
さまざまなプロジェクトで広く使われているJava製のログ出力ライブラリ「Apache Log4j」にリモートコード実行(RCE)のゼロデイ脆弱性が存在することが明らかになり、波紋が広がっています。
マイクラもハッキング ~「Apache Log4j」ライブラリに致命的なリモートコード実行のゼロデイ脆弱性【12月10日18:45追記】 - やじうまの杜 - 窓の杜
ニュースサイト「Cyber Kendra」によると、この脆弱性は11月24日にAlibaba Cloudのセキュリティチームによって報告されたとのこと。攻撃者が悪意のあるリクエストを送出すると、任意のコードがリモートから実行されてしまう可能性があります。
マイクラもハッキング ~「Apache Log4j」ライブラリに致命的なリモートコード実行のゼロデイ脆弱性【12月10日18:45追記】 - やじうまの杜 - 窓の杜
⇧ 脆弱性があるのは分かったんだけど、対策方法がTwitterの情報経由ってところに、Twitterのリアルタイム性の強さを感じますな。
Googleで上位表示されない哀しさよ...
⇧ 上記サイト様によりますと、「Apache Log4j」というプロジェクトに含まれる「Log4j 2」のバージョンを上げれば良いらしいのだけれど、バージョンアップできないような古いシステムだと緩和策でお茶を濁すしかないらしい...
「Apache」の「Logging Service」のサイトを確認したところ、
⇧ Java以外にも「Logging Service」のライブラリは用意されてるらしいのだけど、Java用だけに脆弱性が見つかったということなんかな?
「Kotlin」とか「Scala」なんかの「JVM言語」も影響を受けても良さそうな気がしなくもないのだけど。
で、「バージョンアップ」するにしても、
⇧ 上記サイト様の説明にあるように、「ビルドツール」によって対応方法も変わってきますと。
というか、内部的に「Apache Log4j」を利用してるライブラリとかあった場合、どうすれば良いのかね?
⇧ 上記サイト様によりますと、「JVM(Java Vertual Machine)」の起動オプションで確認できるそうな。
あとは、
⇧「脆弱性診断」のできる「ライブラリ」を利用できる場合は利用していく感じになるんかな?
「Spring Boot」を使っている場合も、
Our upcoming v2.5.8 & v2.6.2 releases (due Dec 23, 2021) will pickup Log4J v2.15.0, but since this is such a serious vulnerability you may want to override our dependency management and upgrade your Log4J2 dependency sooner.
https://spring.io/blog/2021/12/10/log4j2-vulnerability-and-spring-boot
⇧ 今すぐの対応としては「依存関係」で「log4j2」のバージョンを上げるしかないっぽいけど、「依存関係」のバージョンを上げた結果、現状正常稼働してたアプリケーションが動かなくなるとかなったら、お手上げという感じでしょうか...
バージョン間の互換性は考慮していただけると嬉しい気持ちでいっぱいな今日この頃です。
ただ、無償でライブラリの提供、メンテナンスなどしてくれてる方々の尽力に対しては、頭が下がりますな。
Log4j maintainers have been working sleeplessly on mitigation measures; fixes, docs, CVE, replies to inquiries, etc. Yet nothing is stopping people to bash us, for work we aren't paid for, for a feature we all dislike yet needed to keep due to backward compatibility concerns. https://t.co/W2u6AcBUM8
— Volkan Yazıcı (@yazicivo) 2021年12月10日
2021年12月13日(月)追記:↓ ここから
⇧ パッケージで「lombok.extern.log4j」とか含まれてたらから、てっきり、「Lombok」が内部的に「Log4j2」の「依存関係」を持っていると思ったんだけど、
⇧ 上記サイト様によりますと、「Lombok」とは別途、ログ系の「依存関係」を追加したものを「Lombok」は参照するらしい...
⇧ APIドキュメントからだと別途「依存関係」を追加する必要があるって情報は分かりませんな...
「Spring Boot」を使ってる場合は、
⇧「Log4j2」とかの「依存関係」が「Spring Boot」の「依存関係」に内蔵されてるっぽいから、「Spring Boot」の「依存関係」に含まれる「Log4j2」の「依存関係」のバージョンを確認する感じになるってことみたい...
このあたりの情報って、みんなどこから拾ってくるんだろう?
<properties> ... <log4j.version>1.2.16</log4j.version> ... </properties>
⇧ ってあったけど、「Quartz」内部で使われてる分には問題ないってことですかね?
Log4j 1.x系については、開発者により、Lookup機能が含まれておらず外部入力値由来のクラス情報がデシリアライズされないため影響を受けないという指摘がなされています。ただし、Log4j 1.x はすでに開発およびサポートが終了しているため、後継製品への移行を強く推奨します。
⇧ なるほど...
2021年12月13日(月)追記:↑ ここまで
というわけで、今回もJavaに関連する話題です。
レッツトライ~。
Quartzという名のライブラリ
一般的に「Quartz」って言うと、
石英(せきえい、独: Quarz、英: quartz、クォーツ、クオーツ)は、二酸化ケイ素 (SiO₂) が結晶してできた鉱物。六角柱状のきれいな自形結晶をなすことが多い。中でも特に無色透明なものを水晶(すいしょう、独: Bergkristall、英: rock crystal、ロッククリスタル)と呼び、古くは玻璃(はり)と呼ばれて珍重された。
石英を成分とする砂は珪砂(けいしゃ・けいさ、独: Quarzsand、英: quartz sand)と呼ばれ、石英を主体とした珪化物からなる鉱石は珪石と呼ぶ。この珪石のうち、チャートや珪質砂岩が熱による変成(接触変成作用)を受けた変成岩を珪岩(クォーツァイト)と呼ぶが、この珪岩の中にフクサイト(クロム白雲母)の微細な粒子を含み鮮やかな緑色を呈色し、砂金のようなキラキラした輝きを発するものは特に砂金石(アベンチュリン)と呼ばれている。
二酸化ケイ素 (SiO₂) が、低温で水分を含みゆっくり固まったために原子配列が規則正しくない非晶質のものがオパール(蛋白石)である。
二酸化ケイ素 (SiO₂) に富んだ流紋岩質の溶岩が急激に冷やされることで生じるのが、非晶質の天然ガラスである黒曜石(オブシディアン)である。
⇧ とあるように、科学的には「石」の1種ということで、「誕生石」なんかでも有名ですかね。
脱線しましたが、Javaのライブラリに「Quartz」という名のライブラリが存在しますと。
What is the Quartz Job Scheduling Library?
Quartz is a richly featured, open source job scheduling library that can be integrated within virtually any Java application - from the smallest stand-alone application to the largest e-commerce system. Quartz can be used to create simple or complex schedules for executing tens, hundreds, or even tens-of-thousands of jobs; jobs whose tasks are defined as standard Java components that may execute virtually anything you may program them to do. The Quartz Scheduler includes many enterprise-class features, such as support for JTA transactions and clustering.
https://github.com/quartz-scheduler/quartz/blob/master/docs/introduction.adoc
⇧「open source job scheduling library」ということで、「バッチ処理」に関するライブラリらしいですと。
ちなみに、手前味噌になりますが、
⇧ 上記の記事で、「バッチ処理」って何なのかについてまとめてます。
脱線しましたが、「Quartz」ライブラリのarchitectureの概要としては、

Let’s review each component from the bird’s eye view.
- Scheduler Factory – Scheduler factory is the one responsible to build the scheduler model, wire in all the dependent components, based on the contents of quartz properties file.
- Scheduler – This maintains a registry of job and trigger. It is also responsible for executing the job when their associated triggers fire.
- Scheduler Thread – This is the thread responsible for performing the work of firing trigger. It contacts the job store to get the next set of the triggers to be fired.
- Job – This is the interface that must be implemented by the task to be executed.
- Trigger – Triggers are the mechanism by which we schedule the jobs.They instruct the scheduler when the job should be fired.
- JobStore – This is the interface to be implemented by the classes that provide storage mechanism for job and trigger.
- ThreadPool – The job to be executed is passed the pool of threads represented by ThreadPool.
https://www.javarticles.com/2016/03/quartz-scheduler-model.html
⇧ 上図のような感じで、「Quartz Scheduler」が定義した「Job」が「ThreadPool」に常駐して、「Trigger」なんかで設定された時間になったら実行されるような仕組みなんだとは思うんですが、更に細かい粒度になると、

There are many more components which help configure and facilitate job execution, for example, the thread executor that decides how to execute the Quartz Scheduler Thread. The thread pool that manages the pool of threads to which the job is delegated for its execution, flavors of job store, one of which is in-memory based and the other is database specific.
Note that there can be more than one trigger pointing to the same job but a single trigger can only point to one job.
https://www.javarticles.com/2016/03/quartz-scheduler-model.html
⇧ 上図のような感じになり、説明文から、
という関係になるらしいので、同じ「Job」を複数の「Trigger」が利用することは可能だけど、「Job」を実行する際は、
じゃないと駄目ということみたい、つまり、1つの「Trigger」は複数の「Job」を実行することはできないということですかね。
QuartzでJobを永続化させるには?
「Quartz」ライブラリの公式の情報によると、
Job Persistence
-
The design of Quartz includes a JobStore interface that can be implemented to provide various mechanisms for the storage of jobs.
-
With the use of the included JDBCJobStore, all Jobs and Triggers configured as "non-volatile" are stored in a relational database via JDBC.
-
With the use of the included RAMJobStore, all Jobs and Triggers are stored in RAM and therefore do not persist between program executions - but this has the advantage of not requiring an external database.
https://github.com/quartz-scheduler/quartz/blob/master/docs/introduction.adoc
⇧ とあるように、「JobStore」というインターフェイスによって、「Job」に関わる情報を保持できる仕組みが用意されているらしく、
- JDBCJobStore
- RAMJobStore
の2つのタイプがあり、「JDBCJobStore」を利用する場合に「RDBMS(Relational Database Management System)」が必要ということで、事前に何かしらの「RDB(Relational DataBase)」をインストールしておく必要がありますと。
そして、利用する「RDB(Relational DataBase)」に合った「table_△△.sql」ファイルを、下記からダウンロードして実行して、「Quartz」ライブラリが利用するテーブルを作成しておく必要がありますと。
2021年12月18日(土)追記:↓ ここから
「Quartz」ライブラリが利用するテーブルについて、

⇧ 上記サイト様がまとめてくださってます。
まぁ、公式のドキュメントでまとめてくれてると、利用者にとっては非常にありがたいんですけど、残念ながら見当たらない...
2021年12月18日(土)追記:↑ ここまで
Quartzの設定など
「Quartz」ライブラリで「RDB(Relational DataBase)」を使って永続化を実現するには、「プロパティファイル」に設定が必要らしく、
Configuration of Quartz is typically done through the use of a properties file, in conjunction with the use of StdSchedulerFactory (which consumes the configuration file and instantiates a scheduler).
http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/configuration.html
By default, StdSchedulerFactory load a properties file named quartz.properties from the "current working directory". If that fails, then the quartz.properties file located (as a resource) in the org/quartz package is loaded. If you wish to use a file other than these defaults, you must define the system property org.quartz.properties to point to the file you want.
http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/configuration.html
⇧ 説明があるんですが、基本的には、「quartz.properties」という設定ファイルを用意してあげるということなんですが、設定ファイルの雛型っぽいものについては、PostgreSQLを使ってる場合は、
⇧ 上記のページのものを流用するのが手っ取り早そうではありますと。
spring-boot-starter-quartzとの関係は?
「Spring Boot」で「spring-boot-starter-quartz」という「依存関係」というものが用意されていて、手前味噌で恐縮ですが、
⇧ 上記で「spring-boot-starter-quartz」についても触れています。
で、公式の説明が
Spring Boot は、spring-boot-starter-quartz 「スターター」を含む、Quartz スケジューラー (英語) を操作するためのいくつかの便利な機能を提供します。Quartz が使用可能な場合、Scheduler は(SchedulerFactoryBean 抽象化により)自動構成されます。
https://spring.pleiades.io/spring-boot/docs/current/reference/html/features.html#features.quartz
⇧ という感じで、『いくつかの便利な機能を提供』とか、妙に曖昧な書きっぷりなんですが、「spring-boot-starter-quartz」で「Quartz」ライブラリを使う場合だと、
⇧「quartz.properties」で設定していた「Quartz」ライブラリでの設定をwww.baeldung.com
⇧「application.properties」にまとめられるらしいのですが、設定の記述が変わってますと。
ただ、
⇧「spring-boot-starter-quartz」を使っていても、「quartz.properties」で設定することも可能という感じで、「プロパティファイル」を分けた方が良いのかどうかがいまいちよく分からんですな...
あと、
⇧「SchedulerFactoryBean」クラスを継承したクラスを作成しておかないと、「Quartz」系のクラスが「Spring Boot」で認識されないっぽいのがハマりどころな気がしますかね...
PostgreSQLでqrtz_job_detailsテーブルのjob_dataカラムにbyteaとして保存される値は何なのか?
で、PostgreSQLを「RDB(Relational DataBase)」として利用して「Quartz」の「Job」を実行した場合、


⇧「qrtz_job_details」テーブルの「job_data」ってカラムに、「16進数」表記のバイナリデータが格納されるんですが、この値は、何なのか?
そもそもとして、qrtz_△△系のテーブルの用途を公式のドキュメントで説明して欲しい気がしてならないのだけど...
ちなみに「SchemaSpy」というツールで、qrtz_△△系のテーブルのリレーションを確認した感じでは、以下のようになってました。

脱線しましたが、公式のGitHubのコードを見た感じ、
⇧「JDBC(Java Database Connectivity)」で「データベース」に対してSELECT文を実行した結果の「ResultSet」から「qrtz_job_details」テーブルの「job_data」カラムの値を取得して、おそらく「デシリアライズ」とかしてるんだとは思うんだけど、このあたりの情報が少なくてよく分からんです...
で、試しに、
⇧ 上記サイト様を参考に、PostgreSQL側で値を確認してみることに。
ちなみに、「qrtz_job_details」テーブルの「job_data」カラムの素の値は、以下のキャプチャ画像のような感じ。

⇧「16進数(hexadecimal)」表記のバイナリデータということで、俗に言う「hex」というやつですかね。
それでは、「encode」関数を使ってみます。
SELECT trim(trailing from encode([カラム名],'escape')) FROM [テーブル名];

\254\355\000\x05sr\000\x15org.quartz.JobDataMap\237\260\203\350\277\251\260\313\x02\000\000xr\000&org.quartz.utils.StringKeyDirtyFlagMap\202\x08\350\303\373\305](\x02\000\x01Z\000\x13allowsTransientDataxr\000\x1Dorg.quartz.utils.DirtyFlagMap\x13\346.\255(v+ \316\x02\000\x02Z\000\x05dirtyL\000\x03mapt\000\x0FLjava/util/Map;xp\000sr\000\x11java.util.HashMap\x05\x07\332\301\303\x16`\321\x03\000\x02F\000 + loadFactorI\000 thresholdxp?@\000\000\000\000\000\x10w\x08\000\000\000\x10\000\000\000\000x\000
⇧ なかなかにカオスな状態が返ってきたんだけど、なんとなく、Javaのオブジェクトを「シリアライズ」していた値が格納されていたんであろうな的な雰囲気が感じられるんですが、如何せん、PostgreSQLの関数だと何か「デシリアライズ」されきってない結果になってますと。
というのも、
Serializing is about moving structured data over a storage/transmission medium in a way that the structure can be maintained. Encoding is more broad, like about how said data is converted to different forms, etc. Perhaps you could think about serializing being a subset of encoding in this example.
https://stackoverflow.com/questions/3784143/what-is-the-difference-between-serializing-and-encoding
⇧ ということらしいのと、PostgreSQLの
encode ( bytes bytea, format text ) → text
バイナリデータをテキスト表現形式に符号化します。サポートされているformat値は、base64、escape、hexです。
https://www.postgresql.jp/document/13/html/functions-binarystring.html
decode ( string text, format text ) → bytea
decode ( string text, format text ) → byteaテキスト表現からバイナリデータに復号します。 format値はencodeと同じです。
https://www.postgresql.jp/document/13/html/functions-binarystring.html
⇧ という説明から、あくまで、PostgreSQLの「encode」「decode」関数は、「バイナリ」と「テキスト」間の変換をするだけであって、細かなデータ構造までは考慮していないってことなんですかね?
ちなみに、「base64」「hex」でそれぞれ、「encode」関数を使った結果は以下のキャプチャ画像。


⇧ 何て言うか、「hex」の場合は、素の状態のデータの先頭に付いてた「\x」が取れたということで、
「hex」書式ではバイナリデータの各バイトを上位4ビット、下位4ビットの順で2桁の16進数に符号化します。 (エスケープ書式と区別するために)文字列全体は\xという並びの後に付けられます。
https://www.postgresql.jp/document/13/html/datatype-binary.html
⇧ と説明があるので、「encode」関数を「hex」で実行すると、「16進数」表記のバイナリデータが、「16進数」表記の文字列になるってことなんかな?
で話を元に戻すと、
⇧ Java側で「シリアライズ」する前のオブジェクトのクラスが分からないと無理らしいってことなのかね...いやはや、バイナリのデータは闇が深いですな...
ただ、Eclipseで「Spring Boot」プロジェクトを作って、素の「JDBC」で「qrtz_job_details」テーブルの「job_data」カラムの値を取得して、「デバッグ」実行して中身を確認するために、上記の方法で「デシリアライズ」してみたところ、空の「JobDataMap」オブジェクトだったというね...
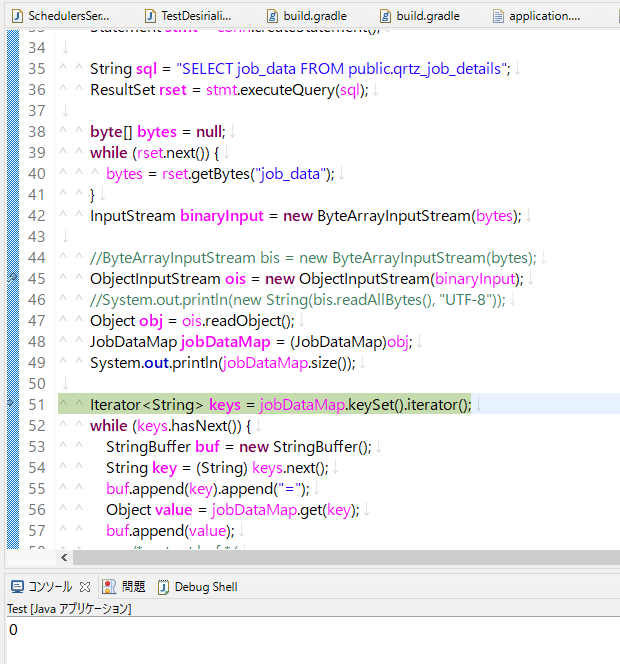
で、
Jobにパラメータを渡したり、Jobの実行間でのステータスを保持する役割を持つ「JobDataMap」というものがJobDetailの一部機能として提供されています。
Quartz Scheduler:JobDetailの役割とJobライフサイクルについて - omotenashi-mind
実行対象ジョブにパラメータを受け渡したい場合はJobBuilderの「usingJobData()」メソッドを利用します。
Quartz Scheduler:JobDetailの役割とJobライフサイクルについて - omotenashi-mind
⇧ 上記サイト様によりますと、明示的に、「usingJobData()」メソッドを利用しない限り、「job_data」カラムに格納されるのは空の「JobDataMap」ということらしい、たぶん...。
The JobDataMap can be used to hold any amount of (serializable) data objects which you wish to have made available to the job instance when it executes. JobDataMap is an implementation of the Java Map interface, and has some added convenience methods for storing and retrieving data of primitive types.
http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/tutorials/tutorial-lesson-03.html
⇧ という感じで、「Job」の実行時に何かしら値を渡したい場合は、「JobDetail」インスタンスを生成する際に設定するということらしく、その時に何かしら値を設定することで、初めて「JobDataMap」が空ではなくなるらしい、たぶん...。
というわけで、
⇧ 上記の記事で、試してたいた「Quartz」のコードを以下のように、「usingJobData()」メソッドを使うようにして実行した後に、
package com.example.demo.batch.service.impl;
import java.util.TimeZone;
import org.quartz.CronScheduleBuilder;
import org.quartz.CronTrigger;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.TriggerBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import org.springframework.stereotype.Service;
import com.example.demo.batch.job.UserJob;
import com.example.demo.batch.service.SchedulerService;
@Service
public class SchedulersServiceImpl implements SchedulerService {
@Autowired
private SchedulerFactoryBean schedulerFactoryBean;
@Override
public void startAllSchedulers() {
//
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobDetail jobDetail = JobBuilder.newJob(UserJob.class)
.withIdentity("userJob", "jobGroup1")
.usingJobData("jobSays", "Hello World!")
.storeDurably(true)
.build();
CronTrigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("cronTrigger1", "triggerGroup1")
.withSchedule(
CronScheduleBuilder.cronSchedule("*/1 * * * * ?")
.inTimeZone(TimeZone.getTimeZone("Asia/Tokyo")))
.startNow().build();
try {
// org.quartz.ObjectAlreadyExistsExceptionの例外を回避する
if (scheduler.checkExists(jobDetail.getKey())){
scheduler.deleteJob(jobDetail.getKey());
}
scheduler.scheduleJob(jobDetail, trigger);
} catch (SchedulerException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
}
}
}
「qrtz_job_details」テーブルの「job_data」カラムの値を「デシリアライズ」してみたところ、

⇧「usingJobData()」メソッドで設定した「key」「value」が追加されてるようです。
「usingJobData()」メソッドを使わないと「JobDataMap」に値が設定されないなら、コーディングで必ず設定する必要があるってことで、実行時に参照する「JobDataMap」の値って、「qrtz_job_details」テーブルの「job_data」カラムの値を参照していないような気がするんだけど、いまいち「Quartz」の内部的な挙動が分からんから何とも言えないという...
何て言うか、公式のドキュメントの情報が掴み辛いのがしんどいですわ...全部、憶測になってしまうからね...
ちなみに「Quartz」のAPIドキュメントで「org.quartz.jobDataMap」を確認したところ、
public class JobDataMapextends StringKeyDirtyFlagMapimplements Serializable
https://www.quartz-scheduler.org/api/2.1.7/org/quartz/JobDataMap.html
Holds state information forJobinstances.JobDataMapinstances are stored once when theJobis added to a scheduler. They are also re-persisted after every execution ofStatefulJobinstances.
https://www.quartz-scheduler.org/api/2.1.7/org/quartz/JobDataMap.html
JobDataMapinstances can also be stored with aTrigger. This can be useful in the case where you have a Job that is stored in the scheduler for regular/repeated use by multiple Triggers, yet with each independent triggering, you want to supply the Job with different data inputs.
https://www.quartz-scheduler.org/api/2.1.7/org/quartz/JobDataMap.html
TheJobExecutionContextpassed to a Job at execution time also contains a convenienceJobDataMapthat is the result of merging the contents of the trigger's JobDataMap (if any) over the Job's JobDataMap (if any).
https://www.quartz-scheduler.org/api/2.1.7/org/quartz/JobDataMap.html
⇧ なんか、実行の度に「JobDataMap」が再永続化されるってことなんかな?
serialVersionUID
この定数は、復元前後でクラスのバージョンが異なっていないかを識別する為のものらしい。
なので、クラス内のフィールドやメソッド(の名前や型)に変更があった場合は 計算し直すのが筋だと思われる。
が、「変更されない」あるいは「実際には受け渡しは行わない」という割り切りで常に固定値(1とか)を指定しておく手もないわけではない。
⇧ 上記サイト様によりますと、「serialVersionUID」ある場合は、クラスに変更があった場合かどうかを確認するものらしいので、「org.quartz.JobDataMap」にもあるのか確認してみたところ、「serialVersionUID」が定数として定義されてました。

ドキュメントに掲載されてる「serialVersionUID」の値とも一致してました。
ただ、「org.quartz.JobDataMap」に利用者が手を加えることは無いと思うので、「ライブラリ」のバージョンが上がった時に、何かしら改修が加わったら、「org.quartz.JobDataMap」が「シリアライズ」される時の値も変わると思うので、「qrtz_job_details」テーブルの「job_data」カラムに格納される値も変わるってことですかね。
2021年12月14日(火)追記:↓ ここから
なんか、
The 'job_data' field is a BLOB object that's used to serialize the 'jobDataMap' (java.util.Map) associated with the JobDetail. In order to populate this field, you'll obviously have to write some JDBC code.
http://mmmsoftware.blogspot.com/2008/12/integrating-quartz-and-spring-using.html
⇧ って言ってる人もおれば、
Create tables, SQL statements can be found in the quartz-1.6.6\docs\dbTables folder, introduce the main tables:table qrtz_job_details: save job details, this table requires the user to initialize job_name: job in the cluster according to the actual situation The name, the name of the user can be customized at will, no mandatory requirement job_group: the name of the group to which the job in the cluster belongs, the name user can be customized at will, no mandatory requirement job_class_name: the complete package name of the note job implementation class in the cluster, quartz It is based on this path to the classpath to find the job class is_durable: whether it is persistent, set this attribute to 1, quartz will persist the job to the database job_data: a blob field, store the persistent job object table qrtz_triggers: save trigger information trigger_name : trigger name, the name of the user that they can be customized without forcing trigger_group: name of the trigger belongs to the group, the name of the user himself free to customize, without forcing job_name: foreign key qrtz_job_details table job_name the foreign key qrtz_job_details table job_group of: job_group trigger_state: current trigger state, set to ACQUIRED, if set WAITING, then the job will not trigger trigger_cron: trigger type, use cron expression table qrtz_cron_triggers: cron expression table storage
https://titanwolf.org/Network/Articles/Article?AID=6ca7f74a-8c6a-4044-b0b8-982046813dde
⇧ って言ってる人もおって、結局のところ、「qrtz_job_details」テーブルの「job_data」カラムにどんなデータが入るのかがさっぱり分からんというね...
そもそもとして、「job object」ってのが何を指してるかがいまいち判然としないのが困ったもんですな...
「JobDataMap」以外のデータも入り得るって考えといた方が良いんかな?
何と言っても、「Quartz」の用意している「qrtz_job_details」テーブルの「job_data」カラムには「バイナリデータ」なら何でも入れられちゃうこともあり、適当なデータを入れられてたとした場合、どんなデータなのか確認しようにも、PostgreSQLのencode関数だと、完全に「デシリアライズ」できないっぽいし、Java側で「デシリアライズ」ができる保証もないし(『「java.io.StreamCorruptedException: invalid stream header:」』とか起きる問題)、こういう時にドキュメントでどんなデータが入り得るかってのを明示してくれていると助かるんですけどね...
2021年12月14日(火)追記:↑ ここまで
2022年2月13日(日)追記:↓ ここから
「spring-boot-autoconfigure」の依存関係を追加すれば、「SchedulerFactoryBean」クラスを継承したクラスを作成しなくてもQuartzの機能を使えました。
⇧ 手前味噌で恐縮ですが、上記の記事でまとめております。
それにしても、「spring-boot-autoconfigure」を依存関係に追加してQuartzを使ってる情報がネットで皆無だったのが気になりますな...
2022年2月13日(日)追記:↑ ここまで
毎回モヤモヤ感が半端ない...
今回はこのへんで。