
ウェブカラーの基礎が作られたのは1984年。マサチューセッツ工科大学(MIT)が開発したX Window System(X11)でGUIがリリースされたのがきっかけで、続く1986年にリリースされたX10R3にはGUIカラーのリストが実装されていました。なお、この時のリストは「dark red」と「DarkRed」のように、2種類の表記を使った69個の色名が記されていたとのこと。
現在使われている「色名」が本格的に世に登場したのは1989年にX11R4がリリースされた時。当時はどのマシンを使うかによって色の見え方が全く違っていたため、「『小麦色』が全然小麦色じゃない」ということも。そこで、ユーザーたちからの「色の正確性をなんとかして欲しい」という声に答えるため、X11R4ではユーザー環境によって大きな差異を生み出さないような柔らかみのある中間色が多く追加され、「パパイア・ホイップ」「レモン・シフォン」「ピーチ・パフ」のようなやや抽象的な名前がつけられたわけです。
⇧ みんなの期待に応えようと頑張り、この後もいろいろ手を尽くすわけですが、
しかし、数多くのプログラマーの目にさらされたため、X11の色名称は「グレーがダークグレーよりも暗い」「ミディアム・バイオレット・レッドはあるのに基準となるバイオレット・レッドがない」など、批判的なプログラマーたちの攻撃の的となってしまいます。2002年には「X11の色名称は素晴らしいCSSのデザイン要素に汚点を残す、この世から消し去るべきいまいましい存在だ。X11の色名称が『デザインされた』と言うことは『デザイン』という言葉に対する侮辱だ。あれはただのゴミだ」と意見するプログラマーが出てきたほどでした。
⇧ 辛辣な言葉の数々、切な過ぎる(涙)。
そして、訪れる結論
しかし、実際のところ、X11の色名称は16進数のカラーコードやRGBカラーコードで表すことが可能。これら2種の方法は図式的・客観的であり、地域性を含んでいないグローバルなシステムなので、本来であれば色名が気に入らないのであれば、コードを使用すればいいだけの話なのです。
⇧ それ言っちゃう?
でも、「FFFFFF」や「255」が「白」とかは何とか分かるけど、微妙な色になってくると、「16進数のカラーコード」や「RGBカラーコード」でやり取りするのは専門のデザイナーでもない我々一般ピープルには辛いですな...
そんなこんなで、脱線しましたが、 昔、PHPの参考書とかで、ファイルを保存するときには、「UTF-8 BOMなし」にすべしって話があって、何で?って思ったので調べてみました。
レッツトライ~。
BOM(Byte Order Mark)って?
Wikipediaさんに聞いてみた。
バイト順マーク (バイトじゅんマーク、英: byte order mark) あるいはバイトオーダーマークとは、通称BOM(ボム)といわれるUnicodeの符号化形式で符号化したテキストの先頭につける数バイトのデータのことである。このデータを元にUnicodeで符号化されていることおよび符号化の種類の判別に使用する。
プログラムがテキストデータを読み込む時、その先頭の数バイトからそのデータがUnicodeで表現されていること、また符号化形式(エンコーディング)としてどれを使用しているかを判別できるようにしたものである。
⇧ う~ん、これだけだと、いまいち分からんね。
「経緯」を見てみると、
UnicodeがはじまったころはアメリカではASCII、ヨーロッパなどではISO-8859、日本ではShift_JISやEUC-JPが主流であり、使用されている符号化方式がUnicodeであることを明確に区別する必要があった。その方法として、先頭のデータにテキスト以外のデータを入れることが発案された。
また、1文字が数バイトに渡るUnicodeでは、エンディアンの違いが認識できないと、例えばPowerPC Macintoshとx86 MS-DOSとの間で正常にデータの交換ができないため、この先頭バイトにより区別できるようにされた。
⇧ 要するに、PCで扱うテキストの「符号化形式(エンコーディング)」の規格が統一されていなかったので、「Unicode」ってものを導入する際に「Unicode」以外の「符号化形式(エンコーディング)」と判別する方法が欲しくて「BOM(Byte Order Mark)」ってものが発案されたらしい。
Unicodeって?
Wikipediaさんに聞いてみた。
Unicode(ユニコード)は、符号化文字集合や文字符号化方式などを定めた、文字コードの業界規格。文字集合(文字セット)が単一の大規模文字セットであること(「Uni」という名はそれに由来する)などが特徴である。
従来、国あるいは各メーカーで独自に開発されていた文字コードには互換性がなかった。複数の文字コードを共存させる方法には文字が重複する短所があるため、微細な差異はあっても本質的に同じ文字であれば一つの番号を当てる方針で各国・各社の文字コードの統合を図ったものである。
⇧ 「文字コード」の統一化のために導入された「文字コード」ってことみたいね。
策定された時期は、1980年代らしいのですが、
1980年代に、Starワークステーションの日本語化 (J-Star) などを行ったゼロックスが提唱し、マイクロソフト、アップル、IBM、サン・マイクロシステムズ、ヒューレット・パッカード、ジャストシステムなどが参加するユニコードコンソーシアムにより作られた。国際規格のISO/IEC 10646とUnicode規格は同じ文字コード表になるように協調して策定されている。
⇧ 錚々たる企業が名を連ねてますね。
「文字コード」ということで、
Unicode以前の文字コードとの相互運用性もある程度考慮されており、歴史上・実用上の識別が求められる場合には互換領域がとられ、元のコード→Unicode→元のコードというような変換(ラウンドトリップ変換)において、元通りに戻るよう配慮されている文字もある。しかし、正規のJIS X 0208の範囲内であればトラブルは少ないが、複数の文字集合が混在したり、Shift_JISの実態であるCP932やEUC-JPの亜種であるCP51932とeucJP-MSなど、対応が違うために文字化けを起こすことがある。
⇧ ってな感じで、文字化けとかに関係してきますと。
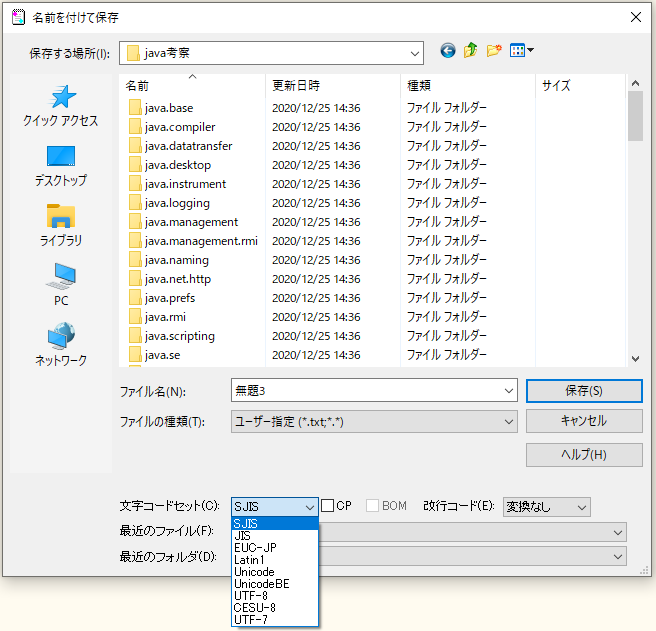
テキストエディタなんかで保存する際に指定できますかね。
以下はサクラエディタのキャプチャ画像の例。
Unicode文字符号化モデルって?
Unicodeに関する「文字コード」の定義ってことみたいね。
その前に「文字コード」 って?
文字コード(もじコード)は、コンピュータ上で文字(キャラクタ)を利用する目的で各文字に割り当てられるバイト表現。もしくは、バイト表現と文字の対応関係(文字コード体系)のことを指して「文字コード」と呼ぶことも多い。本記事では主に後者について記述する。
元来、文字コードは文字の集合の各文字に直接一意なバイト表現を割り当てただけのシンプルなものだったが、JIS X 0208というひとつの文字集合に対してISO-2022-JP、EUC-JP、Shift_JISなど複数の符号化方式が存在するようになってきたり、逆に複数の文字集合を切り替えて使うISO-2022-JPやEUC-JPといった符号化方式が用いられるようになってきたため、「符号化文字集合」と「文字符号化方式」とを区別するようになったと考えられる。
⇧ ってな感じで、コンピューターが解釈できるように「バイト表現と文字の対応関係(文字コード体系)」を定義したものってことですかね。
Wikipediaさんによりますと、
- 符号化文字集合(CCS:Coded Character Set)
文字と一意に振られた番号のペアの集合。 - 文字符号化方式(CES:Character Encoding Scheme)
文字に振られた番号をバイト表現に変換する方法。
の2つで「文字コード」を判別するようになってたらしいんですが、
⇧ かなり曖昧な感じの定義になってしまっていましたと。
そこで、Unicodeさんによる「文字コード」の定義はと言うと、Wikipediaさんによりますと、
- 抽象文字集合(ACR:Abstract Character Repertoire)
符号化の対象とする順序のない文字の集合。 - 符号化文字集合(CCS:Coded Character Set)
抽象文字集合を非負整数に対応させたもの。この非負整数の範囲を符号空間、各値を符号位置といい、抽象文字は対応後、符号化文字となる。抽象文字は複数の符号化文字に対応されることもある。 - 文字符号化形式(CEF:Character Encoding Form)
符号化文字集合の非負整数を符号単位列に変換する方法。文字符号化形式はコンピュータ中に実際にデータとして文字を表現することを可能にする。 - 文字符号化方式(CES:Character Encoding Scheme)
符号単位列をバイト列に直列化する方法。符号単位が8ビットより大きい場合はエンディアンが関係する。
ってな感じで、4つに増えましたと。
BOM(Byte Order mark)と文字符号化形式(CEF:Character Encoding Form)
で、ようやっと本題。
実際にBOMを使用すべきか、あるいは使用すべきでないかは、Unicodeを利用したより上位の仕様によって定められることがある。"XML Media Types" (RFC 3023) では、XMLをUTF-16で符号化する場合は先頭のBOMを必須とし、またXMLを解釈するソフトウェアでは、先頭にBOMがあった場合はxml宣言における<?xml encoding="..."?>の指定よりも優先してエンコーディングを判別すべきとしている。
JSONの場合は、ネットワークで送信する場合はBOMを付けてはならないとしている。
UTF-8は文字コードとしてASCIIを前提としたプログラムでもおよそ支障なく動作するように設計されているが、BOMによって正常に処理できなくなる場合がある。Unicodeの規格において、UTF-8においてBOMは容認されるが、必須でも勧められるものでもないとされている。
また、データベースやメモリにロードするデータなど、内部的なデータ形式では、プログラムの性能や効率の観点から普通BOMは用いられない。
⇧ ってな感じで、「BOM(Byte Order Mark)」を付いてるか付いてないかってのが条件によって変わってくるんだと。
というか、「Unicode」かどうかを判別するために導入せざるを得なかった「BOM(Byte Order Mark)」ですが、「BOM(Byte Order Mark)なし」推しが目立ちますね。
じゃあ、
- BOM(Byte Order Mark)付き
- BOM(Byte Order Mark)なし
ってどうやって判断すれば良いのよ?
「文字符号化形式(CEF:Character Encoding Form)」 と「エンディアン」で分類できますと。
Wikipediaさんによりますと、
| 符号化形式 (符号化スキーム) |
エンディアン の区別 |
バイト順マーク (BOM) |
|---|---|---|
| UTF-8 | 0xEF 0xBB 0xBF (なおBOM無しはUTF-8Nと呼ばれることがある) |
|
| UTF-16 | BE | 0xFE 0xFF |
| LE | 0xFF 0xFE | |
| UTF-16BE | (付加は認められない) | |
| UTF-16LE | (付加は認められない) | |
| UTF-32 | BE | 0x00 0x00 0xFE 0xFF |
| LE | 0xFF 0xFE 0x00 0x00 | |
| UTF-32BE | (付加は認められない) | |
| UTF-32LE | (付加は認められない) | |
| UTF-7 | 0x2B 0x2F 0x76 ※ (※は次のバイトの値によって異なり、 0x38、0x39、0x2B、0x2Fのいずれかがくる) |
ってな感じで、「BOM」が付いてるか付いてないかが分かるみたい。
「BOM」は「16進数」の「byte」ってことらしいですと。
ちなみに、
結論からいうと「BOM付きUTF-8」では無理です!!!
「Mac版Microsoft Excel」で表示させるためには「BOM付きUTF-16LE」という文字コードでかつ「TSV形式」でないとMac、Windows両方で表示可能なファイルを作ることができません。
⇧ Microsoft Excelって、Mac版とWindows版で文字コードの扱いが異なるんだそうな、現場を混乱させてくれるMicrosoft さん流石です...
UTF-8のBOMあるなしをJavaで判定してみる
というわけで、UTF-8 のBOMあるなしをJavaで判定してみますか。
テキストの先頭に、
- 0xEF
- 0xBB
- 0xBF
の「byte」が付いていれば「BOMあり」ってことらしいので、テキストのバイトの先頭に上記の3つのバイトが含まれているかどうかを判定してあげれば良いですと。
⇧ 上記サイト様の「058:コアAPI:java.nio(2)」を実施いたしました。(バッチ以外は上記サイト様の内容をそのまま利用してます。)
Eclipseで以下のようなファイルを準備して、
で、調べた限りでは、
Eclipse で新規にファイルを作成すると Workspace に設定されたエンコードで保存されます。
文字エンコーディングを UTF-8 に設定した場合、新規にファイルを作成しても BOM は付きません。
⇧ Eclipse側で「BOM付き」保存ってのはできないようなので、「エクスプローラー」のほうで、ファイルを「BOM付き」「BOMなし」で保存します。
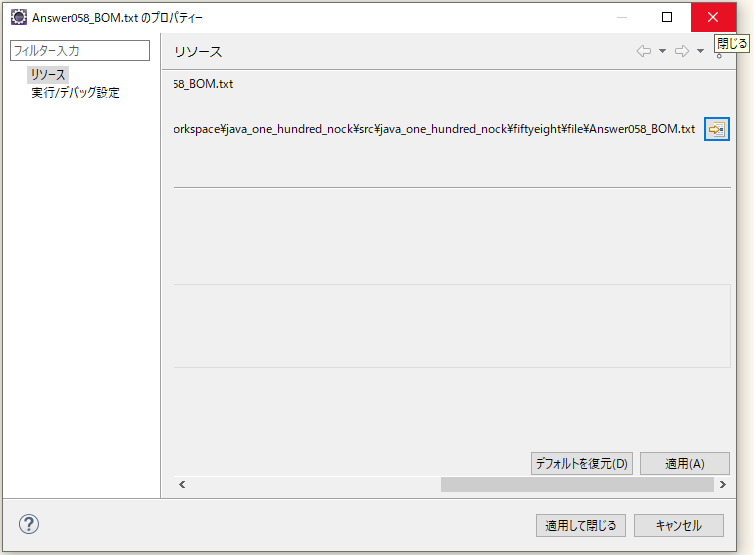
「プロパティー(R)」を選択し、
「ロケーション(L):」の右端にある、

「アイコン」をクリックで。
クリック後、Windowsの場合は「エクスプローラー」が開くので、Eclipse のほうの「プロパティー」のウィンドウは閉じるで。
「エクスプローラー」のほうが開いたら、こちらでファイルを開いて、「BOM付き」「BOMなし」で保存します。(メモ帳だと「BOM付き」でしか保存できないので、サクラエディタとかで開いて保存が良いかも。サクラエディタはインストールして無い場合はインストールが必要)
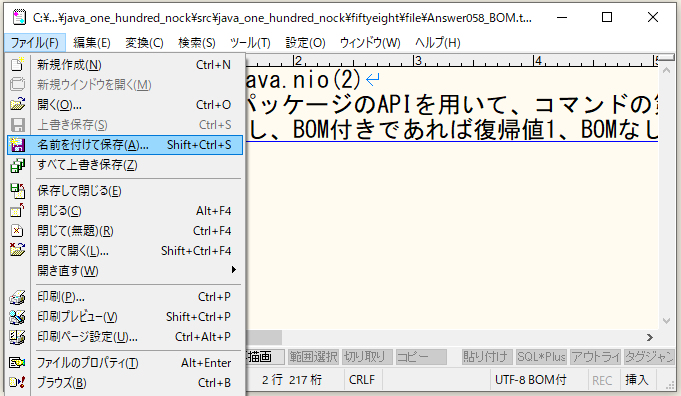
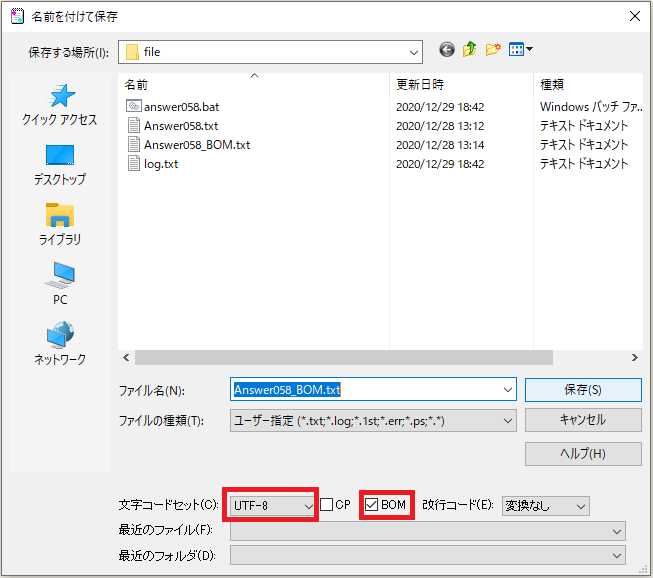
⇧「BOM付き」の場合の例。
で、Windowsのバッチを自分の環境に合わせて、編集します。
@ECHO OFF @REM ------------------------------- @REM java-100practies @REM answer058.bat @REM author: ts0818 cd %~dp0 SET word="Answer058_BOM.txt" SET javaC="C:\Eclipse-2020-06\pleiades-2020-06-java-win-64bit-jre_20200702\pleiades\java\11\bin\javac.exe" SET javaExe="C:\Eclipse-2020-06\pleiades-2020-06-java-win-64bit-jre_20200702\pleiades\java\11\bin\java.exe" SET classPath="C:\Eclipse-2020-06\pleiades-2020-06-java-win-64bit-jre_20200702\pleiades\workspace\java_one_hundred_nock\bin" SET sourcePath="C:\Eclipse-2020-06\pleiades-2020-06-java-win-64bit-jre_20200702\pleiades\workspace\java_one_hundred_nock\src" SET log="log.txt" @REM コンパイル %javaC% Answer058.java > %log% 2>&1 @REM プログラムの実行 %javaExe% -classpath %classPath% java_one_hundred_nock.fiftyeight.Answer058 %word% > %log% 2>&1 IF ERRORLEVEL 1 GOTO FAILURE GOTO SUCCESS :FAILURE EXIT /B %ERRORLEVEL% :SUCCESS
⇧ で、バッチを実行。
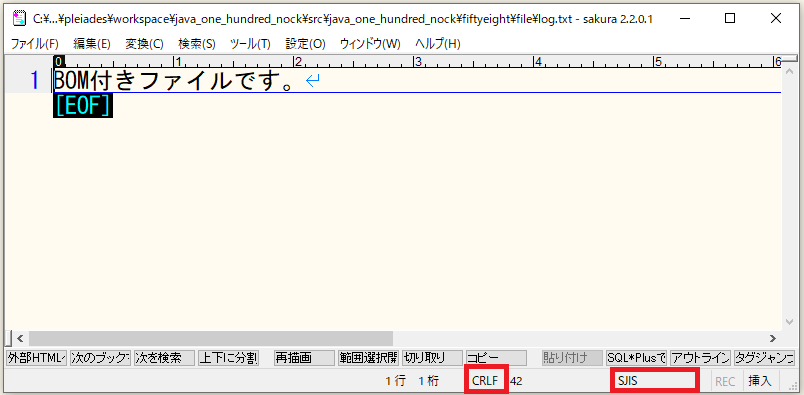
⇧ 実行結果は正しそうなんですが、ファイルが「Shift-JIS」で作成されるという。
Eclipseで確認すると、
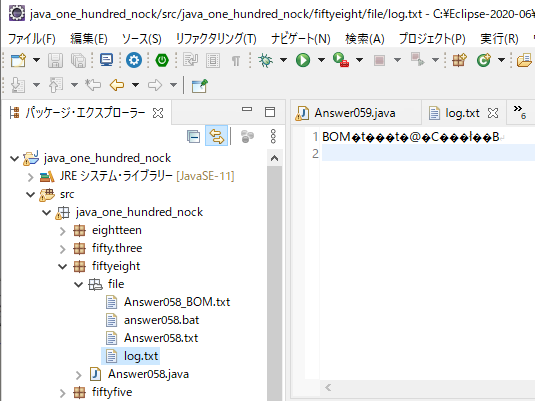
⇧ 凄まじく文字化けするというね。
これは、Eclipse側で「ウィンドウ(W)」>「設定(P)」
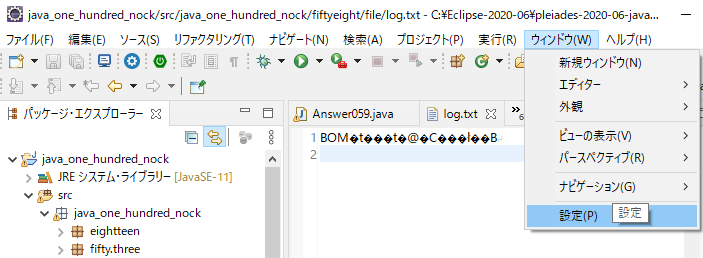
「一般」>「ワークスペース」の「テキスト・ファイル・エンコード(T)」が「UTF-8」にしてるため、バッチ処理で作成される「Shift-JIS」で作成されたファイルはもれなく文字化けするってことですね。

可能であるなら、バッチ処理で「UTF-8」でファイル作成ができれば万事良しということになるので調べてみたところ、
⇧ バッチで「chcp 65001」を指定すると「UTF-8」のファイルを作れるってネットの情報が多いので、試したところ自分の環境では何故か駄目でした。
何故に?って思って調べてたところ、
これらコードページのバッチファイル可否は、%SystemRoot%System32\C_コードページ.NLS の有無によるようです。
⇧ という情報があったので確認してみました。
自分の環境では、
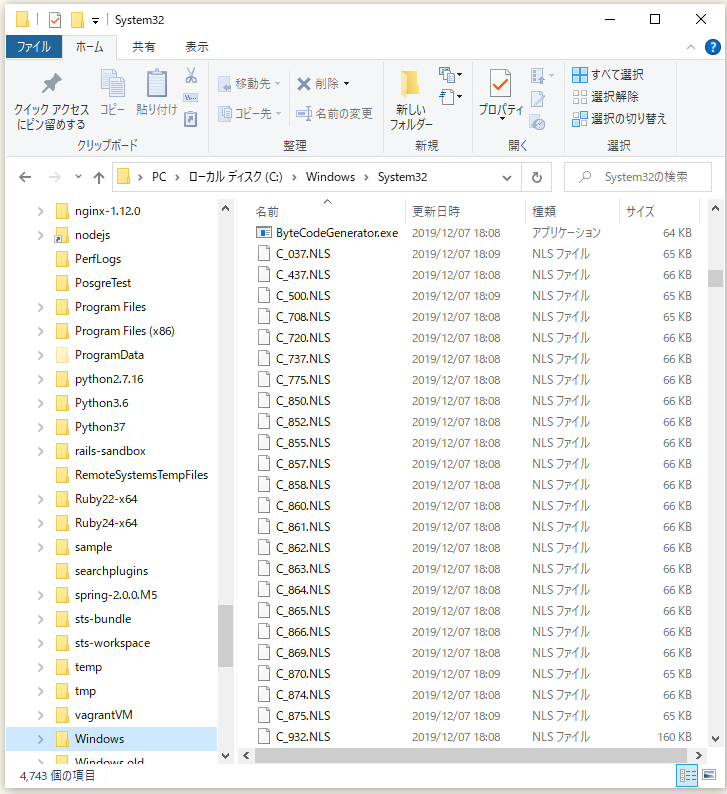
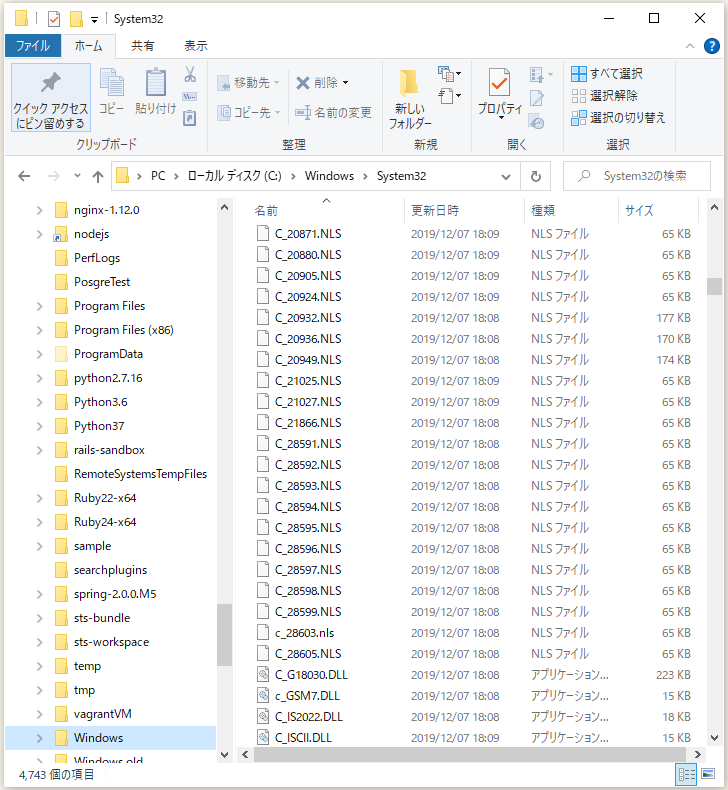
⇧ 確かに「UTF-8」に該当する「65001」の「.NLS」ファイルは見当たらず...
そもそも、「.NLS」ファイルって何なの?
C:\WINDOWS\system32 には、拡張子 .nls のファイルがたくさんあります。
特に目立つのは、c_[数字].nls という名前のファイルです。
これ、何かなと思って調べたところ、NT系OS(※)で多国語をサポートするNLS(National Language Support)が使用するファイルだそうです。
NT系OSでは、内部処理はUnicodeで行っているけれど、日本語の入出力は Shift-JIS なので、それを変換するためにこのファイルを変換テーブルとして使用するとのこと。
例えば、「あ」 はShift-JISで 0x82a0 なので、これを変換テーブルを参照して Unicodeの 0x3042 に変換して内部処理するということなのでしょう(文中の "0x" は、16進数の意味です)。
ちなみに、Shift-JIS は c_932.nls だそうです。
c_[数字].nls は、Microsoft 純正の外国語フォントをインストールした際に一緒にインストールされるようです。
インストールされたものは、以下のレジストリに値が保存されています。
HKLM\SYSTEM\CurrentControlSet\Control\Nls\CodePage
⇧「NLS」は「National Language Support」の略だそうです。
ここからは推測になってしまいますが、「Windows 10 Home」や「Windows 10 Pro」とかエディションによって「NLS」の構成が異なるんではないかと。
ちなみに私は「Windows 10 Home」です。
なので「Windows 10」であれば「Windows 10 Home」以外なら、「chcp 65001」をバッチで有効にしてファイル作成できるんではないでしょうか?
あと、
⇧ 大幅な変更があったみたいですね。
というわけで、Microsoft さんに闇が多いことがまた確認できた次第で、モヤモヤ感は募るばかりで、不信感もいや増すばかりですと...
今回はこのへんで。