
修理できなくなった物、耐用年数を経過し廃棄された物、物流倉庫解体による物流機器の処分などで放出された木製パレットを家具などとして再利用する動きがある。
⇧ 大量の荷物を運搬するのに便利なパレットですが、再利用とかされてたんですね。
個々の荷物の中身とかの検品とかって話になってくると、やっぱり人手を介しての目視とかになるんですかね?
By the way、Java 9から、
- Java SE(Java Platform Standard Edition)
- JDK(Java Development Kit)
のドキュメントがハッキリ分かれていたことを最近知りました、どうもボクです。
これまで「Java 9」とか「JDK 9」とかどっちも同じ意味のような感じで言ってましたけど、 明確に意識してかないと駄目ってことですね、反省。
というわけで、今回もJavaについてです。
レッツトライ~。
java.lang.ObjectのhashCode()メソッドの値って何に使われてるのか
その前に、java.lang.Objectの「hashCode()」メソッドの値って何に使われてるのか?
To answer this question we must understand which are the possible locations of the mark word (that contains the identity hash) depending on the lock state of the object. The transitions are illustrated in this diagram from the HotSpot Wiki:

https://srvaroa.github.io/jvm/java/openjdk/biased-locking/2017/01/30/hashCode.html
⇧ ってあるように、「HotSpot Wiki」に情報があるらしい。
で、上図の説明として、
One of the major strengths of the Java programming language is its built-in support for multi-threaded programs. An object that is shared between multiple threads can be locked in order to synchronize its access. Java provides primitives to designate critical code regions, which act on a shared object and which may be executed only by one thread at a time. The first thread that enters the region locks the shared object. When a second thread is about to enter the same region, it must wait until the first thread has unlocked the object again.
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
In the Java HotSpot™ VM, every object is preceded by a class pointer and a header word. The header word, which stores the identity hash code as well as age and marking bits for generational garbage collection, is also used to implement a thin lock scheme [Agesen99, Bacon98]. The following figure shows the layout of the header word and the representation of different object states.
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
⇧ ってな感じで、JVM上で管理されてる全てのオブジェクトについて、
- class pointer
- header word
ってのがセットになってるらしく、この「header word」の一部に「hashCode()」メソッドで生成された「hash code」が利用されているということみたい。
マルチスレッドな処理で、複数のオブジェクトを制御する時の「syncronaized」なんかの仕組みに使われているそうな。
class pointerって?
これといった情報がヒットしないので、推測するしかないのですが、Oracleさんの「JDK 8によるJVMの変更」のPDFの資料を確認したところ、「class pointer」って言葉が出てきました。
そのPDFの資料によると、

⇧ って感じで、「PermGen」がお亡くなりになりましたと。
「PermGen」って何よ?

⇧ って感じで、「PermGen」は「クラスのメタデータ」を格納してたんだそうな。
で、PDFの後述の説明から推測するに、以下は、「ヒープ」の話じゃないかと思われます。
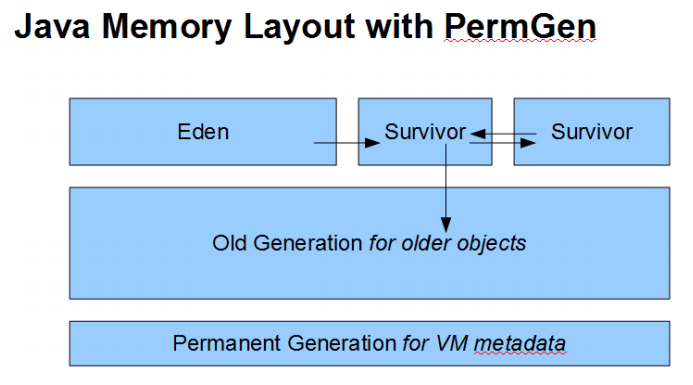
⇧「Permanent Generation for VM metadata」ってところが「PermGen」ってことみたいね。
ちなみに「ヒープ」は、

⇧「JVM Memory」の内の1つみたいですね。なので、「.java」ファイルが「javac」などでコンパイルされて「.class」ファイルになった後に、JVM(Java Virtual Machine)に読み込まれてからの話になるのかな。
はい、脱線しましたが、そんな「ヒープ」の中の構成を改良してパフォーマンスをアゲアゲでいきましょうってことで、

⇧「Commpressed Oops」ってものの導入と、
さらに、

⇧「Klass ポインター」なるものを圧縮しましょう、ってことで用意されたのが「Compressed Class Pointer Space」というものらしく、はい、ようやく「class pointer」が登場しました。
って言うか、「Klass」って何よ?
ランタイム時にインスタンスが生成されると、そのインスタンス用にヒープ領域からメモリが割り当てられます。それを参照するための情報が oop です。この領域には例えばインスタンスフィールドであったり配列なら長さや要素が格納されます。
oop は後述の圧縮という処理を考えなければその領域へのポインタと言ってしまっていいはずです。
oopDesc
in src/hotspot/share/oops/oop.hpp
oopDesc のはじめには mark と klass という情報が入ります。それぞれのサイズは 64 bit 環境ならば mark が 8 bytes、klass は UseCompressedOops ならば 4 bytes, そうでなければ 8 bytes になります。
Klass
in src/hotspot/share/oops/klass.hpp
⇧ ってことみたい。Hotspot JVM(Java Virtual Machine)上で、Javaのオブジェクトを管理するための仕組みが「OOP」というらしく、「OOP」の仕組みを構成する1要素が「Klass」ってことみたいね。
「OOP」は、
HotSpotの専門用語である"OOP"("Ordinary Object Pointer")は、オブジェクトに対する管理ポインタを表します。 これは通常、ネイティブ・マシンのポインタと同じサイズになります。つまり、LP64システムでは64ビットです。 ILP32システムでは、最大ヒープ・サイズは4GBよりやや少ない程度です。これは多くのアプリケーションにとって十分ではありません。 一方、LP64システムでは、実行時のヒープは対応するILP32システムの約1.5倍必要となることもあります(どちらのモードも同じ状況と仮定した場合)。 これは、管理ポインタのサイズが増大することが原因となっています。 メモリのコストは低いですが、最近では帯域幅およびキャッシュが不足しているため、4GBという制限を解決するためだけにヒープ・サイズが大幅に増加してしまうのは厳しいところです。
https://www.oracle.com/technetwork/jp/articles/java/compressedoops-427542-ja.html
⇧「Ordinary Object Pointer」って言うみたいね。
で、「JDK 8」以前だと、
圧縮されるOOPの種類
ILP32モードのJVMの場合、またはLP64モードでUseCompressedOopsフラグをオフにした場合、すべてのOOPはネイティブ・マシンのワード・サイズとなります。
UseCompressedOopsがtrueの場合は、ヒープ内の次のOOPが圧縮されます。
Javaクラスを管理するHotspot VMのデータ構造は圧縮されません。 これらのデータ構造は一般的に、Permanent Generation(PermGen)として知られるJavaヒープ領域に存在します。
https://www.oracle.com/technetwork/jp/articles/java/compressedoops-427542-ja.html
⇧「PermGen」に存在したデータは圧縮されなかったようですと。
脱線しましたが、で、「ヒープ」の構成が改良された結果が以下ですと。

⇧「Permanent Generation for VM metadata」ってものが無くなって、
- Metaspace
- Compressed Class space
って感じで、2つのスペースが用意されましたと。この2つを合わせて「Compressed Class Pointer Space」ってことなのかな?
「OOP(Ordinary Object Pointer)」は「Klass」を持つし、「JDK 8」で「ヒープ」の構成が変わったことにより、

⇧「Klass」のデータもコンパクトになりましたってことなんですかね。
で、長々と脱線してきましたが、「Class Pointer」って言うのは、
- Compressed Class Pointer Space
- Metaspace
- Compressed Class Space
「Compressed Class Pointer Space」のことを指すんじゃないかと。
header wordって?
おそらく、これも推測になってしまうのですが、
「In the Java HotSpot™ VM, every object is preceded by a class pointer and a header word. The header word, which stores the identity hash code as well as age and marking bits for generational garbage collection」
って言う説明が、
⇧「OpenJDK」のWikiに記載されてるので、「OOP(Ordinary Object Pointer)」が管理してるものであろうと考えて、
オブジェクト・ヘッダーのレイアウト
オブジェクト・ヘッダーは、ネイティブサイズのmarkワード、klassワード、32ビットのlengthワード(オブジェクトが配列の場合)、32ビットのgap(配置ルールで必要な場合)、さらには0個以上のインスタンス・フィールド、配列要素、またはメタデータ・フィールドで構成されています。 (興味深いトリビア: Klassメタオブジェクトには、klassワードのすぐ後にC++ vtableが含まれています。)
gapフィールドが存在すると、多くの場合、インスタンス・フィールドの保存に使用できます。
UseCompressedOopsがfalseの場合(かつ常にILP32システムにある場合)、markとklassは両方ともネイティブ・マシン・ワードです。 配列については、gapはLP64システム上では必ず存在します。また、ILP32システム上では64ビット要素の配列でのみ存在します。
UseCompressedOopsがtrueの場合、klassは32ビットです。 非配列の場合は、klassのすぐ後にgapフィールドがあり、配列の場合はklassのすぐ後にlengthフィールドが保存されます。
https://www.oracle.com/webfolder/s/delivery_production/docs/FY14h1/doc6/C2-JavaDay-304328.pdf
⇧「オブジェクト・ヘッダー」のことを指しているんではないかなと。
って言うか、
⇧「OpenJDK」の「HotSpot」の用語集でも「object header」は出てくるけど「header word」は出てこないんよね...
情報が錯綜してるので何とも言えないけど、「header word」は「object header」のようなものっていう認識で進んでみますかね。
equals(Object obj)、hashCode()は何故@Overrideする必要があるのか?
長々と脱線しましたが、ようやく本題。
Javaで独自のクラスを作る時に、以下の2つのメソッドを@Overrideするようにって、情報が一般的かなとは思われるんですが、
- java.lang.Object
- equals(Object obj)
- hashCode()
何で?って思いません?
自分は、何故に@Overrideするのか気になってたのですが、とりあえずそういうもんなんだ、っていう理解で日々の業務に忙殺されていたこともあり、改めて考えてみると、何で@Overrideするなんてめちゃんこ面倒くさいことしないといけないんだっけ?って思い始めてしまって、ご飯がどんぶり1杯ぐらいしか食べれなくなったぐらい胃が小さくなったな~、という気持ちになったので、@Overrideする理由を調べてみました。
まずは、「java.lang.Object#equals(Object obj)」メソッドのjavadoc(ドキュメント)を確認してみます。
public boolean equals(Object obj)
equalsメソッドは、null以外のオブジェクト参照での同値関係を実装します。
- 反射性(reflexive): null以外の参照値
xについて、x.equals(x)はtrueを返します。 - 対称性(symmetric): null以外の参照値
xおよびyについて、y.equals(x)がtrueを返す場合に限り、x.equals(y)はtrueを返します。 - 推移性(transitive): null以外の参照値
x、y、およびzについて、x.equals(y)がtrueを返し、y.equals(z)がtrueを返す場合、x.equals(z)はtrueを返します。 - 一貫性(consistent): null以外の参照値
xおよびyについて、x.equals(y)の複数の呼出しは、このオブジェクトに対するequalsによる比較で使われた情報が変更されていなければ、一貫してtrueを返すか、一貫してfalseを返します。 - null以外の参照値
xについて、x.equals(null)はfalseを返します。
⇧ ってな感じで、「反射性」「対称性」「推移性」「一貫性」の4つの特性と「null」に対する挙動が実装されている必要があるらしいのですが、
Objectクラスのequalsメソッドは、もっとも比較しやすいオブジェクトの同値関係を実装します。つまり、null以外の参照値xとyについて、このメソッドはxとyが同じオブジェクトを参照する(x == yがtrue)場合にだけtrueを返します。
⇧ java.lang.Object#equals(Object obj)メソッドは、何故かは知らんけど、「反射性」「対称性」「推移性」「一貫性」の4つの特性を全部満たしていないらしい、少なくとも「推移性」は満たして無さそう...
なので、オブジェクト参照の同値関係を比較するためには、 java.lang.Object#equals(Object obj)メソッドを@Overrideせざるを得ないんだけど、@Overrideする場合は、
通常、このメソッドをオーバーライドする場合は、hashCodeメソッドを常にオーバーライドして、等価なオブジェクトは等価なハッシュ・コードを保持する必要があるというhashCodeメソッドの汎用規約に従う必要があることに留意してください。
⇧ もれなく、java.lang.Object#hashCode()メソッドを@Overrideすることが必須なんですな。
つまり、独自のクラスとか作る場合で、そのクラスをインスタンス化してできたオブジェクト同士が同値等価であるかを確認するようなことが起こりえる場合は、
- java.lang.Object
- equals(Object obj)
- hashCode()
を@Overrideしといてくださいよ、ってことみたいね。
ちなみに、java.lang.Object#hashCode()メソッドのjavadoc(ドキュメント)を見てみると、
public int hashCode()
オブジェクトのハッシュ・コード値を返します。 このメソッドは、HashMapによって提供されるハッシュ表などの、ハッシュ表の利点のためにサポートされています。
https://docs.oracle.com/javase/jp/11/docs/api/java.base/java/lang/Object.html#hashCode()
hashCodeの一般的な規則は次のとおりです。
- Javaアプリケーションの実行中に同じオブジェクトに対して複数回呼び出された場合は常に、このオブジェクトに対する
equalsの比較で使用される情報が変更されていなければ、hashCodeメソッドは常に同じ整数を返す必要があります。 ただし、この整数は同じアプリケーションの実行ごとに同じである必要はありません。 equals(Object)メソッドに従って2つのオブジェクトが等しい場合は、2つの各オブジェクトに対するhashCodeメソッドの呼出しによって同じ整数の結果が生成される必要があります。equals(java.lang.Object)メソッドに従って2つのオブジェクトが等しくない場合は、2つの各オブジェクトに対するhashCodeメソッドの呼出しによって異なる整数の結果が生成される必要はありません。 ただし、プログラマは、等しくないオブジェクトに対して異なる整数の結果を生成すると、ハッシュ表のパフォーマンスが向上する可能性があることに注意するようにしてください。
https://docs.oracle.com/javase/jp/11/docs/api/java.base/java/lang/Object.html#hashCode()
⇧ ってあって、例えば、2つのオブジェクトでjava.lang.Object#hashCode()メソッドの返す値が違っちゃうと、java.lang.Object#equals(Object obj)メソッドで等しいとあっても、同値にならないってことみたい。
クラスObjectによって定義されたhashCodeメソッドは、可能なかぎり、異なるオブジェクトに対して異なる整数を返します。 (hashCodeは、ある時点におけるオブジェクト・メモリー・アドレスの関数として実装されても実装されなくてもよい。)
https://docs.oracle.com/javase/jp/11/docs/api/java.base/java/lang/Object.html#hashCode()
⇧ java.lang.Object#equals(Object obj)メソッドは、「可能な限り、異なるオブジェクトに対して異なる整数を返します。」っていう何とも不安なjavadoc(ドキュメント)の記載になってますと...
さらに、一番納得いかないのは、javadoc(ドキュメント)と実際の内容が一致してないというね。
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined
* by class {@code Object} does return distinct integers for
* distinct objects. (The hashCode may or may not be implemented
* as some function of an object's memory address at some point
* in time.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
@HotSpotIntrinsicCandidate
public native int hashCode();
⇧ そうなんですよ、「native修飾子」なるものがしれっと実装のほうには記述されてるというね、この痴れ者が!って思いますよね。
まぁ、Javaで「JNI(Java Native Interface)」とか実装したことがある方はご存知かもしれませんが、そうですね、Java以外の言語で実装されたプログラムを呼んでるってことですね、それが「ネイティブコード」デスYO!
そうは言っても、「ネイティブコード」なんて気にする機会なんて訪れることはないから世の中は平和に満ち溢れているでしょでしょう...って思っていたら、
⇧ 上記サイト様でネイティブコードをデバックされておられました、恐るべし。
絶望感に打ち震えたところで、独自クラスを作成する際、そのクラスのオブジェクトで同値等価を判定したい場合なんかは、
- java.lang.Object
- equals(Object obj)
- hashCode()
の@Overrideを忘れずにってことですかね。
どんな風に、@Overrideするかは、
⇧ 上記サイト様が参考になるかと。
今回はこのへんで。