
“AMD has done a solid job over the last couple of years. We won’t dismiss them of the good work that they’ve done, but that’s over with Alder Lake and Sapphire Rapids,” he said.
⇧ 言い方、言い方~、この世の中、言い方ってものがありますやん?
写真が笑顔なのに、怖いことサラッと言うよね~...
https://hothardware.com/news/intel-ceo-alder-lake-cpu-alchemist-gpu-challenge-amd-nvidia
⇧ なんか、「NVIDIA」に対しても不穏なメッセージを投げかけてますな...
例の如く、冒頭から脱線しまくりましたが、データーベース関連について調べてみました。
レッツトライ~。
ヒット率とは?
Wikipediaさんに聞いてみた。
キャッシュメモリにない確率はNFP(Not Found Probability)と呼ばれ、これはヒット率の余事象であるので「1-ヒット率」で求めることができる。
⇧ という説明となっていますと。
Intelさんの例になっちゃうけど、
-
Read-only memory path for OpenCL images which includes a level-1 (L1) and a level-2 (L2) sampler caches. Image writes follow different path (see below);
-
Level-3 (L3) data cache is a slice-shared asset. All read and write actions on OpenCL buffers flows through the L3 data cache in units of 64-byte wide cache lines. The L3 cache includes sampler read transactions that are missing in the L1 and L2 sampler caches, and also supports sampler writes. See section “Execution of OpenCL™ Work-Items: the SIMD Machine” for details on slice-shared assets.

Figure 4. View of memory hierarchy and peak bandwidths (in bytes/cycle) for the Gen7.5 compute architecture (4th Generation Intel® Core™ family of microprocessors).
⇧ 上図のような感じで「CPU」は「データ」とやり取りするらしいのですが、
キャッシュメモリ (cache memory) は、CPUなど処理装置がデータや命令などの情報を取得/更新する際に主記憶装置やバスなどの遅延/低帯域を隠蔽し、処理装置と記憶装置の性能差を埋めるために用いる高速小容量メモリのことである。略してキャッシュとも呼ぶ。
キャッシュメモリは、通常は下位レベルの記憶装置より小容量で高速なスタティックRAMを用いて構成される。データ本体の一部とそのアドレス、フラグなど属性情報のセットを固定容量のメモリに格納する構造で、データ格納構造、ライン入替え、データ更新方式などに多数のアーキテクチャが存在する。
以前はCPUチップの外部に接続されていたが、LSIの集積度の向上や要求速度の上昇に伴いCPUチップ内部に取り込まれることが普通となった。また最近のCPUとメモリの性能差の拡大、マルチスレッドなどアクセス範囲の拡大に対応するため、キャッシュも多段構造とする例が増えている。この場合CPUに近い側からL1(レベル1)キャッシュ、L2(レベル2)キャッシュと呼ばれ、2013年時点ではL4キャッシュまでCPUに内蔵する例も存在する。CPUから見て一番遠いキャッシュメモリの事をLLC(Last Level Cache)と呼ぶ事もある。
⇧ とあるように、「キャッシュメモリ」は、
- L1キャッシュ(Level1 Cache)
- L2キャッシュ(Level2 Cache)
- L3キャッシュ(Level3 Cache)
- L4キャッシュ(Level4 Cache)
- LLC(Last Level Cache)
まで、存在するみたい。
各々の「キャッシュメモリ」の違いについては、
「CPUのキャッシュは、L1が32KB、L2が256KB、L3が2MBという風に多層に分かれているが、なぜ、32KB+256KB+2MBのL1キャッシュではダメなのか?」という素朴な疑問に対して、ファビアン・ギーセン氏(ryg)が「1960年代の古いオフィスでの働き方」を例に挙げて明解に回答しています。
⇧ 上記サイト様が詳しいです。
脱線しましたが、「ヒット率」ってのは、「CPU」が「キャッシュメモリ」で必要な「データ」を検索できる割合、ってことになるみたい。
ここで、「キャッシュ」はというと、
キャッシュ(英語: cache)は、CPUのバスやネットワークなど様々な情報伝達経路において、ある領域から他の領域へ情報を転送する際、その転送遅延を極力隠蔽し転送効率を向上するために考案された記憶階層の実現手段である。
⇧ ってな説明になっていますと。
なので、「キャッシュメモリ」ってのは「ハードウェア」で「キャッシュ」を実現しているってことになるんかな。
「処理速度」や「容量」なんかとかの比較図も、

⇧ 掲載されてますと。
「主記憶」が「メモリ」のことだと思うから、「キャッシュ」は「処理速度」的には非常に「高速」ってことになるみたいね。
だいぶ、脱線しまくりましたが、
キャッシュの典型例はCPUと主記憶装置の間のキャッシュメモリだが、それ以外にもデータベース管理システムやオペレーティングシステムなどの各種のソフトウェアのキャッシュ、各種の補助記憶装置などの内蔵キャッシュ、各種のキャッシュサーバなども含まれる。
⇧「データベース」についても「キャッシュ」は実現されてるらしいのですが、こちらは「ソフトウェア」で実現しているということになるらしいですと。
「データベース」における「キャッシュ」とは?
Wikipediaの英語版のほうの情報では、「ソフトウェア」の「キャッシュ」について紹介があるのですが、
Disk Cache
Main article: Page cache
While CPU caches are generally managed entirely by hardware, a variety of software manages other caches. The page cache in main memory, which is an example of disk cache, is managed by the operating system kernel.
While the disk buffer, which is an integrated part of the hard disk drive, is sometimes misleadingly referred to as "disk cache", its main functions are write sequencing and read prefetching. Repeated cache hits are relatively rare, due to the small size of the buffer in comparison to the drive's capacity. However, high-end disk controllers often have their own on-board cache of the hard disk drive's data blocks.
Finally, a fast local hard disk drive can also cache information held on even slower data storage devices, such as remote servers (web cache) or local tape drives or optical jukeboxes; such a scheme is the main concept of hierarchical storage management. Also, fast flash-based solid-state drives (SSDs) can be used as caches for slower rotational-media hard disk drives, working together as hybrid drives or solid-state hybrid drives (SSHDs).
⇧ おそらく、「データベース」で出てくる「バッファヒット率」に関わってくる「キャッシュ」ってのは、「Disk Cache」のことを言っているんではないかと。
というのも、手前味噌で恐縮ですが、
⇧ 前回の記事で、「Oracle Database」のドキュメントに依るので「Oracle Database」以外の「データベース」については不明な話になってしまうのですが、少なくとも「Oracle Database」においては、「OS(Operation System)」との「I/O」における「最小単位」は「ブロック(ページ)」になると言っていたので。
ここで、「Oracle Database」が「メモリ」をどう利用しているかと言うと、
Introduction to Oracle Database Memory Structures
When an instance is started, Oracle Database allocates a memory area and starts background processes.
The memory area stores information such as the following:
-
Program code
-
Information about each connected session, even if it is not currently active
-
Information needed during program execution, for example, the current state of a query from which rows are being fetched
-
Information such as lock data that is shared and communicated among processes
-
Cached data, such as data blocks and redo records, that also exists on disk
⇧「instance」が開始された段階で、「memory area」が割り当てられて、「background processes」が開始される、と言っていて、「memory area」で「Cached data, such as data blocks and redo records, that also exists on disk」保管するって言ってますと。
じゃあ、その「instance」ってのはと言うと、

⇧ 上図のような構造になってますと。
で、「物理ファイル」とやり取りしてるっぽい「Database Buffer Cache」の説明を見てみると、
Database Buffer Cache
The database buffer cache, also called the buffer cache, is the memory area that stores copies of data blocks read from data files.
⇧ ってなってますと。
で、「data blocks」と「data files」については、
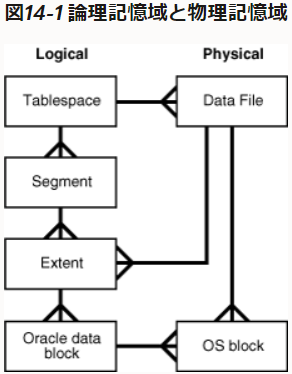
⇧ おそらく、「OS block」と連携してるものだと思われるので、「Database Buffer Cache」ってのが、「データベース」における「キャッシュ」ってことになるんかな、「Oracle Database」の話にはなるけど。
「Buffer I/O」の説明を見た感じでも、
Buffer I/O
A logical I/O, also known as a buffer I/O, refers to reads and writes of buffers in the buffer cache.
When a requested buffer is not found in memory, the database performs a physical I/O to copy the buffer from either the flash cache or disk into memory. The database then performs a logical I/O to read the cached buffer.
⇧「バッファ」が「メモリ」に見当たらなかったら、 「バッファ」を「フラッシュメモリ」または「ディスク」から「メモリ」へコピーする、と言ってますと。
ちなみに、「Oracle Database」における「バッファ」は、「logical I/O」のことらしく、
Oracleの場合のI/Oとはディスクからの読込であるPhysical Reads(物理読込)とメモリ(SGA)からの読込であるLogical Reads(論理読込)があります。
⇧ 上記サイト様によりますと、「Oracle Database」の「instance」が作り出してる「memory area」からの読み込みになるらしいので、「Oracle Database」の「instance」が停止した場合は、読み込めないということですね。
さらに、
サーバのメインメモリ上にあるデータは、サーバの電源が落ちれば消えてしまいます。だからこそ、現在のデータベースではデータを失わないように永続化の手段としてデータベースやログをハードディスクに保存しています。
インメモリデータベースでサーバが落ちたらデータはどうなる? インメモリとカラム型データベースの可能性を調べる(その3) - Publickey
⇧ ってな感じで、「データベース」の「ログファイル」が量産されるのは致し方ない仕様ということらしい。
なるほど、「Oracle Database」でも「高速リカバリ領域(Fast Recovery Area)」に「ログファイル」が大量に作成されるので「メモリ」を多めに見積もって割当てしとかないと、すぐに「高速リカバリ領域(Fast Recovery Area)」が逼迫して「Oracle Database」の「instance」が落ちるってことなんかね。
「Oracle Database」の場合、「Oracle Database」の「instance」が起動すると「memory area」が割り当てられるので、仮に何かしらの障害で「instance」が停止してしまった場合、「memory area」も無くなるので、「memory area」に存在した「データ」は跡形もなく消えてしまうのだけれど、「高速リカバリ領域(Fast Recovery Area)」などに一度作成された「ログファイル」なんかは、「Oracle Database」の「instance」が停止したとしても消えることはない、という仕組みらしい。
まぁ、「高速リカバリ領域(Fast Recovery Area)」に「メモリ」を多めに割当とか無いと、「高速リカバリ領域(Fast Recovery Area)」の空き容量が枯渇して、エラーになって「Oracle Database」の「instance」が停止して起動できない事態が起こるんだけどね...
手前味噌になりますが、
⇧「高速リカバリ領域(Fast Recovery Area)」が逼迫することによって起こるエラーで「Oracle Database」の「instance」が起動できなくなる例は、上記の記事をご参考くださいませ。
ちなみに、
結論としては、インメモリデータベースでもつねにログをハードディスクやフラッシュドライブなどのストレージへ書き込んで、サーバの物理的障害に備えています。インメモリデータベースであっても、メインメモリだけに依存しているわけではないのです。
インメモリデータベースでサーバが落ちたらデータはどうなる? インメモリとカラム型データベースの可能性を調べる(その3) - Publickey
⇧「インメモリデータベース」でも「メモリ」外に「ログ」を保存してるらしい。
「インメモリデータベース」ってのは、
インメモリデータベース(IMDBあるいはメインメモリデータベース、MMDB)はデータストレージを主にメインメモリ上で行うデータベース管理システムである。ディスクストレージ機構によるデータベースシステムと対比される。
基本的な構成として、インメモリデータベースはデータを揮発性メモリ装置に格納する。このようなデバイスはデバイスの電源が断たれたり、リセットされた場合にすべての格納情報を失う。この場合、インメモリデータベースはACID(原子性、一貫性、独立性、永続性)特性のうち、永続性をサポートしないと言える。
⇧ って説明になってて、

⇧ 上図で言うと、「(a)」に「データ」が保存されるってことなんですかね。
いまいち、「データベース」自体がどこに配置されるかがよく分からんですな...
脱線しましたが、「Oracle Database」のドキュメントに話を戻すと、「バッファ」の読み込みの例で、
Buffer Reads
When a client process requests a buffer, the server process searches the buffer cache for the buffer. A cache hit occurs if the database finds the buffer in memory. The search order is as follows:
-
The server process searches for the whole buffer in the buffer cache.
If the process finds the whole buffer, then the database performs a logical read of this buffer.
-
The server process searches for the buffer header in the flash cache LRU list.
If the process finds the buffer header, then the database performs an optimized physical read of the buffer body from the flash cache into the in-memory cache.
-
If the process does not find the buffer in memory (a cache miss), then the server process performs the following steps:
-
Copies the block from a data file on disk into memory (a physical read)
-
Performs a logical read of the buffer that was read into memory
-

⇧ イメージ図が掲載されていて、確かに「バッファ」が「メモリ」に存在しない場合は「磁気ディスク」から読み込んでるっぽいですね。
で、「コンピューター」の「プロセス」の例とかを見てみると、

⇧「CPU」と「メモリ」、「ディスク」までは、いろいろ処理が挟まるので、「キャッシュメモリ」に比べると「処理速度」が遅くなるってことみたい。
「Oracle Database」の例になっちゃうけど、「コンピューター」の「キャッシュメモリ」と同じ感じで、「データベース」の「キャッシュ」と思われる「Database Buffer Cache」は「処理速度」に影響してるってことですかね。
ここで、「独立行政法人 情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」の「データベーススペシャリスト」の「平成30年度」の「過去問」で「午後Ⅱ」の「問1」で、

⇧「バッファヒット率」なる「用語」が出てくるのですが、「Oracle Database」で考えた場合は、「Database Buffer Cache」に対する「ヒット率」と見なせなくもないような気がしますと。
まぁ、長々と迷走してきましたが、これというのも、「独立行政法人 情報処理推進機構(IPA:Information-technology Promotion Agency, Japan)」が「バッファヒット率」が何を指すのかをちゃんと明示してくれていないからして、もうちょっと後進を育てようみたいな気概を示してくれるとありがたいんですけどね...
というわけで、まとめると、「Oracle Database」以外の「データベース」については不明だけれど、少なくとも「Oracle Database」においては、「Buffer Cache」に対する「ヒット率」のことを「バッファヒット率」と言えるのではないか、と。
毎度、モヤモヤ感が半端ない...
今回はこのへんで。