
⇧ 悪用する輩がおるせいで、余計な仕事が増えるんですかね...
IN句よりEXISTS句のほうが高速と言う話を聞くけれど
SQLのIN句とEXISTS句どっち使ったら高速かと言う話ですが、
The short answer, post-Oracle 9i is:
Both are pretty much the same!
⇧ Oracle Database 9i以降のバージョンであれば、ほとんど変わらないらしい。
ただ、
⇧ 状況に依りけりという話もあり...
パフォーマンスチューニングにおいて、すべての副問い合わせを EXISTS に変更するという Tips は誤った認識である。ただし、EXIST による相関副問い合わせは オプティマイザ にとってチューニングしやすいのは パフォーマンス・チューニングマニュアルから確かな事である。
- 副問い合わせの選択性が高い*1場合にはIN (<副問い合わせ>)
- 親問い合わせの選択性が高く、副問い合わせのコストも低い場合には、EXISTS( <副問い合わせ> )
を選択する。
*1 検索結果レコード数が少ない
⇧ やっぱり、EXISTSを使っておいた方が良いのかな?
The EXISTS clause is much faster than IN when the subquery results is very large. Conversely, the IN clause is faster than EXISTS when the subquery results is very small.
⇧ 副問い合わせ(サブクエリ)の結果が大量レコードになる場合はEXISTS句が高速で、副問い合わせ(サブクエリ)の結果が少量レコードになる場合はIN句が高速になるらしい。
で、肝心の大量に該当するのか少量に該当するのかのレコード量の基準を知りたいんだが...
話は変わり、statckoverflowによりますと、
IN picks the list of matching values. EXISTS returns the boolean values like true or false. Exists is faster than in.
Example
IN
select ename from emp e where mgr in(select empno from emp where ename='KING');
EXISTS
select ename from emp e
where exists (select 1 from emp where e.mgr = empno and ename = 'KING'); ⇧ そもそも、返す結果が異なりますと。
試してみた。
SELECT * FROM USERS
WHERE user_id
IN (
SELECT us.USER_ID FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);

SELECT * FROM USERS
WHERE EXISTS (
SELECT * FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);

EXISTS句はtrueかfalseを返すということで、いくら絞り込みの条件を記述したところでその条件で絞れるということではないということなんですかね?
と思ったら、
oracle.programmer-reference.com
⇧ DELETEする時は、EXISTS句の絞り込んだ条件で削除してくれるらしい、紛らわし過ぎる...
で、結局のところ、DELETEする時にどれが早いのか?
⇧ う~む、そもそも、IN句とEXISTS句の比較で話を考えてたけども、EXISTS句が高速なわけではないというコペルニクス的展開に震える...
できる限りINNER JOINを使えるならINNER JOINを使うのが良い模様。
ただ、
⇧ DELETE文の場合は、EXISTS + INNER JOINを利用していく感じになるんかね?
結局のところ、ベストプラクティスが分からん...
実行計画は、手動SQLチューニングの主要な診断ツールです。たとえば、計画を表示して、オプティマイザが想定どおりの計画を選択しているかどうかを確認したり、表での索引作成の効果を特定したりすることができます。
⇧ 実行計画を取得したりして解析せなアカンのかな?
EXPLAIN PLAN FORで実行するSQLは、実際にSQLの処理は実行されないということで、試しに実行計画を取得してみたのだけど、
■IN句を使ったSELECT文の実行計画
EXPLAIN PLAN FOR SELECT * FROM USERS
WHERE user_id
IN (
SELECT us.USER_ID FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());

PLAN_TABLE_OUTPUT
Plan hash value: 4265531122
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 46 | 3 (34)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 46 | 3 (34)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 46 | 3 (34)| 00:00:01 |
| 3 | VIEW | VW_NSO_1 | 1 | 15 | 1 (0)| 00:00:01 |
| 4 | HASH UNIQUE | | 1 | 28 | | |
| 5 | NESTED LOOPS SEMI | | 1 | 28 | 1 (0)| 00:00:01 |
| 6 | INDEX FULL SCAN | SYS_C007982 | 3 | 42 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN | SYS_C007959 | 1 | 14 | 0 (0)| 00:00:01 |
|* 8 | INDEX UNIQUE SCAN | SYS_C007959 | 1 | | 0 (0)| 00:00:01 |
| 9 | TABLE ACCESS BY INDEX ROWID| USERS | 1 | 31 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("US"."USER_ID"="AD"."USER_ID")
filter(TO_NUMBER("US"."USER_ID")=1)
8 - access("USER_ID"="USER_ID")
Note
-----
- this is an adaptive plan
■EXISTS句を使ったSELECT文の実行計画
EXPLAIN PLAN FOR SELECT * FROM USERS
WHERE EXISTS (
SELECT * FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
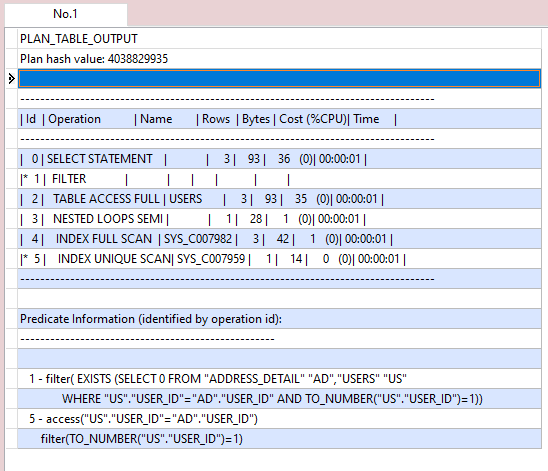
PLAN_TABLE_OUTPUT
Plan hash value: 4038829935
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 93 | 36 (0)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | TABLE ACCESS FULL | USERS | 3 | 93 | 35 (0)| 00:00:01 |
| 3 | NESTED LOOPS SEMI | | 1 | 28 | 1 (0)| 00:00:01 |
| 4 | INDEX FULL SCAN | SYS_C007982 | 3 | 42 | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN| SYS_C007959 | 1 | 14 | 0 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT 0 FROM "ADDRESS_DETAIL" "AD","USERS" "US"
WHERE "US"."USER_ID"="AD"."USER_ID" AND TO_NUMBER("US"."USER_ID")=1))
5 - access("US"."USER_ID"="AD"."USER_ID")
filter(TO_NUMBER("US"."USER_ID")=1)
⇧ う~む、レコード数が少ないせいか、EXISTS句のほうがCostが高くなってるのは分かるのだけど、単純にTimeを全部合計して比較すれば良いのか分からんのだけど、
EXISTS句のほうが処理が高速って考えて良いんですかね?

⇧ Timeは予想処理時間ということで、処理時間の見積りってことみたいね。
DELETE文の実行計画を取得してみた。
■IN句でDELETEする実行計画
EXPLAIN PLAN FOR DELETE FROM USERS
WHERE user_id
IN (
SELECT us.USER_ID FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
PLAN_TABLE_OUTPUT
Plan hash value: 3668362358
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 29 | 2 (50)| 00:00:01 |
| 1 | DELETE | USERS | | | | |
| 2 | NESTED LOOPS | | 1 | 29 | 2 (50)| 00:00:01 |
| 3 | VIEW | VW_NSO_1 | 1 | 15 | 1 (0)| 00:00:01 |
| 4 | SORT UNIQUE | | 1 | 28 | | |
| 5 | NESTED LOOPS SEMI | | 1 | 28 | 1 (0)| 00:00:01 |
| 6 | INDEX FULL SCAN | SYS_C007982 | 3 | 42 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN| SYS_C007959 | 1 | 14 | 0 (0)| 00:00:01 |
|* 8 | INDEX UNIQUE SCAN | SYS_C007959 | 1 | 14 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("US"."USER_ID"="AD"."USER_ID")
filter(TO_NUMBER("US"."USER_ID")=1)
8 - access("USER_ID"="USER_ID")
■EXISTS句でDELETEする実行計画
EXPLAIN PLAN FOR DELETE FROM USERS
WHERE EXISTS (
SELECT * FROM USERS us
INNER JOIN ADDRESS_DETAIL ad
ON us.user_id = ad.user_id
WHERE us.user_id = 1
);
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
PLAN_TABLE_OUTPUT
Plan hash value: 2258361336
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 3 | 42 | 2 (0)| 00:00:01 |
| 1 | DELETE | USERS | | | | |
|* 2 | FILTER | | | | | |
| 3 | INDEX FULL SCAN | SYS_C007959 | 3 | 42 | 1 (0)| 00:00:01 |
| 4 | NESTED LOOPS SEMI | | 1 | 28 | 1 (0)| 00:00:01 |
| 5 | INDEX FULL SCAN | SYS_C007982 | 3 | 42 | 1 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN| SYS_C007959 | 1 | 14 | 0 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter( EXISTS (SELECT 0 FROM "ADDRESS_DETAIL" "AD","USERS" "US"
WHERE "US"."USER_ID"="AD"."USER_ID" AND TO_NUMBER("US"."USER_ID")=1))
6 - access("US"."USER_ID"="AD"."USER_ID")
filter(TO_NUMBER("US"."USER_ID")=1)
⇧ う~む、
Rows統計はSQLチューニングにおいて重要な統計値です。 一般にRows統計は小さい値であることが望ましいとされています。可能であれば、実行計画の処理ステップの早い段階で、Rows統計値を小さい値にできるような、実行計画でSQLを実行することが望ましいです。
⇧ 結局、各ステップを合算した値で比較すれば良いかどうかが分からん...
ちなみに、
⇧ 実際にSQL文を実行して、「実行統計」を取得するとより正確な情報が入手できるそうな。参照系のSQLであれば、試せそうだけども、更新系は難しそう。
キャッシュとかもクリアするので影響は大きそうね...
事前に了承を得てから、テスト環境のDBなどで試す感じになるということでしょうかね。
毎度モヤモヤ感が半端ない...
今回はこのへんで。