_list <- c(dLH_list, dLH)
}
# key、valueの形のリストで、データを保持
dMu_dLH_list <- setNames(dLH_list, dMu_list)
# 確率密度関数の値の最大値を確認
print(max(y_list))
# 最尤推定値の値の最大値を確認
print(max(dLH_list))
# 最も大きい最尤推定値の際のμ(平均値)を確認
print(names(dMu_dLH_list)[dMu_dLH_list == max(dLH_list)])
⇧ で実行した場合、

⇧「最尤推定値」の桁数は抑えられそうですかね。
というわけで、「最尤推定」は、「点推定」とあるように、最適な「1地点」を求めるってことみたいですね。
ちなみに、「点推定」というがあるなら、「点」でなく「区間」で「推定」する方法もあるんじゃないの?って思った方、流石です!
「区間推定(Interval estimation)」ってものがありますと。
In statistics, interval estimation is the use of sample data to calculate an interval of possible values of an unknown population parameter; this is in contrast to point estimation, which gives a single value. Jerzy Neyman (1937) identified interval estimation ("estimation by interval") as distinct from point estimation ("estimation by unique estimate"). In doing so, he recognized that then-recent work quoting results in the form of an estimate plus-or-minus a standard deviation indicated that interval estimation was actually the problem statisticians really had in mind.
⇧『1937年に、Jerzy Neymanさんという方が「点推定」とは異なるものとして「区間推定」を識別』って言っておりますね。
というわけで、「区間推定」についても時間があればまとめていきたいところですね。
数学的な要素が入ってくると、辛いですね...
毎度、モヤモヤ感が半端ない...
今回はこのへんで。