
「ルーシー」として知られる人類の祖先の化石が世界的現象を巻き起こすことを最初に予感させたのは、1974年12月、フランス、パリの空港でのことだった。税関を通ろうとしていた古人類学者のドナルド・ジョハンソン氏は、バッグの中に入れていた包みを、「エチオピアからの化石」だと申告した。すると、税関職員が尋ねた。「ルーシーですか?」
そのわずか数週間前の11月24日、ジョハンソン氏はエチオピアのアファール地方で化石を探していた。すると、ハダールという場所で、侵食された丘の斜面から突き出していた前腕骨に目が留まった。
これを回収してキャンプに持ち帰ったジョハンソン氏と発掘チームはその晩、化石の発見を祝って曲をかけ、歌を口ずさんだ。その歌が、ビートルズの名曲「ルーシー・イン・ザ・スカイ・ウィズ・ダイアモンズ」だった。翌日、気温43℃という暑さのなか残りの骨格を掘り出し、これを「ルーシー」と名付けた。
後に、科学界では「AL 288-1」という名がつけられ、さらにエチオピアではアムハラ語で「あなたは素晴らしい」という意味を持つ「ディンキネシュ」と呼ばれた。
ルーシーは、ほかの全ての化石を比較する際に使われる「標準」になっているという。「何かを発見したら、それはルーシーよりも古いのか、新しいのか、ルーシーよりも背が高いのか、低いのかと問うのです」
ルーシーはもはや、人類の祖先として最も古いものではなく、最も骨格がそろったものでもない。今は、700万年前のサヘラントロプス・チャデンシスと600万年前のオロリン・トゥゲネンシスが「最古」の称号をめぐって争っている。また、南アフリカで見つかったアウストラロピテクス属の「リトルフット」の骨格は90%以上そろっている。(参考記事:「南アの初期人類化石、370万年前のものと判明」)
⇧ 前例の無いところから、何かを確立するのがやはり一番大変ではありますからな。
先駆者は、0から1を生み出して後進のための人柱にならざるを得ないですしな。
先人たちの積み上げてきたものは偉大ということですかね。
Pythonの「Apscheduler(Advanced Python Scheduler)」とは
前に、
⇧「Python」で定期実行が実現できるライブラリを調査していた際に、候補に上がったライブラリの1つに「Apscheduler(Advanced Python Scheduler)」がありましたと。
公式のドキュメントによりますと、
Advanced Python Scheduler (APScheduler) is a task scheduler and task queue system for Python. It can be used solely as a job queuing system if you have no need for task scheduling. It scales both up and down, and is suitable for both trivial, single-process use cases as well as large deployments spanning multiple nodes.
Multiple schedulers and workers can be deployed to use a shared data store to provide both a degree of high availability and horizontal scaling.
⇧ とあり、
『Advanced Python Scheduler (APScheduler) is a task scheduler and task queue system for Python.』
であると。
「Task」はというと、
In computing, a task is a unit of execution or a unit of work. The term is ambiguous; precise alternative terms include process, light-weight process, thread (for execution), step, request, or query (for work).
In the adjacent diagram, there are queues of incoming work to do and outgoing completed work, and a thread pool of threads to perform this work. Either the work units themselves or the threads that perform the work can be referred to as "tasks", and these can be referred to respectively as requests/responses/threads, incoming tasks/completed tasks/threads (as illustrated), or requests/responses/tasks.
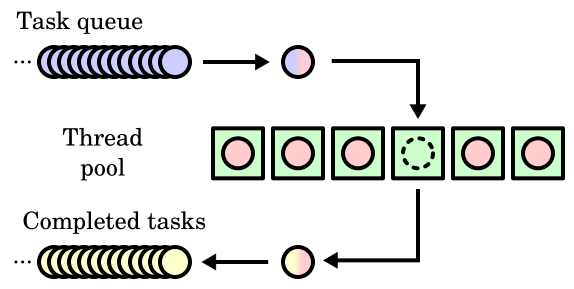
⇧ とあり、「process」の集合体のようなものであると。
「process」はというと、
In computing, a process is the instance of a computer program that is being executed by one or many threads.
There are many different process models, some of which are light weight, but almost all processes (even entire virtual machines) are rooted in an operating system (OS) process which comprises the program code, assigned system resources, physical and logical access permissions, and data structures to initiate, control and coordinate execution activity. Depending on the OS, a process may be made up of multiple threads of execution that execute instructions concurrently.
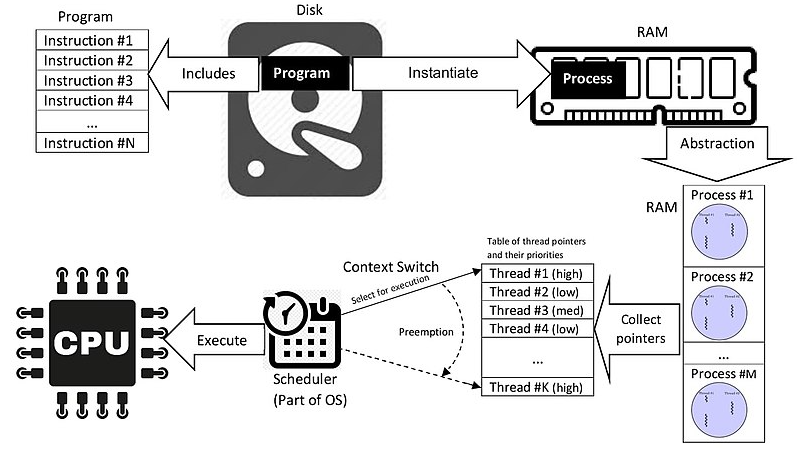
Program vs. Process vs. Thread
Scheduling, Preemption, Context Switching
⇧「thread」の集合体であると。
で、ややこしいのが、「Python」の「プログラム」の処理は、「OS(Operation System)」の「メモリ」上に「process」として展開されることで実行されると思われるのだけど、
『Advanced Python Scheduler (APScheduler) is a task scheduler and task queue system for Python.』
で言っている「task」とは、具体的に何なのか?
ちなみに、
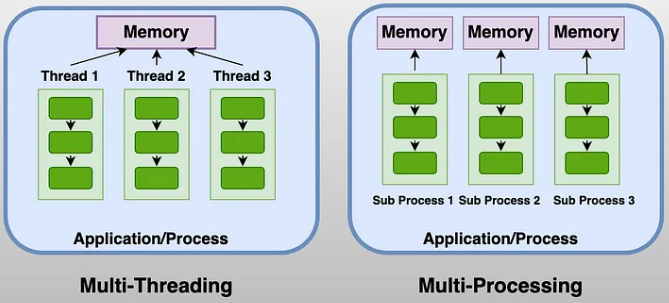
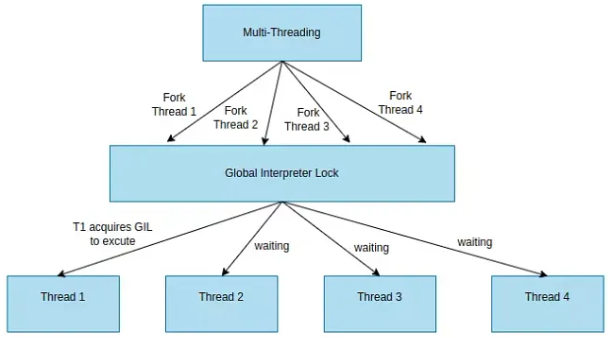
⇧ 上記サイト様にありますように、「Python」は「GIL(Global Interpreter Lock)」の仕組み上、「Multi-Threading」であっても各「thread」は待機させられてしまうようです。
「GIL(Global Interpreter Lock)」については、
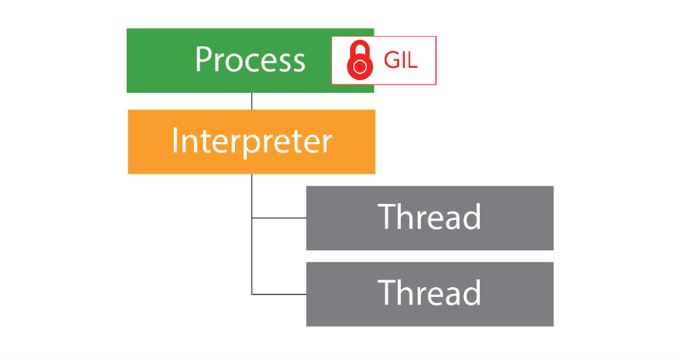
■Python 3.12 sub-interpreters導入後のアーキテクチャ
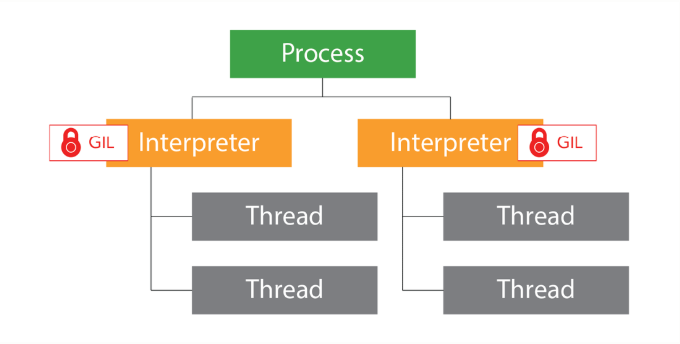
⇧ 将来的に改善されるかもしれないものの、まだ実験的な導入といった感じであるとのこと。
話が脱線しましたが、「Advanced Python Scheduler (APScheduler) 」の公式のドキュメントによりますと、
Basic concepts
APScheduler has four kinds of components:
-
triggers
-
job stores
-
executors
-
schedulers
⇧ とあり、結局のところ「Advanced Python Scheduler (APScheduler) 」において、
『Advanced Python Scheduler (APScheduler) is a task scheduler and task queue system for Python.』
で言っている「Task」が何なのかハッキリしないのですが、
- Task
- job
- trigger
と考えておけば良いということなんですかね?
PythonのApschedulerを利用してみる
「WSL 2(Windows Subsystem for Linux 2)」にインストールしている「Rocky Linux 9」上で、Python標準の「venv」でPython仮想環境を構築して試してみました。
「WSL 2(Windows Subsystem for Linux 2)」にインストールしている「Rocky Linux 9」を起動し、「VS Code(Visual Studio Code)」の拡張機能で「Remote SSH」して、以下のようなファイルを作成。
ソースコードは以下のような感じ。
「VS Code(Visual Studio Code)」を使っている場合
■/home/ts0818/work/app/python/app/.vscode/settings.json
{
"python.testing.unittestEnabled": false
, "python.testing.pytestEnabled": true
, "python.testing.pytestArgs": [
"-c",
"${workspaceFolder}/src/test/resources/pytest/conf/pytest.ini"
]
, "files.exclude": {
"**/__pycache__": true
}
}
ここから、実装に関係する部分。
■/home/ts0818/work/app/python/app/requirements.txt
APScheduler==3.11.0 coverage==7.6.8 exceptiongroup==1.2.2 iniconfig==2.0.0 packaging==24.2 pluggy==1.5.0 pytest==8.3.3 pytest-cov==6.0.0 tomli==2.2.1 tzlocal==5.2
■/home/ts0818/work/app/python/app/src/main/py/scheduling/job/count_three_job.py
import logging
class CountThreeJob:
def count_three_job(self, count_messages: dict, count: int):
CountThreeJob.step_count(count)
CountThreeJob.step_judge(count_messages)
@staticmethod
def step_count(count: int):
for index in range(count):
print(index)
logging.info(f"{count} count finished.")
@staticmethod
def step_judge(count_messages: dict):
for key, value in count_messages.items():
logging.info(f"{key}, {value}")
■/home/ts0818/work/app/python/app/src/main/py/scheduling/scheduler/count_three_scheduler.py
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.job import Job
class CountThreeScheduler:
def __init__(self):
self._scheduler: BackgroundScheduler = BackgroundScheduler()
def add_job_for_scheduler(self, func, trigger=None, args:list=None, kwargs:dict=None) -> Job:
return self._scheduler.add_job(func, trigger, args, kwargs)
以下、pytest用。
■/home/ts0818/work/app/python/app/src/test/resources/pytest/conf/pytest.ini
[pytest] log_cli=true log_format = %(asctime)s %(levelname)s %(message)s log_date_format = %Y-%m-%d %H:%M:%S
■/home/ts0818/work/app/python/app/src/test/py/scheduling/scheduler/test_count_three_scheduler.py
import pytest
import logging
import time
from datetime import datetime
from apscheduler.triggers.cron import CronTrigger
from apscheduler.job import Job
from src.main.py.scheduling.job.count_three_job import CountThreeJob
from src.main.py.scheduling.scheduler.count_three_scheduler import CountThreeScheduler
class TestCoutThreeScheduler:
_logger = logging.getLogger(__name__)
def test_count_three_scheduler(self, caplog):
# self._logger.propagate = True
caplog.set_level(logging.DEBUG)
# trigger
trigger_dict: dict = {
"month": "*"
, "hour": "*"
, "minute": "*"
, "second": "*/5"
, "start_date": datetime.now()
}
trigger = CronTrigger(**trigger_dict)
# job
job = CountThreeJob()
expected_01 = "one count."
expected_02 = "two count."
expected_03 = "three count."
message_dict = {
"one": expected_01
, "two": expected_02
, "three": expected_03
}
count = 3
scheduler = CountThreeScheduler()
add_job: Job = scheduler.add_job_for_scheduler(func=job.count_three_job, trigger=trigger, args=[message_dict, count])
TestCoutThreeScheduler._logger.info(f"\n■add_job■\n{add_job}")
scheduler._scheduler.start()
time.sleep(10)
output = caplog.text
assert expected_01 in output
assert expected_02 in output
assert expected_03 in output
scheduler._scheduler.shutdown()
で、実行する。
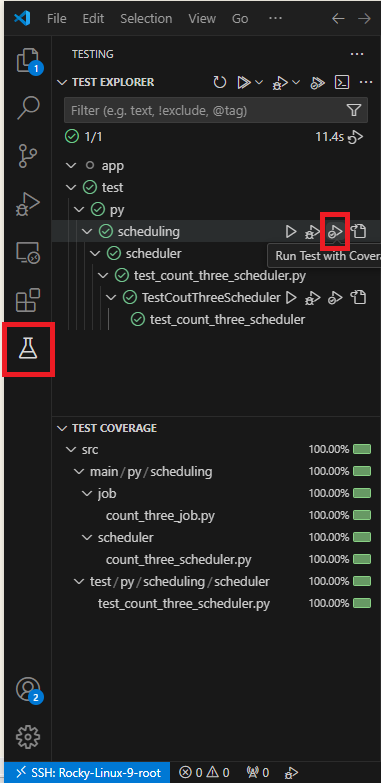
■pytest実行の結果のログ
Running pytest with args: ['-p', 'vscode_pytest', '-c', '/home/ts0818/work/app/python/app/src/test/resources/pytest/conf/pytest.ini', '--rootdir=/home/ts0818/work/app/python/app', '--cov=.', '/home/ts0818/work/app/python/app/src/test/py/scheduling/scheduler/test_count_three_scheduler.py::TestCoutThreeScheduler::test_count_three_scheduler']
============================= test session starts ==============================
platform linux -- Python 3.9.18, pytest-8.3.3, pluggy-1.5.0
rootdir: /home/ts0818/work/app/python/app
configfile: src/test/resources/pytest/conf/pytest.ini
plugins: cov-6.0.0
collected 1 item
src/test/py/scheduling/scheduler/test_count_three_scheduler.py::TestCoutThreeScheduler::test_count_three_scheduler
-------------------------------- live log call ---------------------------------
2024-12-01 20:40:51 INFO
■trigger_dict■
{'month': '*', 'hour': '*', 'minute': '*', 'second': '*/5', 'start_date': datetime.datetime(2024, 12, 1, 20, 40, 51, 32993)}
2024-12-01 20:40:51 DEBUG /etc/timezone found, contents:
Asia/Tokyo
2024-12-01 20:40:51 DEBUG /etc/localtime found
2024-12-01 20:40:51 DEBUG 2 found:
{'/etc/timezone': 'Asia/Tokyo', '/etc/localtime is a symlink to': 'Asia/Tokyo'}
2024-12-01 20:40:51 INFO Adding job tentatively -- it will be properly scheduled when the scheduler starts
2024-12-01 20:40:51 INFO
■add_job■
CountThreeJob.count_three_job (trigger: cron[month='*', hour='*', minute='*', second='*/5'], pending)
2024-12-01 20:40:51 INFO Added job "CountThreeJob.count_three_job" to job store "default"
2024-12-01 20:40:51 INFO Scheduler started
2024-12-01 20:40:51 DEBUG Looking for jobs to run
2024-12-01 20:40:51 DEBUG Next wakeup is due at 2024-12-01 20:40:55+09:00 (in 3.950129 seconds)
2024-12-01 20:40:55 DEBUG Looking for jobs to run
2024-12-01 20:40:55 INFO Running job "CountThreeJob.count_three_job (trigger: cron[month='*', hour='*', minute='*', second='*/5'], next run at: 2024-12-01 20:40:55 JST)" (scheduled at 2024-12-01 20:40:55+09:00)
2024-12-01 20:40:55 DEBUG Next wakeup is due at 2024-12-01 20:41:00+09:00 (in 4.995986 seconds)
2024-12-01 20:40:55 INFO 3 count finished.
2024-12-01 20:40:55 INFO one, one count.
2024-12-01 20:40:55 INFO two, two count.
2024-12-01 20:40:55 INFO three, three count.
2024-12-01 20:40:55 INFO Job "CountThreeJob.count_three_job (trigger: cron[month='*', hour='*', minute='*', second='*/5'], next run at: 2024-12-01 20:41:00 JST)" executed successfully
2024-12-01 20:41:00 DEBUG Looking for jobs to run
2024-12-01 20:41:00 DEBUG Next wakeup is due at 2024-12-01 20:41:05+09:00 (in 4.995734 seconds)
2024-12-01 20:41:00 INFO Running job "CountThreeJob.count_three_job (trigger: cron[month='*', hour='*', minute='*', second='*/5'], next run at: 2024-12-01 20:41:05 JST)" (scheduled at 2024-12-01 20:41:00+09:00)
2024-12-01 20:41:00 INFO 3 count finished.
2024-12-01 20:41:00 INFO one, one count.
2024-12-01 20:41:00 INFO two, two count.
2024-12-01 20:41:00 INFO three, three count.
2024-12-01 20:41:00 INFO Job "CountThreeJob.count_three_job (trigger: cron[month='*', hour='*', minute='*', second='*/5'], next run at: 2024-12-01 20:41:05 JST)" executed successfully
2024-12-01 20:41:01 INFO Scheduler has been shut down
2024-12-01 20:41:01 DEBUG Looking for jobs to run
2024-12-01 20:41:01 DEBUG No jobs; waiting until a job is added
PASSED [100%]
---------- coverage: platform linux, python 3.9.18-final-0 -----------
Name Stmts Miss Cover
------------------------------------------------------------------------------------
src/main/py/scheduling/job/count_three_job.py 14 0 100%
src/main/py/scheduling/scheduler/count_three_scheduler.py 7 0 100%
src/test/py/scheduling/scheduler/test_count_three_scheduler.py 31 0 100%
------------------------------------------------------------------------------------
TOTAL 52 0 100%
============================== 1 passed in 10.46s ==============================
Finished running tests!
⇧ とりあえず、動くことは確認できたのだけど、「start_date」とかが、CronTriggerのインスタンス生成のタイミングの時間になるということなんかな?
トリガーの生成と、スケジューラーの設定で、微妙にタイムラグが生まれそうな気がするんだが、そのあたりは、どうしようもないということなんかな?
そもそも、公式のドキュメントの実装例が少な過ぎて、いまいち、正しい使い方がいろいろと分からんのよね...
毎度モヤモヤ感が半端ない…
今回はこのへんで。